Get trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation
In unsupervised domain adaptation (UDA), a model trained on source data (e.g. synthetic) is adapted to target data (e.g. real-world) without access to target annotation. Most previous UDA methods struggle with classes that have a similar visual appearance on the target domain as no ground truth is available to learn the slight appearance differences. To address this problem, we propose a Masked Image Consistency (MIC) module to enhance UDA by learning spatial context relations of the target domain as additional clues for robust visual recognition. MIC enforces the consistency between predictions of masked target images, where random patches are withheld, and pseudo-labels that are generated based on the complete image by an exponential moving average teacher. To minimize the consistency loss, the network has to learn to infer the predictions of the masked regions from their context. Due to its simple and universal concept, MIC can be integrated into various UDA methods across different visual recognition tasks such as image classification, semantic segmentation, and object detection. MIC significantly improves the state-of-the-art performance across the different recognition tasks for synthetic-to-real, day-to-nighttime, and clear-to-adverse-weather UDA. For instance, MIC achieves an unprecedented UDA performance of 75.9 mIoU and 92.8% on GTA-to-Cityscapes and VisDA-2017, respectively, which corresponds to an improvement of +2.1 and +3.0 percent points over the previous state of the art. The implementation is available at https://github.com/lhoyer/MIC.
SRMA-Mamba: Spatial Reverse Mamba Attention Network for Pathological Liver Segmentation in MRI Volumes
Liver Cirrhosis plays a critical role in the prognosis of chronic liver disease. Early detection and timely intervention are critical in significantly reducing mortality rates. However, the intricate anatomical architecture and diverse pathological changes of liver tissue complicate the accurate detection and characterization of lesions in clinical settings. Existing methods underutilize the spatial anatomical details in volumetric MRI data, thereby hindering their clinical effectiveness and explainability. To address this challenge, we introduce a novel Mamba-based network, SRMA-Mamba, designed to model the spatial relationships within the complex anatomical structures of MRI volumes. By integrating the Spatial Anatomy-Based Mamba module (SABMamba), SRMA-Mamba performs selective Mamba scans within liver cirrhotic tissues and combines anatomical information from the sagittal, coronal, and axial planes to construct a global spatial context representation, enabling efficient volumetric segmentation of pathological liver structures. Furthermore, we introduce the Spatial Reverse Attention module (SRMA), designed to progressively refine cirrhotic details in the segmentation map, utilizing both the coarse segmentation map and hierarchical encoding features. Extensive experiments demonstrate that SRMA-Mamba surpasses state-of-the-art methods, delivering exceptional performance in 3D pathological liver segmentation. Our code is available for public: https://github.com/JunZengz/SRMA-Mamba.
Learning to Aggregate Multi-Scale Context for Instance Segmentation in Remote Sensing Images
The task of instance segmentation in remote sensing images, aiming at performing per-pixel labeling of objects at instance level, is of great importance for various civil applications. Despite previous successes, most existing instance segmentation methods designed for natural images encounter sharp performance degradations when they are directly applied to top-view remote sensing images. Through careful analysis, we observe that the challenges mainly come from the lack of discriminative object features due to severe scale variations, low contrasts, and clustered distributions. In order to address these problems, a novel context aggregation network (CATNet) is proposed to improve the feature extraction process. The proposed model exploits three lightweight plug-and-play modules, namely dense feature pyramid network (DenseFPN), spatial context pyramid (SCP), and hierarchical region of interest extractor (HRoIE), to aggregate global visual context at feature, spatial, and instance domains, respectively. DenseFPN is a multi-scale feature propagation module that establishes more flexible information flows by adopting inter-level residual connections, cross-level dense connections, and feature re-weighting strategy. Leveraging the attention mechanism, SCP further augments the features by aggregating global spatial context into local regions. For each instance, HRoIE adaptively generates RoI features for different downstream tasks. Extensive evaluations of the proposed scheme on iSAID, DIOR, NWPU VHR-10, and HRSID datasets demonstrate that the proposed approach outperforms state-of-the-arts under similar computational costs. Source code and pre-trained models are available at https://github.com/yeliudev/CATNet.

SARA: Controllable Makeup Transfer with Spatial Alignment and Region-Adaptive Normalization
Makeup transfer is a process of transferring the makeup style from a reference image to the source images, while preserving the source images' identities. This technique is highly desirable and finds many applications. However, existing methods lack fine-level control of the makeup style, making it challenging to achieve high-quality results when dealing with large spatial misalignments. To address this problem, we propose a novel Spatial Alignment and Region-Adaptive normalization method (SARA) in this paper. Our method generates detailed makeup transfer results that can handle large spatial misalignments and achieve part-specific and shade-controllable makeup transfer. Specifically, SARA comprises three modules: Firstly, a spatial alignment module that preserves the spatial context of makeup and provides a target semantic map for guiding the shape-independent style codes. Secondly, a region-adaptive normalization module that decouples shape and makeup style using per-region encoding and normalization, which facilitates the elimination of spatial misalignments. Lastly, a makeup fusion module blends identity features and makeup style by injecting learned scale and bias parameters. Experimental results show that our SARA method outperforms existing methods and achieves state-of-the-art performance on two public datasets.
Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting
In this paper, we propose two modified neural networks based on dual path multi-scale fusion networks (SFANet) and SegNet for accurate and efficient crowd counting. Inspired by SFANet, the first model, which is named M-SFANet, is attached with atrous spatial pyramid pooling (ASPP) and context-aware module (CAN). The encoder of M-SFANet is enhanced with ASPP containing parallel atrous convolutional layers with different sampling rates and hence able to extract multi-scale features of the target object and incorporate larger context. To further deal with scale variation throughout an input image, we leverage the CAN module which adaptively encodes the scales of the contextual information. The combination yields an effective model for counting in both dense and sparse crowd scenes. Based on the SFANet decoder structure, M-SFANet's decoder has dual paths, for density map and attention map generation. The second model is called M-SegNet, which is produced by replacing the bilinear upsampling in SFANet with max unpooling that is used in SegNet. This change provides a faster model while providing competitive counting performance. Designed for high-speed surveillance applications, M-SegNet has no additional multi-scale-aware module in order to not increase the complexity. Both models are encoder-decoder based architectures and are end-to-end trainable. We conduct extensive experiments on five crowd counting datasets and one vehicle counting dataset to show that these modifications yield algorithms that could improve state-of-the-art crowd counting methods. Codes are available at https://github.com/Pongpisit-Thanasutives/Variations-of-SFANet-for-Crowd-Counting.
Global Context Vision Transformers
We propose global context vision transformer (GC ViT), a novel architecture that enhances parameter and compute utilization for computer vision tasks. The core of the novel model are global context self-attention modules, joint with standard local self-attention, to effectively yet efficiently model both long and short-range spatial interactions, as an alternative to complex operations such as an attention masks or local windows shifting. While the local self-attention modules are responsible for modeling short-range information, the global query tokens are shared across all global self-attention modules to interact with local key and values. In addition, we address the lack of inductive bias in ViTs and improve the modeling of inter-channel dependencies by proposing a novel downsampler which leverages a parameter-efficient fused inverted residual block. The proposed GC ViT achieves new state-of-the-art performance across image classification, object detection and semantic segmentation tasks. On ImageNet-1K dataset for classification, GC ViT models with 51M, 90M and 201M parameters achieve 84.3%, 84.9% and 85.6% Top-1 accuracy, respectively, surpassing comparably-sized prior art such as CNN-based ConvNeXt and ViT-based Swin Transformer. Pre-trained GC ViT backbones in downstream tasks of object detection, instance segmentation, and semantic segmentation on MS COCO and ADE20K datasets outperform prior work consistently, sometimes by large margins.



Crane: Context-Guided Prompt Learning and Attention Refinement for Zero-Shot Anomaly Detection
Anomaly Detection involves identifying deviations from normal data distributions and is critical in fields such as medical diagnostics and industrial defect detection. Traditional AD methods typically require the availability of normal training samples; however, this assumption is not always feasible. Recently, the rich pretraining knowledge of CLIP has shown promising zero-shot generalization in detecting anomalies without the need for training samples from target domains. However, CLIP's coarse-grained image-text alignment limits localization and detection performance for fine-grained anomalies due to: (1) spatial misalignment, and (2) the limited sensitivity of global features to local anomalous patterns. In this paper, we propose Crane which tackles both problems. First, we introduce a correlation-based attention module to retain spatial alignment more accurately. Second, to boost the model's awareness of fine-grained anomalies, we condition the learnable prompts of the text encoder on image context extracted from the vision encoder and perform a local-to-global representation fusion. Moreover, our method can incorporate vision foundation models such as DINOv2 to further enhance spatial understanding and localization. The key insight of Crane is to balance learnable adaptations for modeling anomalous concepts with non-learnable adaptations that preserve and exploit generalized pretrained knowledge, thereby minimizing in-domain overfitting and maximizing performance on unseen domains. Extensive evaluation across 14 diverse industrial and medical datasets demonstrates that Crane consistently improves the state-of-the-art ZSAD from 2% to 28%, at both image and pixel levels, while remaining competitive in inference speed. The code is available at https://github.com/AlirezaSalehy/Crane.

FSATFusion: Frequency-Spatial Attention Transformer for Infrared and Visible Image Fusion
The infrared and visible images fusion (IVIF) is receiving increasing attention from both the research community and industry due to its excellent results in downstream applications. Existing deep learning approaches often utilize convolutional neural networks to extract image features. However, the inherently capacity of convolution operations to capture global context can lead to information loss, thereby restricting fusion performance. To address this limitation, we propose an end-to-end fusion network named the Frequency-Spatial Attention Transformer Fusion Network (FSATFusion). The FSATFusion contains a frequency-spatial attention Transformer (FSAT) module designed to effectively capture discriminate features from source images. This FSAT module includes a frequency-spatial attention mechanism (FSAM) capable of extracting significant features from feature maps. Additionally, we propose an improved Transformer module (ITM) to enhance the ability to extract global context information of vanilla Transformer. We conducted both qualitative and quantitative comparative experiments, demonstrating the superior fusion quality and efficiency of FSATFusion compared to other state-of-the-art methods. Furthermore, our network was tested on two additional tasks without any modifications, to verify the excellent generalization capability of FSATFusion. Finally, the object detection experiment demonstrated the superiority of FSATFusion in downstream visual tasks. Our code is available at https://github.com/Lmmh058/FSATFusion.
CRASH: Crash Recognition and Anticipation System Harnessing with Context-Aware and Temporal Focus Attentions
Accurately and promptly predicting accidents among surrounding traffic agents from camera footage is crucial for the safety of autonomous vehicles (AVs). This task presents substantial challenges stemming from the unpredictable nature of traffic accidents, their long-tail distribution, the intricacies of traffic scene dynamics, and the inherently constrained field of vision of onboard cameras. To address these challenges, this study introduces a novel accident anticipation framework for AVs, termed CRASH. It seamlessly integrates five components: object detector, feature extractor, object-aware module, context-aware module, and multi-layer fusion. Specifically, we develop the object-aware module to prioritize high-risk objects in complex and ambiguous environments by calculating the spatial-temporal relationships between traffic agents. In parallel, the context-aware is also devised to extend global visual information from the temporal to the frequency domain using the Fast Fourier Transform (FFT) and capture fine-grained visual features of potential objects and broader context cues within traffic scenes. To capture a wider range of visual cues, we further propose a multi-layer fusion that dynamically computes the temporal dependencies between different scenes and iteratively updates the correlations between different visual features for accurate and timely accident prediction. Evaluated on real-world datasets--Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D) datasets--our model surpasses existing top baselines in critical evaluation metrics like Average Precision (AP) and mean Time-To-Accident (mTTA). Importantly, its robustness and adaptability are particularly evident in challenging driving scenarios with missing or limited training data, demonstrating significant potential for application in real-world autonomous driving systems.

Dual Attribute-Spatial Relation Alignment for 3D Visual Grounding
3D visual grounding is an emerging research area dedicated to making connections between the 3D physical world and natural language, which is crucial for achieving embodied intelligence. In this paper, we propose DASANet, a Dual Attribute-Spatial relation Alignment Network that separately models and aligns object attributes and spatial relation features between language and 3D vision modalities. We decompose both the language and 3D point cloud input into two separate parts and design a dual-branch attention module to separately model the decomposed inputs while preserving global context in attribute-spatial feature fusion by cross attentions. Our DASANet achieves the highest grounding accuracy 65.1% on the Nr3D dataset, 1.3% higher than the best competitor. Besides, the visualization of the two branches proves that our method is efficient and highly interpretable.
PIRC Net : Using Proposal Indexing, Relationships and Context for Phrase Grounding
Phrase Grounding aims to detect and localize objects in images that are referred to and are queried by natural language phrases. Phrase grounding finds applications in tasks such as Visual Dialog, Visual Search and Image-text co-reference resolution. In this paper, we present a framework that leverages information such as phrase category, relationships among neighboring phrases in a sentence and context to improve the performance of phrase grounding systems. We propose three modules: Proposal Indexing Network(PIN); Inter-phrase Regression Network(IRN) and Proposal Ranking Network(PRN) each of which analyze the region proposals of an image at increasing levels of detail by incorporating the above information. Also, in the absence of ground-truth spatial locations of the phrases(weakly-supervised), we propose knowledge transfer mechanisms that leverages the framework of PIN module. We demonstrate the effectiveness of our approach on the Flickr 30k Entities and ReferItGame datasets, for which we achieve improvements over state-of-the-art approaches in both supervised and weakly-supervised variants.
Pyramid Stereo Matching Network
Recent work has shown that depth estimation from a stereo pair of images can be formulated as a supervised learning task to be resolved with convolutional neural networks (CNNs). However, current architectures rely on patch-based Siamese networks, lacking the means to exploit context information for finding correspondence in illposed regions. To tackle this problem, we propose PSMNet, a pyramid stereo matching network consisting of two main modules: spatial pyramid pooling and 3D CNN. The spatial pyramid pooling module takes advantage of the capacity of global context information by aggregating context in different scales and locations to form a cost volume. The 3D CNN learns to regularize cost volume using stacked multiple hourglass networks in conjunction with intermediate supervision. The proposed approach was evaluated on several benchmark datasets. Our method ranked first in the KITTI 2012 and 2015 leaderboards before March 18, 2018. The codes of PSMNet are available at: https://github.com/JiaRenChang/PSMNet.
Flash-VStream: Efficient Real-Time Understanding for Long Video Streams
Benefiting from the advances in large language models and cross-modal alignment, existing multimodal large language models have achieved prominent performance in image and short video understanding. However, the understanding of long videos is still challenging, as their long-context nature results in significant computational and memory overhead. Most existing work treats long videos in the same way as short videos, which is inefficient for real-world applications and hard to generalize to even longer videos. To address these issues, we propose Flash-VStream, an efficient video language model capable of processing extremely long videos and responding to user queries in real time. Particularly, we design a Flash Memory module, containing a low-capacity context memory to aggregate long-context temporal information and model the distribution of information density, and a high-capacity augmentation memory to retrieve detailed spatial information based on this distribution. Compared to existing models, Flash-VStream achieves significant reductions in inference latency. Extensive experiments on long video benchmarks and comprehensive video benchmarks, i.e., EgoSchema, MLVU, LVBench, MVBench and Video-MME, demonstrate the state-of-the-art performance and outstanding efficiency of our method. Code is available at https://github.com/IVGSZ/Flash-VStream.

Rethinking Atrous Convolution for Semantic Image Segmentation
In this work, we revisit atrous convolution, a powerful tool to explicitly adjust filter's field-of-view as well as control the resolution of feature responses computed by Deep Convolutional Neural Networks, in the application of semantic image segmentation. To handle the problem of segmenting objects at multiple scales, we design modules which employ atrous convolution in cascade or in parallel to capture multi-scale context by adopting multiple atrous rates. Furthermore, we propose to augment our previously proposed Atrous Spatial Pyramid Pooling module, which probes convolutional features at multiple scales, with image-level features encoding global context and further boost performance. We also elaborate on implementation details and share our experience on training our system. The proposed `DeepLabv3' system significantly improves over our previous DeepLab versions without DenseCRF post-processing and attains comparable performance with other state-of-art models on the PASCAL VOC 2012 semantic image segmentation benchmark.
X-Dyna: Expressive Dynamic Human Image Animation
We introduce X-Dyna, a novel zero-shot, diffusion-based pipeline for animating a single human image using facial expressions and body movements derived from a driving video, that generates realistic, context-aware dynamics for both the subject and the surrounding environment. Building on prior approaches centered on human pose control, X-Dyna addresses key shortcomings causing the loss of dynamic details, enhancing the lifelike qualities of human video animations. At the core of our approach is the Dynamics-Adapter, a lightweight module that effectively integrates reference appearance context into the spatial attentions of the diffusion backbone while preserving the capacity of motion modules in synthesizing fluid and intricate dynamic details. Beyond body pose control, we connect a local control module with our model to capture identity-disentangled facial expressions, facilitating accurate expression transfer for enhanced realism in animated scenes. Together, these components form a unified framework capable of learning physical human motion and natural scene dynamics from a diverse blend of human and scene videos. Comprehensive qualitative and quantitative evaluations demonstrate that X-Dyna outperforms state-of-the-art methods, creating highly lifelike and expressive animations. The code is available at https://github.com/bytedance/X-Dyna.





SMAUG: Sparse Masked Autoencoder for Efficient Video-Language Pre-training
Video-language pre-training is crucial for learning powerful multi-modal representation. However, it typically requires a massive amount of computation. In this paper, we develop SMAUG, an efficient pre-training framework for video-language models. The foundation component in SMAUG is masked autoencoders. Different from prior works which only mask textual inputs, our masking strategy considers both visual and textual modalities, providing a better cross-modal alignment and saving more pre-training costs. On top of that, we introduce a space-time token sparsification module, which leverages context information to further select only "important" spatial regions and temporal frames for pre-training. Coupling all these designs allows our method to enjoy both competitive performances on text-to-video retrieval and video question answering tasks, and much less pre-training costs by 1.9X or more. For example, our SMAUG only needs about 50 NVIDIA A6000 GPU hours for pre-training to attain competitive performances on these two video-language tasks across six popular benchmarks.


Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
Recovering the 3D scene geometry from a single view is a fundamental yet ill-posed problem in computer vision. While classical depth estimation methods infer only a 2.5D scene representation limited to the image plane, recent approaches based on radiance fields reconstruct a full 3D representation. However, these methods still struggle with occluded regions since inferring geometry without visual observation requires (i) semantic knowledge of the surroundings, and (ii) reasoning about spatial context. We propose KYN, a novel method for single-view scene reconstruction that reasons about semantic and spatial context to predict each point's density. We introduce a vision-language modulation module to enrich point features with fine-grained semantic information. We aggregate point representations across the scene through a language-guided spatial attention mechanism to yield per-point density predictions aware of the 3D semantic context. We show that KYN improves 3D shape recovery compared to predicting density for each 3D point in isolation. We achieve state-of-the-art results in scene and object reconstruction on KITTI-360, and show improved zero-shot generalization compared to prior work. Project page: https://ruili3.github.io/kyn.


Agentic 3D Scene Generation with Spatially Contextualized VLMs
Despite recent advances in multimodal content generation enabled by vision-language models (VLMs), their ability to reason about and generate structured 3D scenes remains largely underexplored. This limitation constrains their utility in spatially grounded tasks such as embodied AI, immersive simulations, and interactive 3D applications. We introduce a new paradigm that enables VLMs to generate, understand, and edit complex 3D environments by injecting a continually evolving spatial context. Constructed from multimodal input, this context consists of three components: a scene portrait that provides a high-level semantic blueprint, a semantically labeled point cloud capturing object-level geometry, and a scene hypergraph that encodes rich spatial relationships, including unary, binary, and higher-order constraints. Together, these components provide the VLM with a structured, geometry-aware working memory that integrates its inherent multimodal reasoning capabilities with structured 3D understanding for effective spatial reasoning. Building on this foundation, we develop an agentic 3D scene generation pipeline in which the VLM iteratively reads from and updates the spatial context. The pipeline features high-quality asset generation with geometric restoration, environment setup with automatic verification, and ergonomic adjustment guided by the scene hypergraph. Experiments show that our framework can handle diverse and challenging inputs, achieving a level of generalization not observed in prior work. Further results demonstrate that injecting spatial context enables VLMs to perform downstream tasks such as interactive scene editing and path planning, suggesting strong potential for spatially intelligent systems in computer graphics, 3D vision, and embodied applications.

Geography-Aware Large Language Models for Next POI Recommendation
The next Point-of-Interest (POI) recommendation task aims to predict users' next destinations based on their historical movement data and plays a key role in location-based services and personalized applications. Accurate next POI recommendation depends on effectively modeling geographic information and POI transition relations, which are crucial for capturing spatial dependencies and user movement patterns. While Large Language Models (LLMs) exhibit strong capabilities in semantic understanding and contextual reasoning, applying them to spatial tasks like next POI recommendation remains challenging. First, the infrequent nature of specific GPS coordinates makes it difficult for LLMs to model precise spatial contexts. Second, the lack of knowledge about POI transitions limits their ability to capture potential POI-POI relationships. To address these issues, we propose GA-LLM (Geography-Aware Large Language Model), a novel framework that enhances LLMs with two specialized components. The Geographic Coordinate Injection Module (GCIM) transforms GPS coordinates into spatial representations using hierarchical and Fourier-based positional encoding, enabling the model to understand geographic features from multiple perspectives. The POI Alignment Module (PAM) incorporates POI transition relations into the LLM's semantic space, allowing it to infer global POI relationships and generalize to unseen POIs. Experiments on three real-world datasets demonstrate the state-of-the-art performance of GA-LLM.
ConTextual: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models
Recent advancements in AI have led to the development of large multimodal models (LMMs) capable of processing complex tasks involving joint reasoning over text and visual content in the image (e.g., navigating maps in public places). This paper introduces ConTextual, a novel benchmark comprising instructions designed explicitly to evaluate LMMs' ability to perform context-sensitive text-rich visual reasoning. ConTextual emphasizes diverse real-world scenarios (e.g., time-reading, navigation, shopping and more) demanding a deeper understanding of the interactions between textual and visual elements. Our findings reveal a significant performance gap of 30.8% between the best-performing LMM, GPT-4V(ision), and human capabilities using human evaluation indicating substantial room for improvement in context-sensitive text-rich visual reasoning. Notably, while GPT-4V excelled in abstract categories like meme and quote interpretation, its overall performance still lagged behind humans. In addition to human evaluations, we also employed automatic evaluation metrics using GPT-4, uncovering similar trends in performance disparities. We also perform a fine-grained evaluation across diverse visual contexts and provide qualitative analysis which provides a robust framework for future advancements in the LMM design. https://con-textual.github.io/




RoboSpatial: Teaching Spatial Understanding to 2D and 3D Vision-Language Models for Robotics
Spatial understanding is a crucial capability for robots to make grounded decisions based on their environment. This foundational skill enables robots not only to perceive their surroundings but also to reason about and interact meaningfully within the world. In modern robotics, these capabilities are taken on by visual language models, and they face significant challenges when applied to spatial reasoning context due to their training data sources. These sources utilize general-purpose image datasets, and they often lack sophisticated spatial scene understanding capabilities. For example, the datasets do not address reference frame comprehension - spatial relationships require clear contextual understanding, whether from an ego-centric, object-centric, or world-centric perspective, which allow for effective real-world interaction. To address this issue, we introduce RoboSpatial, a large-scale spatial understanding dataset consisting of real indoor and tabletop scenes captured as 3D scans and egocentric images, annotated with rich spatial information relevant to robotics. The dataset includes 1M images, 5K 3D scans, and 3M annotated spatial relationships, with paired 2D egocentric images and 3D scans to make it both 2D and 3D ready. Our experiments show that models trained with RoboSpatial outperform baselines on downstream tasks such as spatial affordance prediction, spatial relationship prediction, and robotics manipulation.


SpatialLLM: From Multi-modality Data to Urban Spatial Intelligence
We propose SpatialLLM, a novel approach advancing spatial intelligence tasks in complex urban scenes. Unlike previous methods requiring geographic analysis tools or domain expertise, SpatialLLM is a unified language model directly addressing various spatial intelligence tasks without any training, fine-tuning, or expert intervention. The core of SpatialLLM lies in constructing detailed and structured scene descriptions from raw spatial data to prompt pre-trained LLMs for scene-based analysis. Extensive experiments show that, with our designs, pretrained LLMs can accurately perceive spatial distribution information and enable zero-shot execution of advanced spatial intelligence tasks, including urban planning, ecological analysis, traffic management, etc. We argue that multi-field knowledge, context length, and reasoning ability are key factors influencing LLM performances in urban analysis. We hope that SpatialLLM will provide a novel viable perspective for urban intelligent analysis and management. The code and dataset are available at https://github.com/WHU-USI3DV/SpatialLLM.
ContextualStory: Consistent Visual Storytelling with Spatially-Enhanced and Storyline Context
Visual storytelling involves generating a sequence of coherent frames from a textual storyline while maintaining consistency in characters and scenes. Existing autoregressive methods, which rely on previous frame-sentence pairs, struggle with high memory usage, slow generation speeds, and limited context integration. To address these issues, we propose ContextualStory, a novel framework designed to generate coherent story frames and extend frames for visual storytelling. ContextualStory utilizes Spatially-Enhanced Temporal Attention to capture spatial and temporal dependencies, handling significant character movements effectively. Additionally, we introduce a Storyline Contextualizer to enrich context in storyline embedding, and a StoryFlow Adapter to measure scene changes between frames for guiding the model. Extensive experiments on PororoSV and FlintstonesSV datasets demonstrate that ContextualStory significantly outperforms existing SOTA methods in both story visualization and continuation. Code is available at https://github.com/sixiaozheng/ContextualStory.

STDAN: Deformable Attention Network for Space-Time Video Super-Resolution
The target of space-time video super-resolution (STVSR) is to increase the spatial-temporal resolution of low-resolution (LR) and low frame rate (LFR) videos. Recent approaches based on deep learning have made significant improvements, but most of them only use two adjacent frames, that is, short-term features, to synthesize the missing frame embedding, which cannot fully explore the information flow of consecutive input LR frames. In addition, existing STVSR models hardly exploit the temporal contexts explicitly to assist high-resolution (HR) frame reconstruction. To address these issues, in this paper, we propose a deformable attention network called STDAN for STVSR. First, we devise a long-short term feature interpolation (LSTFI) module, which is capable of excavating abundant content from more neighboring input frames for the interpolation process through a bidirectional RNN structure. Second, we put forward a spatial-temporal deformable feature aggregation (STDFA) module, in which spatial and temporal contexts in dynamic video frames are adaptively captured and aggregated to enhance SR reconstruction. Experimental results on several datasets demonstrate that our approach outperforms state-of-the-art STVSR methods. The code is available at https://github.com/littlewhitesea/STDAN.
3DSRBench: A Comprehensive 3D Spatial Reasoning Benchmark
3D spatial reasoning is the ability to analyze and interpret the positions, orientations, and spatial relationships of objects within the 3D space. This allows models to develop a comprehensive understanding of the 3D scene, enabling their applicability to a broader range of areas, such as autonomous navigation, robotics, and AR/VR. While large multi-modal models (LMMs) have achieved remarkable progress in a wide range of image and video understanding tasks, their capabilities to perform 3D spatial reasoning on diverse natural images are less studied. In this work we present the first comprehensive 3D spatial reasoning benchmark, 3DSRBench, with 2,772 manually annotated visual question-answer pairs across 12 question types. We conduct robust and thorough evaluation of 3D spatial reasoning capabilities by balancing the data distribution and adopting a novel FlipEval strategy. To further study the robustness of 3D spatial reasoning w.r.t. camera 3D viewpoints, our 3DSRBench includes two subsets with 3D spatial reasoning questions on paired images with common and uncommon viewpoints. We benchmark a wide range of open-sourced and proprietary LMMs, uncovering their limitations in various aspects of 3D awareness, such as height, orientation, location, and multi-object reasoning, as well as their degraded performance on images with uncommon camera viewpoints. Our 3DSRBench provide valuable findings and insights about the future development of LMMs with strong 3D reasoning capabilities. Our project page and dataset is available https://3dsrbench.github.io.





Large Language Models for Next Point-of-Interest Recommendation
The next Point of Interest (POI) recommendation task is to predict users' immediate next POI visit given their historical data. Location-Based Social Network (LBSN) data, which is often used for the next POI recommendation task, comes with challenges. One frequently disregarded challenge is how to effectively use the abundant contextual information present in LBSN data. Previous methods are limited by their numerical nature and fail to address this challenge. In this paper, we propose a framework that uses pretrained Large Language Models (LLMs) to tackle this challenge. Our framework allows us to preserve heterogeneous LBSN data in its original format, hence avoiding the loss of contextual information. Furthermore, our framework is capable of comprehending the inherent meaning of contextual information due to the inclusion of commonsense knowledge. In experiments, we test our framework on three real-world LBSN datasets. Our results show that the proposed framework outperforms the state-of-the-art models in all three datasets. Our analysis demonstrates the effectiveness of the proposed framework in using contextual information as well as alleviating the commonly encountered cold-start and short trajectory problems.
Pingmark: A Textual Protocol for Universal Spatial Mentions
Pingmark defines a universal textual protocol for expressing spatial context through a minimal symbol: !@. Rather than embedding coordinates or using proprietary map links, Pingmark introduces a semantic trigger that compliant client applications interpret to generate a standardized resolver link of the form https://pingmark.me/lat/lon/[timestamp]. This allows location expression to function like existing textual conventions - @ for identity or # for topics - but for physical space. The protocol requires no user registration, relies on open mapping technologies, and protects privacy by generating location data ephemerally and locally. This paper presents the motivation, syntax, and design of the Pingmark Protocol Specification (PPS v0.1), its reference resolver implementation, and the long-term goal of establishing Pingmark as an open Internet standard for spatial mentions.

Lightweight In-Context Tuning for Multimodal Unified Models
In-context learning (ICL) involves reasoning from given contextual examples. As more modalities comes, this procedure is becoming more challenging as the interleaved input modalities convolutes the understanding process. This is exemplified by the observation that multimodal models often struggle to effectively extrapolate from contextual examples to perform ICL. To address these challenges, we introduce MultiModal In-conteXt Tuning (M^2IXT), a lightweight module to enhance the ICL capabilities of multimodal unified models. The proposed M^2IXT module perceives an expandable context window to incorporate various labeled examples of multiple modalities (e.g., text, image, and coordinates). It can be prepended to various multimodal unified models (e.g., OFA, Unival, LLaVA) of different architectures and trained via a mixed-tasks strategy to enable rapid few-shot adaption on multiple tasks and datasets. When tuned on as little as 50K multimodal data, M^2IXT can boost the few-shot ICL performance significantly (e.g., 18\% relative increase for OFA), and obtained state-of-the-art results across an array of tasks including visual question answering, image captioning, visual grounding, and visual entailment, while being considerably small in terms of model parameters (e.g., sim20times smaller than Flamingo or MMICL), highlighting the flexibility and effectiveness of M^2IXT as a multimodal in-context learner.

GeoLM: Empowering Language Models for Geospatially Grounded Language Understanding
Humans subconsciously engage in geospatial reasoning when reading articles. We recognize place names and their spatial relations in text and mentally associate them with their physical locations on Earth. Although pretrained language models can mimic this cognitive process using linguistic context, they do not utilize valuable geospatial information in large, widely available geographical databases, e.g., OpenStreetMap. This paper introduces GeoLM, a geospatially grounded language model that enhances the understanding of geo-entities in natural language. GeoLM leverages geo-entity mentions as anchors to connect linguistic information in text corpora with geospatial information extracted from geographical databases. GeoLM connects the two types of context through contrastive learning and masked language modeling. It also incorporates a spatial coordinate embedding mechanism to encode distance and direction relations to capture geospatial context. In the experiment, we demonstrate that GeoLM exhibits promising capabilities in supporting toponym recognition, toponym linking, relation extraction, and geo-entity typing, which bridge the gap between natural language processing and geospatial sciences. The code is publicly available at https://github.com/knowledge-computing/geolm.

PanoContext-Former: Panoramic Total Scene Understanding with a Transformer
Panoramic image enables deeper understanding and more holistic perception of 360^circ surrounding environment, which can naturally encode enriched scene context information compared to standard perspective image. Previous work has made lots of effort to solve the scene understanding task in a bottom-up form, thus each sub-task is processed separately and few correlations are explored in this procedure. In this paper, we propose a novel method using depth prior for holistic indoor scene understanding which recovers the objects' shapes, oriented bounding boxes and the 3D room layout simultaneously from a single panorama. In order to fully utilize the rich context information, we design a transformer-based context module to predict the representation and relationship among each component of the scene. In addition, we introduce a real-world dataset for scene understanding, including photo-realistic panoramas, high-fidelity depth images, accurately annotated room layouts, and oriented object bounding boxes and shapes. Experiments on the synthetic and real-world datasets demonstrate that our method outperforms previous panoramic scene understanding methods in terms of both layout estimation and 3D object detection.

Beyond Pixels: Introducing Geometric-Semantic World Priors for Video-based Embodied Models via Spatio-temporal Alignment
Achieving human-like reasoning in deep learning models for complex tasks in unknown environments remains a critical challenge in embodied intelligence. While advanced vision-language models (VLMs) excel in static scene understanding, their limitations in spatio-temporal reasoning and adaptation to dynamic, open-set tasks like task-oriented navigation and embodied question answering (EQA) persist due to inadequate modeling of fine-grained spatio-temporal cues and physical world comprehension. To address this, we propose VEME, a novel cross-modal alignment method that enhances generalization in unseen scenes by learning an ego-centric, experience-centered world model. Our framework integrates three key components: (1) a cross-modal alignment framework bridging objects, spatial representations, and visual semantics with spatio-temporal cues to enhance VLM in-context learning; (2) a dynamic, implicit cognitive map activated by world embedding to enable task-relevant geometric-semantic memory recall; and (3) an instruction-based navigation and reasoning framework leveraging embodied priors for long-term planning and efficient exploration. By embedding geometry-aware spatio-temporal episodic experiences, our method significantly improves reasoning and planning in dynamic environments. Experimental results on VSI-Bench and VLN-CE demonstrate 1%-3% accuracy and exploration efficiency improvement compared to traditional approaches.
OmniBooth: Learning Latent Control for Image Synthesis with Multi-modal Instruction
We present OmniBooth, an image generation framework that enables spatial control with instance-level multi-modal customization. For all instances, the multimodal instruction can be described through text prompts or image references. Given a set of user-defined masks and associated text or image guidance, our objective is to generate an image, where multiple objects are positioned at specified coordinates and their attributes are precisely aligned with the corresponding guidance. This approach significantly expands the scope of text-to-image generation, and elevates it to a more versatile and practical dimension in controllability. In this paper, our core contribution lies in the proposed latent control signals, a high-dimensional spatial feature that provides a unified representation to integrate the spatial, textual, and image conditions seamlessly. The text condition extends ControlNet to provide instance-level open-vocabulary generation. The image condition further enables fine-grained control with personalized identity. In practice, our method empowers users with more flexibility in controllable generation, as users can choose multi-modal conditions from text or images as needed. Furthermore, thorough experiments demonstrate our enhanced performance in image synthesis fidelity and alignment across different tasks and datasets. Project page: https://len-li.github.io/omnibooth-web/



Towards Natural Language-Guided Drones: GeoText-1652 Benchmark with Spatial Relation Matching
Navigating drones through natural language commands remains challenging due to the dearth of accessible multi-modal datasets and the stringent precision requirements for aligning visual and textual data. To address this pressing need, we introduce GeoText-1652, a new natural language-guided geo-localization benchmark. This dataset is systematically constructed through an interactive human-computer process leveraging Large Language Model (LLM) driven annotation techniques in conjunction with pre-trained vision models. GeoText-1652 extends the established University-1652 image dataset with spatial-aware text annotations, thereby establishing one-to-one correspondences between image, text, and bounding box elements. We further introduce a new optimization objective to leverage fine-grained spatial associations, called blending spatial matching, for region-level spatial relation matching. Extensive experiments reveal that our approach maintains a competitive recall rate comparing other prevailing cross-modality methods. This underscores the promising potential of our approach in elevating drone control and navigation through the seamless integration of natural language commands in real-world scenarios.

Reframing Spatial Reasoning Evaluation in Language Models: A Real-World Simulation Benchmark for Qualitative Reasoning
Spatial reasoning plays a vital role in both human cognition and machine intelligence, prompting new research into language models' (LMs) capabilities in this regard. However, existing benchmarks reveal shortcomings in evaluating qualitative spatial reasoning (QSR). These benchmarks typically present oversimplified scenarios or unclear natural language descriptions, hindering effective evaluation. We present a novel benchmark for assessing QSR in LMs, which is grounded in realistic 3D simulation data, offering a series of diverse room layouts with various objects and their spatial relationships. This approach provides a more detailed and context-rich narrative for spatial reasoning evaluation, diverging from traditional, toy-task-oriented scenarios. Our benchmark encompasses a broad spectrum of qualitative spatial relationships, including topological, directional, and distance relations. These are presented with different viewing points, varied granularities, and density of relation constraints to mimic real-world complexities. A key contribution is our logic-based consistency-checking tool, which enables the assessment of multiple plausible solutions, aligning with real-world scenarios where spatial relationships are often open to interpretation. Our benchmark evaluation of advanced LMs reveals their strengths and limitations in spatial reasoning. They face difficulties with multi-hop spatial reasoning and interpreting a mix of different view descriptions, pointing to areas for future improvement.
A Survey of Context Engineering for Large Language Models
The performance of Large Language Models (LLMs) is fundamentally determined by the contextual information provided during inference. This survey introduces Context Engineering, a formal discipline that transcends simple prompt design to encompass the systematic optimization of information payloads for LLMs. We present a comprehensive taxonomy decomposing Context Engineering into its foundational components and the sophisticated implementations that integrate them into intelligent systems. We first examine the foundational components: context retrieval and generation, context processing and context management. We then explore how these components are architecturally integrated to create sophisticated system implementations: retrieval-augmented generation (RAG), memory systems and tool-integrated reasoning, and multi-agent systems. Through this systematic analysis of over 1300 research papers, our survey not only establishes a technical roadmap for the field but also reveals a critical research gap: a fundamental asymmetry exists between model capabilities. While current models, augmented by advanced context engineering, demonstrate remarkable proficiency in understanding complex contexts, they exhibit pronounced limitations in generating equally sophisticated, long-form outputs. Addressing this gap is a defining priority for future research. Ultimately, this survey provides a unified framework for both researchers and engineers advancing context-aware AI.





From Context to Action: Analysis of the Impact of State Representation and Context on the Generalization of Multi-Turn Web Navigation Agents
Recent advancements in Large Language Model (LLM)-based frameworks have extended their capabilities to complex real-world applications, such as interactive web navigation. These systems, driven by user commands, navigate web browsers to complete tasks through multi-turn dialogues, offering both innovative opportunities and significant challenges. Despite the introduction of benchmarks for conversational web navigation, a detailed understanding of the key contextual components that influence the performance of these agents remains elusive. This study aims to fill this gap by analyzing the various contextual elements crucial to the functioning of web navigation agents. We investigate the optimization of context management, focusing on the influence of interaction history and web page representation. Our work highlights improved agent performance across out-of-distribution scenarios, including unseen websites, categories, and geographic locations through effective context management. These findings provide insights into the design and optimization of LLM-based agents, enabling more accurate and effective web navigation in real-world applications.


Can Multimodal Large Language Models Understand Spatial Relations?
Spatial relation reasoning is a crucial task for multimodal large language models (MLLMs) to understand the objective world. However, current benchmarks have issues like relying on bounding boxes, ignoring perspective substitutions, or allowing questions to be answered using only the model's prior knowledge without image understanding. To address these issues, we introduce SpatialMQA, a human-annotated spatial relation reasoning benchmark based on COCO2017, which enables MLLMs to focus more on understanding images in the objective world. To ensure data quality, we design a well-tailored annotation procedure, resulting in SpatialMQA consisting of 5,392 samples. Based on this benchmark, a series of closed- and open-source MLLMs are implemented and the results indicate that the current state-of-the-art MLLM achieves only 48.14% accuracy, far below the human-level accuracy of 98.40%. Extensive experimental analyses are also conducted, suggesting the future research directions. The benchmark and codes are available at https://github.com/ziyan-xiaoyu/SpatialMQA.git.

An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models
Large Multimodal Models (LMMs) have achieved strong performance across a range of vision and language tasks. However, their spatial reasoning capabilities are under-investigated. In this paper, we construct a novel VQA dataset, Spatial-MM, to comprehensively study LMMs' spatial understanding and reasoning capabilities. Our analyses on object-relationship and multi-hop reasoning reveal several important findings. Firstly, bounding boxes and scene graphs, even synthetic ones, can significantly enhance LMMs' spatial reasoning. Secondly, LMMs struggle more with questions posed from the human perspective than the camera perspective about the image. Thirdly, chain of thought (CoT) prompting does not improve model performance on complex multi-hop questions involving spatial relations. % Moreover, spatial reasoning steps are much less accurate than non-spatial ones across MLLMs. Lastly, our perturbation analysis on GQA-spatial reveals that LMMs are much stronger at basic object detection than complex spatial reasoning. We believe our benchmark dataset and in-depth analyses can spark further research on LMMs spatial reasoning. Spatial-MM benchmark is available at: https://github.com/FatemehShiri/Spatial-MM
SpartQA: : A Textual Question Answering Benchmark for Spatial Reasoning
This paper proposes a question-answering (QA) benchmark for spatial reasoning on natural language text which contains more realistic spatial phenomena not covered by prior work and is challenging for state-of-the-art language models (LM). We propose a distant supervision method to improve on this task. Specifically, we design grammar and reasoning rules to automatically generate a spatial description of visual scenes and corresponding QA pairs. Experiments show that further pretraining LMs on these automatically generated data significantly improves LMs' capability on spatial understanding, which in turn helps to better solve two external datasets, bAbI, and boolQ. We hope that this work can foster investigations into more sophisticated models for spatial reasoning over text.
Spatial-DISE: A Unified Benchmark for Evaluating Spatial Reasoning in Vision-Language Models
Spatial reasoning ability is crucial for Vision Language Models (VLMs) to support real-world applications in diverse domains including robotics, augmented reality, and autonomous navigation. Unfortunately, existing benchmarks are inadequate in assessing spatial reasoning ability, especially the intrinsic-dynamic spatial reasoning which is a fundamental aspect of human spatial cognition. In this paper, we propose a unified benchmark, Spatial-DISE, based on a cognitively grounded taxonomy that categorizes tasks into four fundamental quadrants: Intrinsic-Static, Intrinsic-Dynamic, Extrinsic-Static, and Extrinsic-Dynamic spatial reasoning. Moreover, to address the issue of data scarcity, we develop a scalable and automated pipeline to generate diverse and verifiable spatial reasoning questions, resulting in a new Spatial-DISE dataset that includes Spatial-DISE Bench (559 evaluation VQA pairs) and Spatial-DISE-12K (12K+ training VQA pairs). Our comprehensive evaluation across 28 state-of-the-art VLMs reveals that, current VLMs have a large and consistent gap to human competence, especially on multi-step multi-view spatial reasoning. Spatial-DISE offers a robust framework, valuable dataset, and clear direction for future research toward human-like spatial intelligence. Benchmark, dataset, and code will be publicly released.
Improvements to context based self-supervised learning
We develop a set of methods to improve on the results of self-supervised learning using context. We start with a baseline of patch based arrangement context learning and go from there. Our methods address some overt problems such as chromatic aberration as well as other potential problems such as spatial skew and mid-level feature neglect. We prevent problems with testing generalization on common self-supervised benchmark tests by using different datasets during our development. The results of our methods combined yield top scores on all standard self-supervised benchmarks, including classification and detection on PASCAL VOC 2007, segmentation on PASCAL VOC 2012, and "linear tests" on the ImageNet and CSAIL Places datasets. We obtain an improvement over our baseline method of between 4.0 to 7.1 percentage points on transfer learning classification tests. We also show results on different standard network architectures to demonstrate generalization as well as portability. All data, models and programs are available at: https://gdo-datasci.llnl.gov/selfsupervised/.

CoMPaSS: Enhancing Spatial Understanding in Text-to-Image Diffusion Models
Text-to-image diffusion models excel at generating photorealistic images, but commonly struggle to render accurate spatial relationships described in text prompts. We identify two core issues underlying this common failure: 1) the ambiguous nature of spatial-related data in existing datasets, and 2) the inability of current text encoders to accurately interpret the spatial semantics of input descriptions. We address these issues with CoMPaSS, a versatile training framework that enhances spatial understanding of any T2I diffusion model. CoMPaSS solves the ambiguity of spatial-related data with the Spatial Constraints-Oriented Pairing (SCOP) data engine, which curates spatially-accurate training data through a set of principled spatial constraints. To better exploit the curated high-quality spatial priors, CoMPaSS further introduces a Token ENcoding ORdering (TENOR) module to allow better exploitation of high-quality spatial priors, effectively compensating for the shortcoming of text encoders. Extensive experiments on four popular open-weight T2I diffusion models covering both UNet- and MMDiT-based architectures demonstrate the effectiveness of CoMPaSS by setting new state-of-the-arts with substantial relative gains across well-known benchmarks on spatial relationships generation, including VISOR (+98%), T2I-CompBench Spatial (+67%), and GenEval Position (+131%). Code will be available at https://github.com/blurgyy/CoMPaSS.


A Recipe for Generating 3D Worlds From a Single Image
We introduce a recipe for generating immersive 3D worlds from a single image by framing the task as an in-context learning problem for 2D inpainting models. This approach requires minimal training and uses existing generative models. Our process involves two steps: generating coherent panoramas using a pre-trained diffusion model and lifting these into 3D with a metric depth estimator. We then fill unobserved regions by conditioning the inpainting model on rendered point clouds, requiring minimal fine-tuning. Tested on both synthetic and real images, our method produces high-quality 3D environments suitable for VR display. By explicitly modeling the 3D structure of the generated environment from the start, our approach consistently outperforms state-of-the-art, video synthesis-based methods along multiple quantitative image quality metrics. Project Page: https://katjaschwarz.github.io/worlds/
MARRS: Multimodal Reference Resolution System
Successfully handling context is essential for any dialog understanding task. This context maybe be conversational (relying on previous user queries or system responses), visual (relying on what the user sees, for example, on their screen), or background (based on signals such as a ringing alarm or playing music). In this work, we present an overview of MARRS, or Multimodal Reference Resolution System, an on-device framework within a Natural Language Understanding system, responsible for handling conversational, visual and background context. In particular, we present different machine learning models to enable handing contextual queries; specifically, one to enable reference resolution, and one to handle context via query rewriting. We also describe how these models complement each other to form a unified, coherent, lightweight system that can understand context while preserving user privacy.

GAEA: A Geolocation Aware Conversational Model
Image geolocalization, in which, traditionally, an AI model predicts the precise GPS coordinates of an image is a challenging task with many downstream applications. However, the user cannot utilize the model to further their knowledge other than the GPS coordinate; the model lacks an understanding of the location and the conversational ability to communicate with the user. In recent days, with tremendous progress of large multimodal models (LMMs) proprietary and open-source researchers have attempted to geolocalize images via LMMs. However, the issues remain unaddressed; beyond general tasks, for more specialized downstream tasks, one of which is geolocalization, LMMs struggle. In this work, we propose to solve this problem by introducing a conversational model GAEA that can provide information regarding the location of an image, as required by a user. No large-scale dataset enabling the training of such a model exists. Thus we propose a comprehensive dataset GAEA with 800K images and around 1.6M question answer pairs constructed by leveraging OpenStreetMap (OSM) attributes and geographical context clues. For quantitative evaluation, we propose a diverse benchmark comprising 4K image-text pairs to evaluate conversational capabilities equipped with diverse question types. We consider 11 state-of-the-art open-source and proprietary LMMs and demonstrate that GAEA significantly outperforms the best open-source model, LLaVA-OneVision by 25.69% and the best proprietary model, GPT-4o by 8.28%. Our dataset, model and codes are available


Spatial-R1: Enhancing MLLMs in Video Spatial Reasoning
Enhancing the spatial reasoning capabilities of Multi-modal Large Language Models (MLLMs) for video understanding is crucial yet challenging. We present Spatial-R1, a targeted approach involving two key contributions: the curation of SR, a new video spatial reasoning dataset from ScanNet with automatically generated QA pairs across seven task types, and the application of Task-Specific Group Relative Policy Optimization (GRPO) for fine-tuning. By training the Qwen2.5-VL-7B-Instruct model on SR using GRPO, Spatial-R1 significantly advances performance on the VSI-Bench benchmark, achieving a 7.4\% gain over the baseline and outperforming strong contemporary models. This work validates the effectiveness of specialized data curation and optimization techniques for improving complex spatial reasoning in video MLLMs.

SURPRISE3D: A Dataset for Spatial Understanding and Reasoning in Complex 3D Scenes
The integration of language and 3D perception is critical for embodied AI and robotic systems to perceive, understand, and interact with the physical world. Spatial reasoning, a key capability for understanding spatial relationships between objects, remains underexplored in current 3D vision-language research. Existing datasets often mix semantic cues (e.g., object name) with spatial context, leading models to rely on superficial shortcuts rather than genuinely interpreting spatial relationships. To address this gap, we introduce Surprise3D, a novel dataset designed to evaluate language-guided spatial reasoning segmentation in complex 3D scenes. Surprise3D consists of more than 200k vision language pairs across 900+ detailed indoor scenes from ScanNet++ v2, including more than 2.8k unique object classes. The dataset contains 89k+ human-annotated spatial queries deliberately crafted without object name, thereby mitigating shortcut biases in spatial understanding. These queries comprehensively cover various spatial reasoning skills, such as relative position, narrative perspective, parametric perspective, and absolute distance reasoning. Initial benchmarks demonstrate significant challenges for current state-of-the-art expert 3D visual grounding methods and 3D-LLMs, underscoring the necessity of our dataset and the accompanying 3D Spatial Reasoning Segmentation (3D-SRS) benchmark suite. Surprise3D and 3D-SRS aim to facilitate advancements in spatially aware AI, paving the way for effective embodied interaction and robotic planning. The code and datasets can be found in https://github.com/liziwennba/SUPRISE.
OST-Bench: Evaluating the Capabilities of MLLMs in Online Spatio-temporal Scene Understanding
Recent advances in multimodal large language models (MLLMs) have shown remarkable capabilities in integrating vision and language for complex reasoning. While most existing benchmarks evaluate models under offline settings with a fixed set of pre-recorded inputs, we introduce OST-Bench, a benchmark designed to evaluate Online Spatio-Temporal understanding from the perspective of an agent actively exploring a scene. The Online aspect emphasizes the need to process and reason over incrementally acquired observations, while the Spatio-Temporal component requires integrating current visual inputs with historical memory to support dynamic spatial reasoning. OST-Bench better reflects the challenges of real-world embodied perception. Built on an efficient data collection pipeline, OST-Bench consists of 1.4k scenes and 10k question-answer pairs collected from ScanNet, Matterport3D, and ARKitScenes. We evaluate several leading MLLMs on OST-Bench and observe that they fall short on tasks requiring complex spatio-temporal reasoning. Under the online setting, their accuracy declines as the exploration horizon extends and the memory grows. Through further experimental analysis, we identify common error patterns across models and find that both complex clue-based spatial reasoning demands and long-term memory retrieval requirements significantly drop model performance along two separate axes, highlighting the core challenges that must be addressed to improve online embodied reasoning. To foster further research and development in the field, our codes, dataset, and benchmark are available. Our project page is: https://rbler1234.github.io/OSTBench.github.io/


SpatialLM: Training Large Language Models for Structured Indoor Modeling
SpatialLM is a large language model designed to process 3D point cloud data and generate structured 3D scene understanding outputs. These outputs include architectural elements like walls, doors, windows, and oriented object boxes with their semantic categories. Unlike previous methods which exploit task-specific network designs, our model adheres to the standard multimodal LLM architecture and is fine-tuned directly from open-source LLMs. To train SpatialLM, we collect a large-scale, high-quality synthetic dataset consisting of the point clouds of 12,328 indoor scenes (54,778 rooms) with ground-truth 3D annotations, and conduct a careful study on various modeling and training decisions. On public benchmarks, our model gives state-of-the-art performance in layout estimation and competitive results in 3D object detection. With that, we show a feasible path for enhancing the spatial understanding capabilities of modern LLMs for applications in augmented reality, embodied robotics, and more.

Mem4Nav: Boosting Vision-and-Language Navigation in Urban Environments with a Hierarchical Spatial-Cognition Long-Short Memory System
Vision-and-Language Navigation (VLN) in large-scale urban environments requires embodied agents to ground linguistic instructions in complex scenes and recall relevant experiences over extended time horizons. Prior modular pipelines offer interpretability but lack unified memory, while end-to-end (M)LLM agents excel at fusing vision and language yet remain constrained by fixed context windows and implicit spatial reasoning. We introduce Mem4Nav, a hierarchical spatial-cognition long-short memory system that can augment any VLN backbone. Mem4Nav fuses a sparse octree for fine-grained voxel indexing with a semantic topology graph for high-level landmark connectivity, storing both in trainable memory tokens embedded via a reversible Transformer. Long-term memory (LTM) compresses and retains historical observations at both octree and graph nodes, while short-term memory (STM) caches recent multimodal entries in relative coordinates for real-time obstacle avoidance and local planning. At each step, STM retrieval sharply prunes dynamic context, and, when deeper history is needed, LTM tokens are decoded losslessly to reconstruct past embeddings. Evaluated on Touchdown and Map2Seq across three backbones (modular, state-of-the-art VLN with prompt-based LLM, and state-of-the-art VLN with strided-attention MLLM), Mem4Nav yields 7-13 pp gains in Task Completion, sufficient SPD reduction, and >10 pp nDTW improvement. Ablations confirm the indispensability of both the hierarchical map and dual memory modules. Our codes are open-sourced via https://github.com/tsinghua-fib-lab/Mem4Nav.

FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition
Recent approaches such as ControlNet offer users fine-grained spatial control over text-to-image (T2I) diffusion models. However, auxiliary modules have to be trained for each type of spatial condition, model architecture, and checkpoint, putting them at odds with the diverse intents and preferences a human designer would like to convey to the AI models during the content creation process. In this work, we present FreeControl, a training-free approach for controllable T2I generation that supports multiple conditions, architectures, and checkpoints simultaneously. FreeControl designs structure guidance to facilitate the structure alignment with a guidance image, and appearance guidance to enable the appearance sharing between images generated using the same seed. Extensive qualitative and quantitative experiments demonstrate the superior performance of FreeControl across a variety of pre-trained T2I models. In particular, FreeControl facilitates convenient training-free control over many different architectures and checkpoints, allows the challenging input conditions on which most of the existing training-free methods fail, and achieves competitive synthesis quality with training-based approaches.





SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
Understanding and reasoning about spatial relationships is a fundamental capability for Visual Question Answering (VQA) and robotics. While Vision Language Models (VLM) have demonstrated remarkable performance in certain VQA benchmarks, they still lack capabilities in 3D spatial reasoning, such as recognizing quantitative relationships of physical objects like distances or size differences. We hypothesize that VLMs' limited spatial reasoning capability is due to the lack of 3D spatial knowledge in training data and aim to solve this problem by training VLMs with Internet-scale spatial reasoning data. To this end, we present a system to facilitate this approach. We first develop an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images. We then investigate various factors in the training recipe, including data quality, training pipeline, and VLM architecture. Our work features the first internet-scale 3D spatial reasoning dataset in metric space. By training a VLM on such data, we significantly enhance its ability on both qualitative and quantitative spatial VQA. Finally, we demonstrate that this VLM unlocks novel downstream applications in chain-of-thought spatial reasoning and robotics due to its quantitative estimation capability. Project website: https://spatial-vlm.github.io/




ReVideo: Remake a Video with Motion and Content Control
Despite significant advancements in video generation and editing using diffusion models, achieving accurate and localized video editing remains a substantial challenge. Additionally, most existing video editing methods primarily focus on altering visual content, with limited research dedicated to motion editing. In this paper, we present a novel attempt to Remake a Video (ReVideo) which stands out from existing methods by allowing precise video editing in specific areas through the specification of both content and motion. Content editing is facilitated by modifying the first frame, while the trajectory-based motion control offers an intuitive user interaction experience. ReVideo addresses a new task involving the coupling and training imbalance between content and motion control. To tackle this, we develop a three-stage training strategy that progressively decouples these two aspects from coarse to fine. Furthermore, we propose a spatiotemporal adaptive fusion module to integrate content and motion control across various sampling steps and spatial locations. Extensive experiments demonstrate that our ReVideo has promising performance on several accurate video editing applications, i.e., (1) locally changing video content while keeping the motion constant, (2) keeping content unchanged and customizing new motion trajectories, (3) modifying both content and motion trajectories. Our method can also seamlessly extend these applications to multi-area editing without specific training, demonstrating its flexibility and robustness.




MCPToolBench++: A Large Scale AI Agent Model Context Protocol MCP Tool Use Benchmark
LLMs' capabilities are enhanced by using function calls to integrate various data sources or API results into the context window. Typical tools include search, web crawlers, maps, financial data, file systems, and browser usage, etc. Integrating these data sources or functions requires a standardized method. The Model Context Protocol (MCP) provides a standardized way to supply context to LLMs. However, the evaluation of LLMs and AI Agents' MCP tool use abilities suffer from several issues. First, there's a lack of comprehensive datasets or benchmarks to evaluate various MCP tools. Second, the diverse formats of response from MCP tool call execution further increase the difficulty of evaluation. Additionally, unlike existing tool-use benchmarks with high success rates in functions like programming and math functions, the success rate of real-world MCP tool is not guaranteed and varies across different MCP servers. Furthermore, the LLMs' context window also limits the number of available tools that can be called in a single run, because the textual descriptions of tool and the parameters have long token length for an LLM to process all at once. To help address the challenges of evaluating LLMs' performance on calling MCP tools, we propose MCPToolBench++, a large-scale, multi-domain AI Agent tool use benchmark. As of July 2025, this benchmark is build upon marketplace of over 4k MCP servers from more than 40 categories, collected from the MCP marketplaces and GitHub communities. The datasets consist of both single-step and multi-step tool calls across different categories. We evaluated SOTA LLMs with agentic abilities on this benchmark and reported the results.
Unsupervised Visual Representation Learning by Context Prediction
This work explores the use of spatial context as a source of free and plentiful supervisory signal for training a rich visual representation. Given only a large, unlabeled image collection, we extract random pairs of patches from each image and train a convolutional neural net to predict the position of the second patch relative to the first. We argue that doing well on this task requires the model to learn to recognize objects and their parts. We demonstrate that the feature representation learned using this within-image context indeed captures visual similarity across images. For example, this representation allows us to perform unsupervised visual discovery of objects like cats, people, and even birds from the Pascal VOC 2011 detection dataset. Furthermore, we show that the learned ConvNet can be used in the R-CNN framework and provides a significant boost over a randomly-initialized ConvNet, resulting in state-of-the-art performance among algorithms which use only Pascal-provided training set annotations.
SmolRGPT: Efficient Spatial Reasoning for Warehouse Environments with 600M Parameters
Recent advances in vision-language models (VLMs) have enabled powerful multimodal reasoning, but state-of-the-art approaches typically rely on extremely large models with prohibitive computational and memory requirements. This makes their deployment challenging in resource-constrained environments such as warehouses, robotics, and industrial applications, where both efficiency and robust spatial understanding are critical. In this work, we present SmolRGPT, a compact vision-language architecture that explicitly incorporates region-level spatial reasoning by integrating both RGB and depth cues. SmolRGPT employs a three-stage curriculum that progressively align visual and language features, enables spatial relationship understanding, and adapts to task-specific datasets. We demonstrate that with only 600M parameters, SmolRGPT achieves competitive results on challenging warehouse spatial reasoning benchmarks, matching or exceeding the performance of much larger alternatives. These findings highlight the potential for efficient, deployable multimodal intelligence in real-world settings without sacrificing core spatial reasoning capabilities. The code of the experimentation will be available at: https://github.com/abtraore/SmolRGPT
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Spatial intelligence is essential for multimodal large language models (MLLMs) operating in the complex physical world. Existing benchmarks, however, probe only single-image relations and thus fail to assess the multi-image spatial reasoning that real-world deployments demand. We introduce MMSI-Bench, a VQA benchmark dedicated to multi-image spatial intelligence. Six 3D-vision researchers spent more than 300 hours meticulously crafting 1,000 challenging, unambiguous multiple-choice questions from over 120,000 images, each paired with carefully designed distractors and a step-by-step reasoning process. We conduct extensive experiments and thoroughly evaluate 34 open-source and proprietary MLLMs, observing a wide gap: the strongest open-source model attains roughly 30% accuracy and OpenAI's o3 reasoning model reaches 40%, while humans score 97%. These results underscore the challenging nature of MMSI-Bench and the substantial headroom for future research. Leveraging the annotated reasoning processes, we also provide an automated error analysis pipeline that diagnoses four dominant failure modes, including (1) grounding errors, (2) overlap-matching and scene-reconstruction errors, (3) situation-transformation reasoning errors, and (4) spatial-logic errors, offering valuable insights for advancing multi-image spatial intelligence. Project page: https://runsenxu.com/projects/MMSI_Bench .


3D Scene Prompting for Scene-Consistent Camera-Controllable Video Generation
We present 3DScenePrompt, a framework that generates the next video chunk from arbitrary-length input while enabling precise camera control and preserving scene consistency. Unlike methods conditioned on a single image or a short clip, we employ dual spatio-temporal conditioning that reformulates context-view referencing across the input video. Our approach conditions on both temporally adjacent frames for motion continuity and spatially adjacent content for scene consistency. However, when generating beyond temporal boundaries, directly using spatially adjacent frames would incorrectly preserve dynamic elements from the past. We address this by introducing a 3D scene memory that represents exclusively the static geometry extracted from the entire input video. To construct this memory, we leverage dynamic SLAM with our newly introduced dynamic masking strategy that explicitly separates static scene geometry from moving elements. The static scene representation can then be projected to any target viewpoint, providing geometrically consistent warped views that serve as strong 3D spatial prompts while allowing dynamic regions to evolve naturally from temporal context. This enables our model to maintain long-range spatial coherence and precise camera control without sacrificing computational efficiency or motion realism. Extensive experiments demonstrate that our framework significantly outperforms existing methods in scene consistency, camera controllability, and generation quality. Project page : https://cvlab-kaist.github.io/3DScenePrompt/
Spatial Computing: Concept, Applications, Challenges and Future Directions
Spatial computing is a technological advancement that facilitates the seamless integration of devices into the physical environment, resulting in a more natural and intuitive digital world user experience. Spatial computing has the potential to become a significant advancement in the field of computing. From GPS and location-based services to healthcare, spatial computing technologies have influenced and improved our interactions with the digital world. The use of spatial computing in creating interactive digital environments has become increasingly popular and effective. This is explained by its increasing significance among researchers and industrial organisations, which motivated us to conduct this review. This review provides a detailed overview of spatial computing, including its enabling technologies and its impact on various applications. Projects related to spatial computing are also discussed. In this review, we also explored the potential challenges and limitations of spatial computing. Furthermore, we discuss potential solutions and future directions. Overall, this paper aims to provide a comprehensive understanding of spatial computing, its enabling technologies, their impact on various applications, emerging challenges, and potential solutions.


Evaluating Spatial Understanding of Large Language Models
Large language models (LLMs) show remarkable capabilities across a variety of tasks. Despite the models only seeing text in training, several recent studies suggest that LLM representations implicitly capture aspects of the underlying grounded concepts. Here, we explore LLM representations of a particularly salient kind of grounded knowledge -- spatial relationships. We design natural-language navigation tasks and evaluate the ability of LLMs, in particular GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about spatial structures. These tasks reveal substantial variability in LLM performance across different spatial structures, including square, hexagonal, and triangular grids, rings, and trees. In extensive error analysis, we find that LLMs' mistakes reflect both spatial and non-spatial factors. These findings suggest that LLMs appear to capture certain aspects of spatial structure implicitly, but room for improvement remains.
Region-Level Context-Aware Multimodal Understanding
Despite significant progress, existing research on Multimodal Large Language Models (MLLMs) mainly focuses on general visual understanding, overlooking the ability to integrate textual context associated with objects for a more context-aware multimodal understanding -- an ability we refer to as Region-level Context-aware Multimodal Understanding (RCMU). To address this limitation, we first formulate the RCMU task, which requires models to respond to user instructions by integrating both image content and textual information of regions or objects. To equip MLLMs with RCMU capabilities, we propose Region-level Context-aware Visual Instruction Tuning (RCVIT), which incorporates object information into the model input and enables the model to utilize bounding box coordinates to effectively associate objects' visual content with their textual information. To address the lack of datasets, we introduce the RCMU dataset, a large-scale visual instruction tuning dataset that covers multiple RCMU tasks. We also propose RC\&P-Bench, a comprehensive benchmark that can evaluate the performance of MLLMs in RCMU and multimodal personalized understanding tasks. Additionally, we propose a reference-free evaluation metric to perform a comprehensive and fine-grained evaluation of the region-level context-aware image descriptions. By performing RCVIT on Qwen2-VL models with the RCMU dataset, we developed RC-Qwen2-VL models. Experimental results indicate that RC-Qwen2-VL models not only achieve outstanding performance on multiple RCMU tasks but also demonstrate successful applications in multimodal RAG and personalized conversation. Our data, model and benchmark are available at https://github.com/hongliang-wei/RC-MLLM
Task Memory Engine: Spatial Memory for Robust Multi-Step LLM Agents
Large Language Models (LLMs) falter in multi-step interactions -- often hallucinating, repeating actions, or misinterpreting user corrections -- due to reliance on linear, unstructured context. This fragility stems from the lack of persistent memory to track evolving goals and task dependencies, undermining trust in autonomous agents. We introduce the Task Memory Engine (TME), a modular memory controller that transforms existing LLMs into robust, revision-aware agents without fine-tuning. TME implements a spatial memory framework that replaces flat context with graph-based structures to support consistent, multi-turn reasoning. Departing from linear concatenation and ReAct-style prompting, TME builds a dynamic task graph -- either a tree or directed acyclic graph (DAG) -- to map user inputs to subtasks, align them with prior context, and enable dependency-tracked revisions. Its Task Representation and Intent Management (TRIM) component models task semantics and user intent to ensure accurate interpretation. Across four multi-turn scenarios-trip planning, cooking, meeting scheduling, and shopping cart editing -- TME eliminates 100% of hallucinations and misinterpretations in three tasks, and reduces hallucinations by 66.7% and misinterpretations by 83.3% across 27 user turns, outperforming ReAct. TME's modular design supports plug-and-play deployment and domain-specific customization, adaptable to both personal assistants and enterprise automation. We release TME's codebase, benchmarks, and components as open-source resources, enabling researchers to develop reliable LLM agents. TME's scalable architecture addresses a critical gap in agent performance across complex, interactive settings.

SituationalLLM: Proactive language models with scene awareness for dynamic, contextual task guidance
Large language models (LLMs) have achieved remarkable success in text-based tasks but often struggle to provide actionable guidance in real-world physical environments. This is because of their inability to recognize their limited understanding of the user's physical context. We present SituationalLLM, a novel approach that integrates structured scene information into an LLM to deliver proactive, context-aware assistance. By encoding objects, attributes, and relationships in a custom Scene Graph Language, SituationalLLM actively identifies gaps in environmental context and seeks clarifications during user interactions. This behavior emerges from training on the Situational Awareness Database for Instruct-Tuning (SAD-Instruct), which combines diverse, scenario-specific scene graphs with iterative, dialogue-based refinements. Experimental results indicate that SituationalLLM outperforms generic LLM baselines in task specificity, reliability, and adaptability, paving the way for environment-aware AI assistants capable of delivering robust, user-centric guidance under real-world constraints.

Open-vocabulary Queryable Scene Representations for Real World Planning
Large language models (LLMs) have unlocked new capabilities of task planning from human instructions. However, prior attempts to apply LLMs to real-world robotic tasks are limited by the lack of grounding in the surrounding scene. In this paper, we develop NLMap, an open-vocabulary and queryable scene representation to address this problem. NLMap serves as a framework to gather and integrate contextual information into LLM planners, allowing them to see and query available objects in the scene before generating a context-conditioned plan. NLMap first establishes a natural language queryable scene representation with Visual Language models (VLMs). An LLM based object proposal module parses instructions and proposes involved objects to query the scene representation for object availability and location. An LLM planner then plans with such information about the scene. NLMap allows robots to operate without a fixed list of objects nor executable options, enabling real robot operation unachievable by previous methods. Project website: https://nlmap-saycan.github.io
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
A Large-Scale Evolvable Dataset for Model Context Protocol Ecosystem and Security Analysis
The Model Context Protocol (MCP) has recently emerged as a standardized interface for connecting language models with external tools and data. As the ecosystem rapidly expands, the lack of a structured, comprehensive view of existing MCP artifacts presents challenges for research. To bridge this gap, we introduce MCPCorpus, a large-scale dataset containing around 14K MCP servers and 300 MCP clients. Each artifact is annotated with 20+ normalized attributes capturing its identity, interface configuration, GitHub activity, and metadata. MCPCorpus provides a reproducible snapshot of the real-world MCP ecosystem, enabling studies of adoption trends, ecosystem health, and implementation diversity. To keep pace with the rapid evolution of the MCP ecosystem, we provide utility tools for automated data synchronization, normalization, and inspection. Furthermore, to support efficient exploration and exploitation, we release a lightweight web-based search interface. MCPCorpus is publicly available at: https://github.com/Snakinya/MCPCorpus.

SpatialRGPT: Grounded Spatial Reasoning in Vision Language Models
Vision Language Models (VLMs) have demonstrated remarkable performance in 2D vision and language tasks. However, their ability to reason about spatial arrangements remains limited. In this work, we introduce Spatial Region GPT (SpatialRGPT) to enhance VLMs' spatial perception and reasoning capabilities. SpatialRGPT advances VLMs' spatial understanding through two key innovations: (1) a data curation pipeline that enables effective learning of regional representation from 3D scene graphs, and (2) a flexible plugin module for integrating depth information into the visual encoder of existing VLMs. During inference, when provided with user-specified region proposals, SpatialRGPT can accurately perceive their relative directions and distances. Additionally, we propose SpatialRGBT-Bench, a benchmark with ground-truth 3D annotations encompassing indoor, outdoor, and simulated environments, for evaluating 3D spatial cognition in VLMs. Our results demonstrate that SpatialRGPT significantly enhances performance in spatial reasoning tasks, both with and without local region prompts. The model also exhibits strong generalization capabilities, effectively reasoning about complex spatial relations and functioning as a region-aware dense reward annotator for robotic tasks. Code, dataset, and benchmark are released at https://www.anjiecheng.me/SpatialRGPT
Bi-directional Contextual Attention for 3D Dense Captioning
3D dense captioning is a task involving the localization of objects and the generation of descriptions for each object in a 3D scene. Recent approaches have attempted to incorporate contextual information by modeling relationships with object pairs or aggregating the nearest neighbor features of an object. However, the contextual information constructed in these scenarios is limited in two aspects: first, objects have multiple positional relationships that exist across the entire global scene, not only near the object itself. Second, it faces with contradicting objectives--where localization and attribute descriptions are generated better with tight localization, while descriptions involving global positional relations are generated better with contextualized features of the global scene. To overcome this challenge, we introduce BiCA, a transformer encoder-decoder pipeline that engages in 3D dense captioning for each object with Bi-directional Contextual Attention. Leveraging parallelly decoded instance queries for objects and context queries for non-object contexts, BiCA generates object-aware contexts, where the contexts relevant to each object is summarized, and context-aware objects, where the objects relevant to the summarized object-aware contexts are aggregated. This extension relieves previous methods from the contradicting objectives, enhancing both localization performance and enabling the aggregation of contextual features throughout the global scene; thus improving caption generation performance simultaneously. Extensive experiments on two of the most widely-used 3D dense captioning datasets demonstrate that our proposed method achieves a significant improvement over prior methods.
Dynamic Double Space Tower
The Visual Question Answering (VQA) task requires the simultaneous understanding of image content and question semantics. However, existing methods often have difficulty handling complex reasoning scenarios due to insufficient cross-modal interaction and capturing the entity spatial relationships in the image.huang2023adaptiveliu2021comparingguibas2021adaptivezhang2022vsaWe studied a brand-new approach to replace the attention mechanism in order to enhance the reasoning ability of the model and its understanding of spatial relationships.Specifically, we propose a dynamic bidirectional spatial tower, which is divided into four layers to observe the image according to the principle of human gestalt vision. This naturally provides a powerful structural prior for the spatial organization between entities, enabling the model to no longer blindly search for relationships between pixels but make judgments based on more meaningful perceptual units. Change from "seeing images" to "perceiving and organizing image content".A large number of experiments have shown that our module can be used in any other multimodal model and achieve advanced results, demonstrating its potential in spatial relationship processing.Meanwhile, the multimodal visual question-answering model July trained by our method has achieved state-of-the-art results with only 3B parameters, especially on the question-answering dataset of spatial relations.

SketchVideo: Sketch-based Video Generation and Editing
Video generation and editing conditioned on text prompts or images have undergone significant advancements. However, challenges remain in accurately controlling global layout and geometry details solely by texts, and supporting motion control and local modification through images. In this paper, we aim to achieve sketch-based spatial and motion control for video generation and support fine-grained editing of real or synthetic videos. Based on the DiT video generation model, we propose a memory-efficient control structure with sketch control blocks that predict residual features of skipped DiT blocks. Sketches are drawn on one or two keyframes (at arbitrary time points) for easy interaction. To propagate such temporally sparse sketch conditions across all frames, we propose an inter-frame attention mechanism to analyze the relationship between the keyframes and each video frame. For sketch-based video editing, we design an additional video insertion module that maintains consistency between the newly edited content and the original video's spatial feature and dynamic motion. During inference, we use latent fusion for the accurate preservation of unedited regions. Extensive experiments demonstrate that our SketchVideo achieves superior performance in controllable video generation and editing.




4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.



MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers
The Model Context Protocol has emerged as a transformative standard for connecting large language models to external data sources and tools, rapidly gaining adoption across major AI providers and development platforms. However, existing benchmarks are overly simplistic and fail to capture real application challenges such as long-horizon reasoning and large, unfamiliar tool spaces. To address this critical gap, we introduce MCP-Universe, the first comprehensive benchmark specifically designed to evaluate LLMs in realistic and hard tasks through interaction with real-world MCP servers. Our benchmark encompasses 6 core domains spanning 11 different MCP servers: Location Navigation, Repository Management, Financial Analysis, 3D Design, Browser Automation, and Web Searching. To ensure rigorous evaluation, we implement execution-based evaluators, including format evaluators for agent format compliance, static evaluators for time-invariant content matching, and dynamic evaluators that automatically retrieve real-time ground truth for temporally sensitive tasks. Through extensive evaluation of leading LLMs, we find that even SOTA models such as GPT-5 (43.72%), Grok-4 (33.33%) and Claude-4.0-Sonnet (29.44%) exhibit significant performance limitations. In addition, our benchmark poses a significant long-context challenge for LLM agents, as the number of input tokens increases rapidly with the number of interaction steps. Moreover, it introduces an unknown-tools challenge, as LLM agents often lack familiarity with the precise usage of the MCP servers. Notably, enterprise-level agents like Cursor cannot achieve better performance than standard ReAct frameworks. Beyond evaluation, we open-source our extensible evaluation framework with UI support, enabling researchers and practitioners to seamlessly integrate new agents and MCP servers while fostering innovation in the rapidly evolving MCP ecosystem.

STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
Transformer-based Spatial Grounding: A Comprehensive Survey
Spatial grounding, the process of associating natural language expressions with corresponding image regions, has rapidly advanced due to the introduction of transformer-based models, significantly enhancing multimodal representation and cross-modal alignment. Despite this progress, the field lacks a comprehensive synthesis of current methodologies, dataset usage, evaluation metrics, and industrial applicability. This paper presents a systematic literature review of transformer-based spatial grounding approaches from 2018 to 2025. Our analysis identifies dominant model architectures, prevalent datasets, and widely adopted evaluation metrics, alongside highlighting key methodological trends and best practices. This study provides essential insights and structured guidance for researchers and practitioners, facilitating the development of robust, reliable, and industry-ready transformer-based spatial grounding models.

OmniSpatial: Towards Comprehensive Spatial Reasoning Benchmark for Vision Language Models
Spatial reasoning is a key aspect of cognitive psychology and remains a major bottleneck for current vision-language models (VLMs). While extensive research has aimed to evaluate or improve VLMs' understanding of basic spatial relations, such as distinguishing left from right, near from far, and object counting, these tasks represent only the most fundamental level of spatial reasoning. In this work, we introduce OmniSpatial, a comprehensive and challenging benchmark for spatial reasoning, grounded in cognitive psychology. OmniSpatial covers four major categories: dynamic reasoning, complex spatial logic, spatial interaction, and perspective-taking, with 50 fine-grained subcategories. Through Internet data crawling and careful manual annotation, we construct over 1.5K question-answer pairs. Extensive experiments show that both open- and closed-source VLMs, as well as existing reasoning and spatial understanding models, exhibit significant limitations in comprehensive spatial understanding. We further analyze failure cases and propose potential directions for future research.


Spatially-Aware Transformer for Embodied Agents
Episodic memory plays a crucial role in various cognitive processes, such as the ability to mentally recall past events. While cognitive science emphasizes the significance of spatial context in the formation and retrieval of episodic memory, the current primary approach to implementing episodic memory in AI systems is through transformers that store temporally ordered experiences, which overlooks the spatial dimension. As a result, it is unclear how the underlying structure could be extended to incorporate the spatial axis beyond temporal order alone and thereby what benefits can be obtained. To address this, this paper explores the use of Spatially-Aware Transformer models that incorporate spatial information. These models enable the creation of place-centric episodic memory that considers both temporal and spatial dimensions. Adopting this approach, we demonstrate that memory utilization efficiency can be improved, leading to enhanced accuracy in various place-centric downstream tasks. Additionally, we propose the Adaptive Memory Allocator, a memory management method based on reinforcement learning that aims to optimize efficiency of memory utilization. Our experiments demonstrate the advantages of our proposed model in various environments and across multiple downstream tasks, including prediction, generation, reasoning, and reinforcement learning. The source code for our models and experiments will be available at https://github.com/junmokane/spatially-aware-transformer.

Contextual Object Detection with Multimodal Large Language Models
Recent Multimodal Large Language Models (MLLMs) are remarkable in vision-language tasks, such as image captioning and question answering, but lack the essential perception ability, i.e., object detection. In this work, we address this limitation by introducing a novel research problem of contextual object detection -- understanding visible objects within different human-AI interactive contexts. Three representative scenarios are investigated, including the language cloze test, visual captioning, and question answering. Moreover, we present ContextDET, a unified multimodal model that is capable of end-to-end differentiable modeling of visual-language contexts, so as to locate, identify, and associate visual objects with language inputs for human-AI interaction. Our ContextDET involves three key submodels: (i) a visual encoder for extracting visual representations, (ii) a pre-trained LLM for multimodal context decoding, and (iii) a visual decoder for predicting bounding boxes given contextual object words. The new generate-then-detect framework enables us to detect object words within human vocabulary. Extensive experiments show the advantages of ContextDET on our proposed CODE benchmark, open-vocabulary detection, and referring image segmentation. Github: https://github.com/yuhangzang/ContextDET.

Long-Term Planning Around Humans in Domestic Environments with 3D Scene Graphs
Long-term planning for robots operating in domestic environments poses unique challenges due to the interactions between humans, objects, and spaces. Recent advancements in trajectory planning have leveraged vision-language models (VLMs) to extract contextual information for robots operating in real-world environments. While these methods achieve satisfying performance, they do not explicitly model human activities. Such activities influence surrounding objects and reshape spatial constraints. This paper presents a novel approach to trajectory planning that integrates human preferences, activities, and spatial context through an enriched 3D scene graph (3DSG) representation. By incorporating activity-based relationships, our method captures the spatial impact of human actions, leading to more context-sensitive trajectory adaptation. Preliminary results demonstrate that our approach effectively assigns costs to spaces influenced by human activities, ensuring that the robot trajectory remains contextually appropriate and sensitive to the ongoing environment. This balance between task efficiency and social appropriateness enhances context-aware human-robot interactions in domestic settings. Future work includes implementing a full planning pipeline and conducting user studies to evaluate trajectory acceptability.

Model Context Protocols in Adaptive Transport Systems: A Survey
The rapid expansion of interconnected devices, autonomous systems, and AI applications has created severe fragmentation in adaptive transport systems, where diverse protocols and context sources remain isolated. This survey provides the first systematic investigation of the Model Context Protocol (MCP) as a unifying paradigm, highlighting its ability to bridge protocol-level adaptation with context-aware decision making. Analyzing established literature, we show that existing efforts have implicitly converged toward MCP-like architectures, signaling a natural evolution from fragmented solutions to standardized integration frameworks. We propose a five-category taxonomy covering adaptive mechanisms, context-aware frameworks, unification models, integration strategies, and MCP-enabled architectures. Our findings reveal three key insights: traditional transport protocols have reached the limits of isolated adaptation, MCP's client-server and JSON-RPC structure enables semantic interoperability, and AI-driven transport demands integration paradigms uniquely suited to MCP. Finally, we present a research roadmap positioning MCP as a foundation for next-generation adaptive, context-aware, and intelligent transport infrastructures.

Mix3D: Out-of-Context Data Augmentation for 3D Scenes
We present Mix3D, a data augmentation technique for segmenting large-scale 3D scenes. Since scene context helps reasoning about object semantics, current works focus on models with large capacity and receptive fields that can fully capture the global context of an input 3D scene. However, strong contextual priors can have detrimental implications like mistaking a pedestrian crossing the street for a car. In this work, we focus on the importance of balancing global scene context and local geometry, with the goal of generalizing beyond the contextual priors in the training set. In particular, we propose a "mixing" technique which creates new training samples by combining two augmented scenes. By doing so, object instances are implicitly placed into novel out-of-context environments and therefore making it harder for models to rely on scene context alone, and instead infer semantics from local structure as well. We perform detailed analysis to understand the importance of global context, local structures and the effect of mixing scenes. In experiments, we show that models trained with Mix3D profit from a significant performance boost on indoor (ScanNet, S3DIS) and outdoor datasets (SemanticKITTI). Mix3D can be trivially used with any existing method, e.g., trained with Mix3D, MinkowskiNet outperforms all prior state-of-the-art methods by a significant margin on the ScanNet test benchmark 78.1 mIoU. Code is available at: https://nekrasov.dev/mix3d/


Why Do MLLMs Struggle with Spatial Understanding? A Systematic Analysis from Data to Architecture
Spatial understanding is essential for Multimodal Large Language Models (MLLMs) to support perception, reasoning, and planning in embodied environments. Despite recent progress, existing studies reveal that MLLMs still struggle with spatial understanding. However, existing research lacks a comprehensive and systematic evaluation of these limitations, often restricted to isolated scenarios, such as single-view or video. In this work, we present a systematic analysis of spatial understanding from both data and architectural perspectives across three representative scenarios: single-view, multi-view, and video. We propose a benchmark named MulSeT (Multi-view Spatial Understanding Tasks), and design a series of experiments to analyze the spatial reasoning capabilities of MLLMs. From the data perspective, the performance of spatial understanding converges quickly as the training data increases, and the upper bound is relatively low, especially for tasks that require spatial imagination. This indicates that merely expanding training data is insufficient to achieve satisfactory performance. From the architectural perspective, we find that spatial understanding relies more heavily on the positional encoding within the visual encoder than within the language model, in both cascaded and native MLLMs. Moreover, we explore reasoning injection and envision future improvements through architectural design to optimize spatial understanding. These insights shed light on the limitations of current MLLMs and suggest new directions for improving spatial reasoning capabilities through data scaling and architectural tuning.
Towards Blind and Low-Vision Accessibility of Lightweight VLMs and Custom LLM-Evals
Large Vision-Language Models (VLMs) excel at understanding and generating video descriptions but their high memory, computation, and deployment demands hinder practical use particularly for blind and low-vision (BLV) users who depend on detailed, context-aware descriptions. To study the effect of model size on accessibility-focused description quality, we evaluate SmolVLM2 variants with 500M and 2.2B parameters across two diverse datasets: AVCaps (outdoor), and Charades (indoor). In this work, we introduce two novel evaluation frameworks specifically designed for BLV accessibility assessment: the Multi-Context BLV Framework evaluating spatial orientation, social interaction, action events, and ambience contexts; and the Navigational Assistance Framework focusing on mobility-critical information. Additionally, we conduct a systematic evaluation of four different prompt design strategies and deploy both models on a smartphone, evaluating FP32 and INT8 precision variants to assess real-world performance constraints on resource-limited mobile devices.
From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models
Long-context capabilities are essential for a wide range of applications, including document and video understanding, in-context learning, and inference-time scaling, all of which require models to process and reason over long sequences of text and multimodal data. In this work, we introduce a efficient training recipe for building ultra-long context LLMs from aligned instruct model, pushing the boundaries of context lengths from 128K to 1M, 2M, and 4M tokens. Our approach leverages efficient continued pretraining strategies to extend the context window and employs effective instruction tuning to maintain the instruction-following and reasoning abilities. Our UltraLong-8B, built on Llama3.1-Instruct with our recipe, achieves state-of-the-art performance across a diverse set of long-context benchmarks. Importantly, models trained with our approach maintain competitive performance on standard benchmarks, demonstrating balanced improvements for both long and short context tasks. We further provide an in-depth analysis of key design choices, highlighting the impacts of scaling strategies and data composition. Our findings establish a robust framework for efficiently scaling context lengths while preserving general model capabilities. We release all model weights at: https://ultralong.github.io/.


Where We Are and What We're Looking At: Query Based Worldwide Image Geo-localization Using Hierarchies and Scenes
Determining the exact latitude and longitude that a photo was taken is a useful and widely applicable task, yet it remains exceptionally difficult despite the accelerated progress of other computer vision tasks. Most previous approaches have opted to learn a single representation of query images, which are then classified at different levels of geographic granularity. These approaches fail to exploit the different visual cues that give context to different hierarchies, such as the country, state, and city level. To this end, we introduce an end-to-end transformer-based architecture that exploits the relationship between different geographic levels (which we refer to as hierarchies) and the corresponding visual scene information in an image through hierarchical cross-attention. We achieve this by learning a query for each geographic hierarchy and scene type. Furthermore, we learn a separate representation for different environmental scenes, as different scenes in the same location are often defined by completely different visual features. We achieve state of the art street level accuracy on 4 standard geo-localization datasets : Im2GPS, Im2GPS3k, YFCC4k, and YFCC26k, as well as qualitatively demonstrate how our method learns different representations for different visual hierarchies and scenes, which has not been demonstrated in the previous methods. These previous testing datasets mostly consist of iconic landmarks or images taken from social media, which makes them either a memorization task, or biased towards certain places. To address this issue we introduce a much harder testing dataset, Google-World-Streets-15k, comprised of images taken from Google Streetview covering the whole planet and present state of the art results. Our code will be made available in the camera-ready version.
Is It Really Long Context if All You Need Is Retrieval? Towards Genuinely Difficult Long Context NLP
Improvements in language models' capabilities have pushed their applications towards longer contexts, making long-context evaluation and development an active research area. However, many disparate use-cases are grouped together under the umbrella term of "long-context", defined simply by the total length of the model's input, including - for example - Needle-in-a-Haystack tasks, book summarization, and information aggregation. Given their varied difficulty, in this position paper we argue that conflating different tasks by their context length is unproductive. As a community, we require a more precise vocabulary to understand what makes long-context tasks similar or different. We propose to unpack the taxonomy of long-context based on the properties that make them more difficult with longer contexts. We propose two orthogonal axes of difficulty: (I) Diffusion: How hard is it to find the necessary information in the context? (II) Scope: How much necessary information is there to find? We survey the literature on long-context, provide justification for this taxonomy as an informative descriptor, and situate the literature with respect to it. We conclude that the most difficult and interesting settings, whose necessary information is very long and highly diffused within the input, is severely under-explored. By using a descriptive vocabulary and discussing the relevant properties of difficulty in long-context, we can implement more informed research in this area. We call for a careful design of tasks and benchmarks with distinctly long context, taking into account the characteristics that make it qualitatively different from shorter context.



GIRAFFE: Design Choices for Extending the Context Length of Visual Language Models
Visual Language Models (VLMs) demonstrate impressive capabilities in processing multimodal inputs, yet applications such as visual agents, which require handling multiple images and high-resolution videos, demand enhanced long-range modeling. Moreover, existing open-source VLMs lack systematic exploration into extending their context length, and commercial models often provide limited details. To tackle this, we aim to establish an effective solution that enhances long context performance of VLMs while preserving their capacities in short context scenarios. Towards this goal, we make the best design choice through extensive experiment settings from data curation to context window extending and utilizing: (1) we analyze data sources and length distributions to construct ETVLM - a data recipe to balance the performance across scenarios; (2) we examine existing position extending methods, identify their limitations and propose M-RoPE++ as an enhanced approach; we also choose to solely instruction-tune the backbone with mixed-source data; (3) we discuss how to better utilize extended context windows and propose hybrid-resolution training. Built on the Qwen-VL series model, we propose Giraffe, which is effectively extended to 128K lengths. Evaluated on extensive long context VLM benchmarks such as VideoMME and Viusal Haystacks, our Giraffe achieves state-of-the-art performance among similarly sized open-source long VLMs and is competitive with commercial model GPT-4V. We will open-source the code, data, and models.


Sparkle: Mastering Basic Spatial Capabilities in Vision Language Models Elicits Generalization to Composite Spatial Reasoning
Vision language models (VLMs) have demonstrated impressive performance across a wide range of downstream tasks. However, their proficiency in spatial reasoning remains limited, despite its crucial role in tasks involving navigation and interaction with physical environments. Specifically, most of these tasks rely on the core spatial reasoning capabilities in two-dimensional (2D) environments, and our evaluation reveals that state-of-the-art VLMs frequently generate implausible and incorrect responses to composite spatial reasoning problems, including simple pathfinding tasks that humans can solve effortlessly at a glance. To address this, we explore an effective approach to enhance 2D spatial reasoning within VLMs by training the model solely on basic spatial capabilities. We begin by disentangling the key components of 2D spatial reasoning: direction comprehension, distance estimation, and localization. Our central hypothesis is that mastering these basic spatial capabilities can significantly enhance a model's performance on composite spatial tasks requiring advanced spatial understanding and combinatorial problem-solving, with generalized improvements in visual-spatial tasks. To investigate this hypothesis, we introduce Sparkle, a framework that fine-tunes VLMs on these three basic spatial capabilities by synthetic data generation and targeted supervision to form an instruction dataset for each capability. Our experiments demonstrate that VLMs fine-tuned with Sparkle achieve significant performance gains, not only in the basic tasks themselves but also in generalizing to composite and out-of-distribution spatial reasoning tasks. These findings underscore the effectiveness of mastering basic spatial capabilities in enhancing composite spatial problem-solving, offering insights into systematic strategies for improving VLMs' spatial reasoning capabilities.



Does Spatial Cognition Emerge in Frontier Models?
Not yet. We present SPACE, a benchmark that systematically evaluates spatial cognition in frontier models. Our benchmark builds on decades of research in cognitive science. It evaluates large-scale mapping abilities that are brought to bear when an organism traverses physical environments, smaller-scale reasoning about object shapes and layouts, and cognitive infrastructure such as spatial attention and memory. For many tasks, we instantiate parallel presentations via text and images, allowing us to benchmark both large language models and large multimodal models. Results suggest that contemporary frontier models fall short of the spatial intelligence of animals, performing near chance level on a number of classic tests of animal cognition.




SpaRC and SpaRP: Spatial Reasoning Characterization and Path Generation for Understanding Spatial Reasoning Capability of Large Language Models
Spatial reasoning is a crucial component of both biological and artificial intelligence. In this work, we present a comprehensive study of the capability of current state-of-the-art large language models (LLMs) on spatial reasoning. To support our study, we created and contribute a novel Spatial Reasoning Characterization (SpaRC) framework and Spatial Reasoning Paths (SpaRP) datasets, to enable an in-depth understanding of the spatial relations and compositions as well as the usefulness of spatial reasoning chains. We found that all the state-of-the-art LLMs do not perform well on the datasets -- their performances are consistently low across different setups. The spatial reasoning capability improves substantially as model sizes scale up. Finetuning both large language models (e.g., Llama-2-70B) and smaller ones (e.g., Llama-2-13B) can significantly improve their F1-scores by 7--32 absolute points. We also found that the top proprietary LLMs still significantly outperform their open-source counterparts in topological spatial understanding and reasoning.
Context as Memory: Scene-Consistent Interactive Long Video Generation with Memory Retrieval
Recent advances in interactive video generation have shown promising results, yet existing approaches struggle with scene-consistent memory capabilities in long video generation due to limited use of historical context. In this work, we propose Context-as-Memory, which utilizes historical context as memory for video generation. It includes two simple yet effective designs: (1) storing context in frame format without additional post-processing; (2) conditioning by concatenating context and frames to be predicted along the frame dimension at the input, requiring no external control modules. Furthermore, considering the enormous computational overhead of incorporating all historical context, we propose the Memory Retrieval module to select truly relevant context frames by determining FOV (Field of View) overlap between camera poses, which significantly reduces the number of candidate frames without substantial information loss. Experiments demonstrate that Context-as-Memory achieves superior memory capabilities in interactive long video generation compared to SOTAs, even generalizing effectively to open-domain scenarios not seen during training. The link of our project page is https://context-as-memory.github.io/.
A Survey of Large Language Model-Powered Spatial Intelligence Across Scales: Advances in Embodied Agents, Smart Cities, and Earth Science
Over the past year, the development of large language models (LLMs) has brought spatial intelligence into focus, with much attention on vision-based embodied intelligence. However, spatial intelligence spans a broader range of disciplines and scales, from navigation and urban planning to remote sensing and earth science. What are the differences and connections between spatial intelligence across these fields? In this paper, we first review human spatial cognition and its implications for spatial intelligence in LLMs. We then examine spatial memory, knowledge representations, and abstract reasoning in LLMs, highlighting their roles and connections. Finally, we analyze spatial intelligence across scales -- from embodied to urban and global levels -- following a framework that progresses from spatial memory and understanding to spatial reasoning and intelligence. Through this survey, we aim to provide insights into interdisciplinary spatial intelligence research and inspire future studies.

COOCO -- Common Objects Out-of-Context -- Semantic Violation in Scenes: Investigating Multimodal Context in Referential Communication
Natural scenes provide us with rich contexts for object recognition and reference. In particular, knowing what type of scene one is looking at generates expectations about which objects will occur, and what their spatial configuration should be. Do Vision-Language Models (VLMs) learn to rely on scene contexts in a similar way, when generating references to objects? To address this question, we introduce the Common Objects Out-of-Context (COOCO) dataset and test to what extent VLMs rely on scene context to refer to objects under different degrees of scene-object congruency, and different perturbations. Our findings show that models leverage scene context adaptively, depending on both the semantic relatedness between object and scene and the level of noise. In particular, models rely more on context under high target-scene congruence or when objects are degraded. Attention analysis reveals that successful object categorisation involves increased focus on the target in mid-level layers, especially under moderate noise, suggesting that VLMs dynamically balance local and contextual information for reference generation. We make our dataset, code and models available at https://github.com/cs-nlp-uu/scenereg{https://github.com/cs-nlp-uu/scenereg}.
Why Is Spatial Reasoning Hard for VLMs? An Attention Mechanism Perspective on Focus Areas
Large Vision Language Models (VLMs) have long struggled with spatial reasoning tasks. Surprisingly, even simple spatial reasoning tasks, such as recognizing "under" or "behind" relationships between only two objects, pose significant challenges for current VLMs. In this work, we study the spatial reasoning challenge from the lens of mechanistic interpretability, diving into the model's internal states to examine the interactions between image and text tokens. By tracing attention distribution over the image through out intermediate layers, we observe that successful spatial reasoning correlates strongly with the model's ability to align its attention distribution with actual object locations, particularly differing between familiar and unfamiliar spatial relationships. Motivated by these findings, we propose ADAPTVIS based on inference-time confidence scores to sharpen the attention on highly relevant regions when confident, while smoothing and broadening the attention window to consider a wider context when confidence is lower. This training-free decoding method shows significant improvement (e.g., up to a 50 absolute point improvement) on spatial reasoning benchmarks such as WhatsUp and VSR with negligible cost. We make code and data publicly available for research purposes at https://github.com/shiqichen17/AdaptVis.



SPHERE: A Hierarchical Evaluation on Spatial Perception and Reasoning for Vision-Language Models
Current vision-language models may incorporate single-dimensional spatial cues, such as depth, object boundary, and basic spatial directions (e.g. left, right, front, back), yet often lack the multi-dimensional spatial reasoning necessary for human-like understanding and real-world applications. To address this gap, we develop SPHERE (Spatial Perception and Hierarchical Evaluation of REasoning), a hierarchical evaluation framework with a new human-annotated dataset to pinpoint model strengths and weaknesses, advancing from single-skill tasks to multi-skill tasks, and ultimately to complex reasoning tasks that require the integration of multiple spatial and visual cues with logical reasoning. Benchmark evaluation of state-of-the-art open-source models reveal significant shortcomings, especially in the abilities to understand distance and proximity, to reason from both allocentric and egocentric viewpoints, and to perform complex reasoning in a physical context. This work underscores the need for more advanced approaches to spatial understanding and reasoning, paving the way for improvements in vision-language models and their alignment with human-like spatial capabilities. The dataset will be open-sourced upon publication.


Improving GUI Grounding with Explicit Position-to-Coordinate Mapping
GUI grounding, the task of mapping natural-language instructions to pixel coordinates, is crucial for autonomous agents, yet remains difficult for current VLMs. The core bottleneck is reliable patch-to-pixel mapping, which breaks when extrapolating to high-resolution displays unseen during training. Current approaches generate coordinates as text tokens directly from visual features, forcing the model to infer complex position-to-pixel mappings implicitly; as a result, accuracy degrades and failures proliferate on new resolutions. We address this with two complementary innovations. First, RULER tokens serve as explicit coordinate markers, letting the model reference positions similar to gridlines on a map and adjust rather than generate coordinates from scratch. Second, Interleaved MRoPE (I-MRoPE) improves spatial encoding by ensuring that width and height dimensions are represented equally, addressing the asymmetry of standard positional schemes. Experiments on ScreenSpot, ScreenSpot-V2, and ScreenSpot-Pro show consistent gains in grounding accuracy, with the largest improvements on high-resolution interfaces. By providing explicit spatial guidance rather than relying on implicit learning, our approach enables more reliable GUI automation across diverse resolutions and platforms.



GeoCLIP: Clip-Inspired Alignment between Locations and Images for Effective Worldwide Geo-localization
Worldwide Geo-localization aims to pinpoint the precise location of images taken anywhere on Earth. This task has considerable challenges due to immense variation in geographic landscapes. The image-to-image retrieval-based approaches fail to solve this problem on a global scale as it is not feasible to construct a large gallery of images covering the entire world. Instead, existing approaches divide the globe into discrete geographic cells, transforming the problem into a classification task. However, their performance is limited by the predefined classes and often results in inaccurate localizations when an image's location significantly deviates from its class center. To overcome these limitations, we propose GeoCLIP, a novel CLIP-inspired Image-to-GPS retrieval approach that enforces alignment between the image and its corresponding GPS locations. GeoCLIP's location encoder models the Earth as a continuous function by employing positional encoding through random Fourier features and constructing a hierarchical representation that captures information at varying resolutions to yield a semantically rich high-dimensional feature suitable to use even beyond geo-localization. To the best of our knowledge, this is the first work employing GPS encoding for geo-localization. We demonstrate the efficacy of our method via extensive experiments and ablations on benchmark datasets. We achieve competitive performance with just 20% of training data, highlighting its effectiveness even in limited-data settings. Furthermore, we qualitatively demonstrate geo-localization using a text query by leveraging CLIP backbone of our image encoder. The project webpage is available at: https://vicentevivan.github.io/GeoCLIP
Spatial Transformer Networks
Convolutional Neural Networks define an exceptionally powerful class of models, but are still limited by the lack of ability to be spatially invariant to the input data in a computationally and parameter efficient manner. In this work we introduce a new learnable module, the Spatial Transformer, which explicitly allows the spatial manipulation of data within the network. This differentiable module can be inserted into existing convolutional architectures, giving neural networks the ability to actively spatially transform feature maps, conditional on the feature map itself, without any extra training supervision or modification to the optimisation process. We show that the use of spatial transformers results in models which learn invariance to translation, scale, rotation and more generic warping, resulting in state-of-the-art performance on several benchmarks, and for a number of classes of transformations.
MRSAudio: A Large-Scale Multimodal Recorded Spatial Audio Dataset with Refined Annotations
Humans rely on multisensory integration to perceive spatial environments, where auditory cues enable sound source localization in three-dimensional space. Despite the critical role of spatial audio in immersive technologies such as VR/AR, most existing multimodal datasets provide only monaural audio, which limits the development of spatial audio generation and understanding. To address these challenges, we introduce MRSAudio, a large-scale multimodal spatial audio dataset designed to advance research in spatial audio understanding and generation. MRSAudio spans four distinct components: MRSLife, MRSSpeech, MRSMusic, and MRSSing, covering diverse real-world scenarios. The dataset includes synchronized binaural and ambisonic audio, exocentric and egocentric video, motion trajectories, and fine-grained annotations such as transcripts, phoneme boundaries, lyrics, scores, and prompts. To demonstrate the utility and versatility of MRSAudio, we establish five foundational tasks: audio spatialization, and spatial text to speech, spatial singing voice synthesis, spatial music generation and sound event localization and detection. Results show that MRSAudio enables high-quality spatial modeling and supports a broad range of spatial audio research. Demos and dataset access are available at https://mrsaudio.github.io.

LongMagpie: A Self-synthesis Method for Generating Large-scale Long-context Instructions
High-quality long-context instruction data is essential for aligning long-context large language models (LLMs). Despite the public release of models like Qwen and Llama, their long-context instruction data remains proprietary. Human annotation is costly and challenging, while template-based synthesis methods limit scale, diversity, and quality. We introduce LongMagpie, a self-synthesis framework that automatically generates large-scale long-context instruction data. Our key insight is that aligned long-context LLMs, when presented with a document followed by special tokens preceding a user turn, auto-regressively generate contextually relevant queries. By harvesting these document-query pairs and the model's responses, LongMagpie produces high-quality instructions without human effort. Experiments on HELMET, RULER, and Longbench v2 demonstrate that LongMagpie achieves leading performance on long-context tasks while maintaining competitive performance on short-context tasks, establishing it as a simple and effective approach for open, diverse, and scalable long-context instruction data synthesis.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.





CODIS: Benchmarking Context-Dependent Visual Comprehension for Multimodal Large Language Models
Multimodal large language models (MLLMs) have demonstrated promising results in a variety of tasks that combine vision and language. As these models become more integral to research and applications, conducting comprehensive evaluations of their capabilities has grown increasingly important. However, most existing benchmarks fail to consider that, in certain situations, images need to be interpreted within a broader context. In this work, we introduce a new benchmark, named as CODIS, designed to assess the ability of models to use context provided in free-form text to enhance visual comprehension. Our findings indicate that MLLMs consistently fall short of human performance on this benchmark. Further analysis confirms that these models struggle to effectively extract and utilize contextual information to improve their understanding of images. This underscores the pressing need to enhance the ability of MLLMs to comprehend visuals in a context-dependent manner. View our project website at https://thunlp-mt.github.io/CODIS.


MapEval: A Map-Based Evaluation of Geo-Spatial Reasoning in Foundation Models
Recent advancements in foundation models have enhanced AI systems' capabilities in autonomous tool usage and reasoning. However, their ability in location or map-based reasoning - which improves daily life by optimizing navigation, facilitating resource discovery, and streamlining logistics - has not been systematically studied. To bridge this gap, we introduce MapEval, a benchmark designed to assess diverse and complex map-based user queries with geo-spatial reasoning. MapEval features three task types (textual, API-based, and visual) that require collecting world information via map tools, processing heterogeneous geo-spatial contexts (e.g., named entities, travel distances, user reviews or ratings, images), and compositional reasoning, which all state-of-the-art foundation models find challenging. Comprising 700 unique multiple-choice questions about locations across 180 cities and 54 countries, MapEval evaluates foundation models' ability to handle spatial relationships, map infographics, travel planning, and navigation challenges. Using MapEval, we conducted a comprehensive evaluation of 28 prominent foundation models. While no single model excelled across all tasks, Claude-3.5-Sonnet, GPT-4o, and Gemini-1.5-Pro achieved competitive performance overall. However, substantial performance gaps emerged, particularly in MapEval, where agents with Claude-3.5-Sonnet outperformed GPT-4o and Gemini-1.5-Pro by 16% and 21%, respectively, and the gaps became even more amplified when compared to open-source LLMs. Our detailed analyses provide insights into the strengths and weaknesses of current models, though all models still fall short of human performance by more than 20% on average, struggling with complex map images and rigorous geo-spatial reasoning. This gap highlights MapEval's critical role in advancing general-purpose foundation models with stronger geo-spatial understanding.





MP-GUI: Modality Perception with MLLMs for GUI Understanding
Graphical user interface (GUI) has become integral to modern society, making it crucial to be understood for human-centric systems. However, unlike natural images or documents, GUIs comprise artificially designed graphical elements arranged to convey specific semantic meanings. Current multi-modal large language models (MLLMs) already proficient in processing graphical and textual components suffer from hurdles in GUI understanding due to the lack of explicit spatial structure modeling. Moreover, obtaining high-quality spatial structure data is challenging due to privacy issues and noisy environments. To address these challenges, we present MP-GUI, a specially designed MLLM for GUI understanding. MP-GUI features three precisely specialized perceivers to extract graphical, textual, and spatial modalities from the screen as GUI-tailored visual clues, with spatial structure refinement strategy and adaptively combined via a fusion gate to meet the specific preferences of different GUI understanding tasks. To cope with the scarcity of training data, we also introduce a pipeline for automatically data collecting. Extensive experiments demonstrate that MP-GUI achieves impressive results on various GUI understanding tasks with limited data.

Getting it Right: Improving Spatial Consistency in Text-to-Image Models
One of the key shortcomings in current text-to-image (T2I) models is their inability to consistently generate images which faithfully follow the spatial relationships specified in the text prompt. In this paper, we offer a comprehensive investigation of this limitation, while also developing datasets and methods that achieve state-of-the-art performance. First, we find that current vision-language datasets do not represent spatial relationships well enough; to alleviate this bottleneck, we create SPRIGHT, the first spatially-focused, large scale dataset, by re-captioning 6 million images from 4 widely used vision datasets. Through a 3-fold evaluation and analysis pipeline, we find that SPRIGHT largely improves upon existing datasets in capturing spatial relationships. To demonstrate its efficacy, we leverage only ~0.25% of SPRIGHT and achieve a 22% improvement in generating spatially accurate images while also improving the FID and CMMD scores. Secondly, we find that training on images containing a large number of objects results in substantial improvements in spatial consistency. Notably, we attain state-of-the-art on T2I-CompBench with a spatial score of 0.2133, by fine-tuning on <500 images. Finally, through a set of controlled experiments and ablations, we document multiple findings that we believe will enhance the understanding of factors that affect spatial consistency in text-to-image models. We publicly release our dataset and model to foster further research in this area.





Video World Models with Long-term Spatial Memory
Emerging world models autoregressively generate video frames in response to actions, such as camera movements and text prompts, among other control signals. Due to limited temporal context window sizes, these models often struggle to maintain scene consistency during revisits, leading to severe forgetting of previously generated environments. Inspired by the mechanisms of human memory, we introduce a novel framework to enhancing long-term consistency of video world models through a geometry-grounded long-term spatial memory. Our framework includes mechanisms to store and retrieve information from the long-term spatial memory and we curate custom datasets to train and evaluate world models with explicitly stored 3D memory mechanisms. Our evaluations show improved quality, consistency, and context length compared to relevant baselines, paving the way towards long-term consistent world generation.

Struct2D: A Perception-Guided Framework for Spatial Reasoning in Large Multimodal Models
Unlocking spatial reasoning in Large Multimodal Models (LMMs) is crucial for enabling intelligent interaction with 3D environments. While prior efforts often rely on explicit 3D inputs or specialized model architectures, we ask: can LMMs reason about 3D space using only structured 2D representations derived from perception? We introduce Struct2D, a perception-guided prompting framework that combines bird's-eye-view (BEV) images with object marks and object-centric metadata, optionally incorporating egocentric keyframes when needed. Using Struct2D, we conduct an in-depth zero-shot analysis of closed-source LMMs (e.g., GPT-o3) and find that they exhibit surprisingly strong spatial reasoning abilities when provided with structured 2D inputs, effectively handling tasks such as relative direction estimation and route planning. Building on these insights, we construct Struct2D-Set, a large-scale instruction tuning dataset with 200K fine-grained QA pairs across eight spatial reasoning categories, generated automatically from 3D indoor scenes. We fine-tune an open-source LMM (Qwen2.5VL) on Struct2D-Set, achieving competitive performance on multiple benchmarks, including 3D question answering, dense captioning, and object grounding. Our approach demonstrates that structured 2D inputs can effectively bridge perception and language reasoning in LMMs-without requiring explicit 3D representations as input. We will release both our code and dataset to support future research.
How do Language Models Bind Entities in Context?
To correctly use in-context information, language models (LMs) must bind entities to their attributes. For example, given a context describing a "green square" and a "blue circle", LMs must bind the shapes to their respective colors. We analyze LM representations and identify the binding ID mechanism: a general mechanism for solving the binding problem, which we observe in every sufficiently large model from the Pythia and LLaMA families. Using causal interventions, we show that LMs' internal activations represent binding information by attaching binding ID vectors to corresponding entities and attributes. We further show that binding ID vectors form a continuous subspace, in which distances between binding ID vectors reflect their discernability. Overall, our results uncover interpretable strategies in LMs for representing symbolic knowledge in-context, providing a step towards understanding general in-context reasoning in large-scale LMs.

ConECT Dataset: Overcoming Data Scarcity in Context-Aware E-Commerce MT
Neural Machine Translation (NMT) has improved translation by using Transformer-based models, but it still struggles with word ambiguity and context. This problem is especially important in domain-specific applications, which often have problems with unclear sentences or poor data quality. Our research explores how adding information to models can improve translations in the context of e-commerce data. To this end we create ConECT -- a new Czech-to-Polish e-commerce product translation dataset coupled with images and product metadata consisting of 11,400 sentence pairs. We then investigate and compare different methods that are applicable to context-aware translation. We test a vision-language model (VLM), finding that visual context aids translation quality. Additionally, we explore the incorporation of contextual information into text-to-text models, such as the product's category path or image descriptions. The results of our study demonstrate that the incorporation of contextual information leads to an improvement in the quality of machine translation. We make the new dataset publicly available.

CoMemo: LVLMs Need Image Context with Image Memory
Recent advancements in Large Vision-Language Models built upon Large Language Models have established aligning visual features with LLM representations as the dominant paradigm. However, inherited LLM architectural designs introduce suboptimal characteristics for multimodal processing. First, LVLMs exhibit a bimodal distribution in attention allocation, leading to the progressive neglect of middle visual content as context expands. Second, conventional positional encoding schemes fail to preserve vital 2D structural relationships when processing dynamic high-resolution images. To address these limitations, we propose CoMemo - a dual-path architecture that combines a Context image path with an image Memory path for visual processing, effectively alleviating visual information neglect. Additionally, we introduce RoPE-DHR, a novel positional encoding mechanism that employs thumbnail-based positional aggregation to maintain 2D spatial awareness while mitigating remote decay in extended sequences. Evaluations across seven benchmarks,including long-context comprehension, multi-image reasoning, and visual question answering, demonstrate CoMemo's superior performance compared to conventional LVLM architectures. Project page is available at https://lalbj.github.io/projects/CoMemo/.


Modular Techniques for Synthetic Long-Context Data Generation in Language Model Training and Evaluation
The ability of large language models (LLMs) to process and reason over long textual inputs is critical for a wide range of real-world applications. However, progress in this area is significantly constrained by the absence of high-quality, diverse, and verifiable long-context datasets suitable for both training and evaluation. This work introduces a modular, extensible framework for synthetic long-context data generation via prompt-based interaction with LLMs. The framework supports multiple training and alignment objectives, including Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Group Relative Policy Optimization (GRPO). It encompasses four core generation paradigms: multi-turn conversational dialogues, document-grounded input-output pairs, verifiable instruction-response tasks, and long-context reasoning examples. Through templated prompting, a model-agnostic architecture, and metadata-enriched outputs, the proposed approach facilitates scalable, controllable, and purpose-aligned dataset creation for advancing long-context capabilities in LLMs.


MacRAG: Compress, Slice, and Scale-up for Multi-Scale Adaptive Context RAG
Long-context large language models (LC LLMs) combined with retrieval-augmented generation (RAG) hold strong potential for complex multi-hop and large-document tasks. However, existing RAG systems often suffer from imprecise retrieval, incomplete context coverage under constrained windows, and fragmented information from suboptimal context construction. We introduce Multi-scale Adaptive Context RAG (MacRAG), a hierarchical RAG framework that compresses and partitions documents into coarse-to-fine granularities, then adaptively merges relevant contexts through real-time chunk- and document-level expansions. By initiating with finest-level retrieval and progressively incorporating broader, higher-level context, MacRAG constructs effective query-specific long contexts, optimizing both precision and coverage. Evaluations on challenging LongBench expansions of HotpotQA, 2WikiMultihopQA, and Musique confirm MacRAG consistently surpasses baseline RAG pipelines in single- and multi-step generation using Llama-3.1-8B, Gemini-1.5-pro, and GPT-4o. Our results establish MacRAG as an efficient, scalable solution for real-world long-context, multi-hop reasoning. Our code is available at https://github.com/Leezekun/MacRAG.
Spatial Mixture-of-Experts
Many data have an underlying dependence on spatial location; it may be weather on the Earth, a simulation on a mesh, or a registered image. Yet this feature is rarely taken advantage of, and violates common assumptions made by many neural network layers, such as translation equivariance. Further, many works that do incorporate locality fail to capture fine-grained structure. To address this, we introduce the Spatial Mixture-of-Experts (SMoE) layer, a sparsely-gated layer that learns spatial structure in the input domain and routes experts at a fine-grained level to utilize it. We also develop new techniques to train SMoEs, including a self-supervised routing loss and damping expert errors. Finally, we show strong results for SMoEs on numerous tasks, and set new state-of-the-art results for medium-range weather prediction and post-processing ensemble weather forecasts.
Evaluating Language Model Context Windows: A "Working Memory" Test and Inference-time Correction
Large language models are prominently used in real-world applications, often tasked with reasoning over large volumes of documents. An exciting development in this space is models boasting extended context capabilities, with some accommodating over 2 million tokens. Such long context model capabilities remain uncertain in production systems, motivating the need to benchmark their performance on real world use cases. We address this challenge by proposing SWiM, an evaluation framework that addresses the limitations of standard tests. Testing the framework on eight long context models, we find that even strong models such as GPT-4 and Claude 3 Opus degrade in performance when information is present in the middle of the context window (lost-in-the-middle effect). Next, in addition to our benchmark, we propose medoid voting, a simple, but effective training-free approach that helps alleviate this effect, by generating responses a few times, each time randomly permuting documents in the context, and selecting the medoid answer. We evaluate medoid voting on single document QA tasks, achieving up to a 24% lift in accuracy.



Enhancing Spatial Reasoning in Vision-Language Models via Chain-of-Thought Prompting and Reinforcement Learning
This study investigates the spatial reasoning capabilities of vision-language models (VLMs) through Chain-of-Thought (CoT) prompting and reinforcement learning. We begin by evaluating the impact of different prompting strategies and find that simple CoT formats, where the model generates a reasoning step before the answer, not only fail to help, but can even harm the model's original performance. In contrast, structured multi-stage prompting based on scene graphs (SceneGraph CoT) significantly improves spatial reasoning accuracy. Furthermore, to improve spatial reasoning ability, we fine-tune models using Group Relative Policy Optimization (GRPO) on the SAT dataset and evaluate their performance on CVBench. Compared to supervised fine-tuning (SFT), GRPO achieves higher accuracy on Pass@1 evaluations and demonstrates superior robustness under out-of-distribution (OOD) conditions. In particular, we find that SFT overfits to surface-level linguistic patterns and may degrade performance when test-time phrasing changes (e.g., from "closer to" to "farther from"). GRPO, on the other hand, generalizes more reliably and maintains stable performance under such shifts. Our findings provide insights into how reinforcement learning and structured prompting improve the spatial reasoning capabilities and generalization behavior of modern VLMs. All code is open source at: https://github.com/Yvonne511/spatial-vlm-investigator
The What, Why, and How of Context Length Extension Techniques in Large Language Models -- A Detailed Survey
The advent of Large Language Models (LLMs) represents a notable breakthrough in Natural Language Processing (NLP), contributing to substantial progress in both text comprehension and generation. However, amidst these advancements, it is noteworthy that LLMs often face a limitation in terms of context length extrapolation. Understanding and extending the context length for LLMs is crucial in enhancing their performance across various NLP applications. In this survey paper, we delve into the multifaceted aspects of exploring why it is essential, and the potential transformations that superior techniques could bring to NLP applications. We study the inherent challenges associated with extending context length and present an organized overview of the existing strategies employed by researchers. Additionally, we discuss the intricacies of evaluating context extension techniques and highlight the open challenges that researchers face in this domain. Furthermore, we explore whether there is a consensus within the research community regarding evaluation standards and identify areas where further agreement is needed. This comprehensive survey aims to serve as a valuable resource for researchers, guiding them through the nuances of context length extension techniques and fostering discussions on future advancements in this evolving field.

Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at www.github.com/marccoru/locationencoder

A Plug-and-Play Method for Rare Human-Object Interactions Detection by Bridging Domain Gap
Human-object interactions (HOI) detection aims at capturing human-object pairs in images and corresponding actions. It is an important step toward high-level visual reasoning and scene understanding. However, due to the natural bias from the real world, existing methods mostly struggle with rare human-object pairs and lead to sub-optimal results. Recently, with the development of the generative model, a straightforward approach is to construct a more balanced dataset based on a group of supplementary samples. Unfortunately, there is a significant domain gap between the generated data and the original data, and simply merging the generated images into the original dataset cannot significantly boost the performance. To alleviate the above problem, we present a novel model-agnostic framework called Context-Enhanced Feature Alignment (CEFA) module, which can effectively align the generated data with the original data at the feature level and bridge the domain gap. Specifically, CEFA consists of a feature alignment module and a context enhancement module. On one hand, considering the crucial role of human-object pairs information in HOI tasks, the feature alignment module aligns the human-object pairs by aggregating instance information. On the other hand, to mitigate the issue of losing important context information caused by the traditional discriminator-style alignment method, we employ a context-enhanced image reconstruction module to improve the model's learning ability of contextual cues. Extensive experiments have shown that our method can serve as a plug-and-play module to improve the detection performance of HOI models on rare categorieshttps://github.com/LijunZhang01/CEFA.
Hyper-multi-step: The Truth Behind Difficult Long-context Tasks
Long-context language models (LCLM), characterized by their extensive context window, is becoming increasingly popular. Meanwhile, many long-context benchmarks present challenging tasks that even the most advanced LCLMs struggle to complete. However, the underlying sources of various challenging long-context tasks have seldom been studied. To bridge this gap, we conduct experiments to indicate their difficulty stems primarily from two basic issues: "multi-matching retrieval," which requires the simultaneous retrieval of multiple items, and "logic-based retrieval," which necessitates logical judgment within retrieval criteria. These two problems, while seemingly straightforward, actually exceed the capabilities of LCLMs because they are proven to be hyper-multi-step (demanding numerous steps to solve) in nature. This finding could explain why LLMs struggle with more advanced long-context tasks, providing a more accurate perspective for rethinking solutions for them.

Context-Aware Planning and Environment-Aware Memory for Instruction Following Embodied Agents
Accomplishing household tasks requires to plan step-by-step actions considering the consequences of previous actions. However, the state-of-the-art embodied agents often make mistakes in navigating the environment and interacting with proper objects due to imperfect learning by imitating experts or algorithmic planners without such knowledge. To improve both visual navigation and object interaction, we propose to consider the consequence of taken actions by CAPEAM (Context-Aware Planning and Environment-Aware Memory) that incorporates semantic context (e.g., appropriate objects to interact with) in a sequence of actions, and the changed spatial arrangement and states of interacted objects (e.g., location that the object has been moved to) in inferring the subsequent actions. We empirically show that the agent with the proposed CAPEAM achieves state-of-the-art performance in various metrics using a challenging interactive instruction following benchmark in both seen and unseen environments by large margins (up to +10.70% in unseen env.).


Geospatial Mechanistic Interpretability of Large Language Models
Large Language Models (LLMs) have demonstrated unprecedented capabilities across various natural language processing tasks. Their ability to process and generate viable text and code has made them ubiquitous in many fields, while their deployment as knowledge bases and "reasoning" tools remains an area of ongoing research. In geography, a growing body of literature has been focusing on evaluating LLMs' geographical knowledge and their ability to perform spatial reasoning. However, very little is still known about the internal functioning of these models, especially about how they process geographical information. In this chapter, we establish a novel framework for the study of geospatial mechanistic interpretability - using spatial analysis to reverse engineer how LLMs handle geographical information. Our aim is to advance our understanding of the internal representations that these complex models generate while processing geographical information - what one might call "how LLMs think about geographic information" if such phrasing was not an undue anthropomorphism. We first outline the use of probing in revealing internal structures within LLMs. We then introduce the field of mechanistic interpretability, discussing the superposition hypothesis and the role of sparse autoencoders in disentangling polysemantic internal representations of LLMs into more interpretable, monosemantic features. In our experiments, we use spatial autocorrelation to show how features obtained for placenames display spatial patterns related to their geographic location and can thus be interpreted geospatially, providing insights into how these models process geographical information. We conclude by discussing how our framework can help shape the study and use of foundation models in geography.

Context Engineering for Trustworthiness: Rescorla Wagner Steering Under Mixed and Inappropriate Contexts
Incorporating external context can significantly enhance the response quality of Large Language Models (LLMs). However, real-world contexts often mix relevant information with disproportionate inappropriate content, posing reliability risks. How do LLMs process and prioritize mixed context? To study this, we introduce the Poisoned Context Testbed, pairing queries with real-world contexts containing relevant and inappropriate content. Inspired by associative learning in animals, we adapt the Rescorla-Wagner (RW) model from neuroscience to quantify how competing contextual signals influence LLM outputs. Our adapted model reveals a consistent behavioral pattern: LLMs exhibit a strong tendency to incorporate information that is less prevalent in the context. This susceptibility is harmful in real-world settings, where small amounts of inappropriate content can substantially degrade response quality. Empirical evaluations on our testbed further confirm this vulnerability. To tackle this, we introduce RW-Steering, a two-stage finetuning-based approach that enables the model to internally identify and ignore inappropriate signals. Unlike prior methods that rely on extensive supervision across diverse context mixtures, RW-Steering generalizes robustly across varying proportions of inappropriate content. Experiments show that our best fine-tuned model improves response quality by 39.8% and reverses the undesirable behavior curve, establishing RW-Steering as a robust, generalizable context engineering solution for improving LLM safety in real-world use.


ImageGen-CoT: Enhancing Text-to-Image In-context Learning with Chain-of-Thought Reasoning
In this work, we study the problem of Text-to-Image In-Context Learning (T2I-ICL). While Unified Multimodal LLMs (MLLMs) have advanced rapidly in recent years, they struggle with contextual reasoning in T2I-ICL scenarios. To address this limitation, we propose a novel framework that incorporates a thought process called ImageGen-CoT prior to image generation. To avoid generating unstructured ineffective reasoning steps, we develop an automatic pipeline to curate a high-quality ImageGen-CoT dataset. We then fine-tune MLLMs using this dataset to enhance their contextual reasoning capabilities. To further enhance performance, we explore test-time scale-up strategies and propose a novel hybrid scaling approach. This approach first generates multiple ImageGen-CoT chains and then produces multiple images for each chain via sampling. Extensive experiments demonstrate the effectiveness of our proposed method. Notably, fine-tuning with the ImageGen-CoT dataset leads to a substantial 80\% performance gain for SEED-X on T2I-ICL tasks. See our project page at https://ImageGen-CoT.github.io/. Code and model weights will be open-sourced.


Mixture-of-Experts Meets In-Context Reinforcement Learning
In-context reinforcement learning (ICRL) has emerged as a promising paradigm for adapting RL agents to downstream tasks through prompt conditioning. However, two notable challenges remain in fully harnessing in-context learning within RL domains: the intrinsic multi-modality of the state-action-reward data and the diverse, heterogeneous nature of decision tasks. To tackle these challenges, we propose T2MIR (Token- and Task-wise MoE for In-context RL), an innovative framework that introduces architectural advances of mixture-of-experts (MoE) into transformer-based decision models. T2MIR substitutes the feedforward layer with two parallel layers: a token-wise MoE that captures distinct semantics of input tokens across multiple modalities, and a task-wise MoE that routes diverse tasks to specialized experts for managing a broad task distribution with alleviated gradient conflicts. To enhance task-wise routing, we introduce a contrastive learning method that maximizes the mutual information between the task and its router representation, enabling more precise capture of task-relevant information. The outputs of two MoE components are concatenated and fed into the next layer. Comprehensive experiments show that T2MIR significantly facilitates in-context learning capacity and outperforms various types of baselines. We bring the potential and promise of MoE to ICRL, offering a simple and scalable architectural enhancement to advance ICRL one step closer toward achievements in language and vision communities. Our code is available at https://github.com/NJU-RL/T2MIR.


VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.

Zero-Shot Clinical Acronym Expansion via Latent Meaning Cells
We introduce Latent Meaning Cells, a deep latent variable model which learns contextualized representations of words by combining local lexical context and metadata. Metadata can refer to granular context, such as section type, or to more global context, such as unique document ids. Reliance on metadata for contextualized representation learning is apropos in the clinical domain where text is semi-structured and expresses high variation in topics. We evaluate the LMC model on the task of zero-shot clinical acronym expansion across three datasets. The LMC significantly outperforms a diverse set of baselines at a fraction of the pre-training cost and learns clinically coherent representations. We demonstrate that not only is metadata itself very helpful for the task, but that the LMC inference algorithm provides an additional large benefit.

Kosmos-2: Grounding Multimodal Large Language Models to the World
We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent refer expressions as links in Markdown, i.e., ``[text span](bounding boxes)'', where object descriptions are sequences of location tokens. Together with multimodal corpora, we construct large-scale data of grounded image-text pairs (called GrIT) to train the model. In addition to the existing capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning), Kosmos-2 integrates the grounding capability into downstream applications. We evaluate Kosmos-2 on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension, and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This work lays out the foundation for the development of Embodiment AI and sheds light on the big convergence of language, multimodal perception, action, and world modeling, which is a key step toward artificial general intelligence. Data, demo, and pretrained models are available at https://aka.ms/kosmos-2.





Model Context Protocol for Vision Systems: Audit, Security, and Protocol Extensions
The Model Context Protocol (MCP) defines a schema bound execution model for agent-tool interaction, enabling modular computer vision workflows without retraining. To our knowledge, this is the first protocol level, deployment scale audit of MCP in vision systems, identifying systemic weaknesses in schema semantics, interoperability, and runtime coordination. We analyze 91 publicly registered vision centric MCP servers, annotated along nine dimensions of compositional fidelity, and develop an executable benchmark with validators to detect and categorize protocol violations. The audit reveals high prevalence of schema format divergence, missing runtime schema validation, undeclared coordinate conventions, and reliance on untracked bridging scripts. Validator based testing quantifies these failures, with schema format checks flagging misalignments in 78.0 percent of systems, coordinate convention checks detecting spatial reference errors in 24.6 percent, and memory scope checks issuing an average of 33.8 warnings per 100 executions. Security probes show that dynamic and multi agent workflows exhibit elevated risks of privilege escalation and untyped tool connections. The proposed benchmark and validator suite, implemented in a controlled testbed and to be released on GitHub, establishes a reproducible framework for measuring and improving the reliability and security of compositional vision workflows.

SpatialThinker: Reinforcing 3D Reasoning in Multimodal LLMs via Spatial Rewards
Multimodal large language models (MLLMs) have achieved remarkable progress in vision-language tasks, but they continue to struggle with spatial understanding. Existing spatial MLLMs often rely on explicit 3D inputs or architecture-specific modifications, and remain constrained by large-scale datasets or sparse supervision. To address these limitations, we introduce SpatialThinker, a 3D-aware MLLM trained with RL to integrate structured spatial grounding with multi-step reasoning. The model simulates human-like spatial perception by constructing a scene graph of task-relevant objects and spatial relations, and reasoning towards an answer via dense spatial rewards. SpatialThinker consists of two key contributions: (1) a data synthesis pipeline that generates STVQA-7K, a high-quality spatial VQA dataset, and (2) online RL with a multi-objective dense spatial reward enforcing spatial grounding. SpatialThinker-7B outperforms supervised fine-tuning and the sparse RL baseline on spatial understanding and real-world VQA benchmarks, nearly doubling the base-model gain compared to sparse RL, and surpassing GPT-4o. These results showcase the effectiveness of combining spatial supervision with reward-aligned reasoning in enabling robust 3D spatial understanding with limited data and advancing MLLMs towards human-level visual reasoning.

Retrieval-Augmented Decision Transformer: External Memory for In-context RL
In-context learning (ICL) is the ability of a model to learn a new task by observing a few exemplars in its context. While prevalent in NLP, this capability has recently also been observed in Reinforcement Learning (RL) settings. Prior in-context RL methods, however, require entire episodes in the agent's context. Given that complex environments typically lead to long episodes with sparse rewards, these methods are constrained to simple environments with short episodes. To address these challenges, we introduce Retrieval-Augmented Decision Transformer (RA-DT). RA-DT employs an external memory mechanism to store past experiences from which it retrieves only sub-trajectories relevant for the current situation. The retrieval component in RA-DT does not require training and can be entirely domain-agnostic. We evaluate the capabilities of RA-DT on grid-world environments, robotics simulations, and procedurally-generated video games. On grid-worlds, RA-DT outperforms baselines, while using only a fraction of their context length. Furthermore, we illuminate the limitations of current in-context RL methods on complex environments and discuss future directions. To facilitate future research, we release datasets for four of the considered environments.




LOOM-Scope: a comprehensive and efficient LOng-cOntext Model evaluation framework
Long-context processing has become a fundamental capability for large language models~(LLMs). To assess model's long-context performance, numerous long-context evaluation benchmarks have been proposed. However, variations in evaluation settings across these benchmarks lead to inconsistent results, making it difficult to draw reliable comparisons. Besides, the high computational cost of long-context evaluation poses a significant barrier for the community to conduct comprehensive assessments of long-context models. In this paper, we propose LOOM-Scope, a comprehensive and efficient framework for long-context evaluation. LOOM-Scope standardizes evaluation settings across diverse benchmarks, supports deployment of efficient long-context inference acceleration methods, and introduces a holistic yet lightweight benchmark suite to evaluate models comprehensively. Homepage: https://loomscope.github.io



Spatial-Temporal-Decoupled Masked Pre-training for Spatiotemporal Forecasting
Spatiotemporal forecasting techniques are significant for various domains such as transportation, energy, and weather. Accurate prediction of spatiotemporal series remains challenging due to the complex spatiotemporal heterogeneity. In particular, current end-to-end models are limited by input length and thus often fall into spatiotemporal mirage, i.e., similar input time series followed by dissimilar future values and vice versa. To address these problems, we propose a novel self-supervised pre-training framework Spatial-Temporal-Decoupled Masked Pre-training (STD-MAE) that employs two decoupled masked autoencoders to reconstruct spatiotemporal series along the spatial and temporal dimensions. Rich-context representations learned through such reconstruction could be seamlessly integrated by downstream predictors with arbitrary architectures to augment their performances. A series of quantitative and qualitative evaluations on six widely used benchmarks (PEMS03, PEMS04, PEMS07, PEMS08, METR-LA, and PEMS-BAY) are conducted to validate the state-of-the-art performance of STD-MAE. Codes are available at https://github.com/Jimmy-7664/STD-MAE.

Unlocking Spatial Comprehension in Text-to-Image Diffusion Models
We propose CompFuser, an image generation pipeline that enhances spatial comprehension and attribute assignment in text-to-image generative models. Our pipeline enables the interpretation of instructions defining spatial relationships between objects in a scene, such as `An image of a gray cat on the left of an orange dog', and generate corresponding images. This is especially important in order to provide more control to the user. CompFuser overcomes the limitation of existing text-to-image diffusion models by decoding the generation of multiple objects into iterative steps: first generating a single object and then editing the image by placing additional objects in their designated positions. To create training data for spatial comprehension and attribute assignment we introduce a synthetic data generation process, that leverages a frozen large language model and a frozen layout-based diffusion model for object placement. We compare our approach to strong baselines and show that our model outperforms state-of-the-art image generation models in spatial comprehension and attribute assignment, despite being 3x to 5x smaller in parameters.

MMICL: Empowering Vision-language Model with Multi-Modal In-Context Learning
Starting from the resurgence of deep learning, vision-language models (VLMs) benefiting from large language models (LLMs) have never been so popular. However, while LLMs can utilize extensive background knowledge and task information with in-context learning, most VLMs still struggle with understanding complex multi-modal prompts with multiple images. The issue can traced back to the architectural design of VLMs or pre-training data. Specifically, the current VLMs primarily emphasize utilizing multi-modal data with a single image some, rather than multi-modal prompts with interleaved multiple images and text. Even though some newly proposed VLMs could handle user prompts with multiple images, pre-training data does not provide more sophisticated multi-modal prompts than interleaved image and text crawled from the web. We propose MMICL to address the issue by considering both the model and data perspectives. We introduce a well-designed architecture capable of seamlessly integrating visual and textual context in an interleaved manner and MIC dataset to reduce the gap between the training data and the complex user prompts in real-world applications, including: 1) multi-modal context with interleaved images and text, 2) textual references for each image, and 3) multi-image data with spatial, logical, or temporal relationships. Our experiments confirm that MMICL achieves new stat-of-the-art zero-shot and few-shot performance on a wide range of general vision-language tasks, especially for complex reasoning benchmarks including MME and MMBench. Our analysis demonstrates that MMICL effectively deals with the challenge of complex multi-modal prompt understanding. The experiments on ScienceQA-IMG also show that MMICL successfully alleviates the issue of language bias in VLMs, which we believe is the reason behind the advanced performance of MMICL.




GeoVectors: A Linked Open Corpus of OpenStreetMap Embeddings on World Scale
OpenStreetMap (OSM) is currently the richest publicly available information source on geographic entities (e.g., buildings and roads) worldwide. However, using OSM entities in machine learning models and other applications is challenging due to the large scale of OSM, the extreme heterogeneity of entity annotations, and a lack of a well-defined ontology to describe entity semantics and properties. This paper presents GeoVectors - a unique, comprehensive world-scale linked open corpus of OSM entity embeddings covering the entire OSM dataset and providing latent representations of over 980 million geographic entities in 180 countries. The GeoVectors corpus captures semantic and geographic dimensions of OSM entities and makes these entities directly accessible to machine learning algorithms and semantic applications. We create a semantic description of the GeoVectors corpus, including identity links to the Wikidata and DBpedia knowledge graphs to supply context information. Furthermore, we provide a SPARQL endpoint - a semantic interface that offers direct access to the semantic and latent representations of geographic entities in OSM.
SpaceNLI: Evaluating the Consistency of Predicting Inferences in Space
While many natural language inference (NLI) datasets target certain semantic phenomena, e.g., negation, tense & aspect, monotonicity, and presupposition, to the best of our knowledge, there is no NLI dataset that involves diverse types of spatial expressions and reasoning. We fill this gap by semi-automatically creating an NLI dataset for spatial reasoning, called SpaceNLI. The data samples are automatically generated from a curated set of reasoning patterns, where the patterns are annotated with inference labels by experts. We test several SOTA NLI systems on SpaceNLI to gauge the complexity of the dataset and the system's capacity for spatial reasoning. Moreover, we introduce a Pattern Accuracy and argue that it is a more reliable and stricter measure than the accuracy for evaluating a system's performance on pattern-based generated data samples. Based on the evaluation results we find that the systems obtain moderate results on the spatial NLI problems but lack consistency per inference pattern. The results also reveal that non-projective spatial inferences (especially due to the "between" preposition) are the most challenging ones.
Unlocking Location Intelligence: A Survey from Deep Learning to The LLM Era
Location Intelligence (LI), the science of transforming location-centric geospatial data into actionable knowledge, has become a cornerstone of modern spatial decision-making. The rapid evolution of Geospatial Representation Learning is fundamentally reshaping LI development through two successive technological revolutions: the deep learning breakthrough and the emerging large language model (LLM) paradigm. While deep neural networks (DNNs) have demonstrated remarkable success in automated feature extraction from structured geospatial data (e.g., satellite imagery, GPS trajectories), the recent integration of LLMs introduces transformative capabilities for cross-modal geospatial reasoning and unstructured geo-textual data processing. This survey presents a comprehensive review of geospatial representation learning across both technological eras, organizing them into a structured taxonomy based on the complete pipeline comprising: (1) data perspective, (2) methodological perspective and (3) application perspective. We also highlight current advancements, discuss existing limitations, and propose potential future research directions in the LLM era. This work offers a thorough exploration of the field and providing a roadmap for further innovation in LI. The summary of the up-to-date paper list can be found in https://github.com/CityMind-Lab/Awesome-Location-Intelligence and will undergo continuous updates.

WonderJourney: Going from Anywhere to Everywhere
We introduce WonderJourney, a modularized framework for perpetual 3D scene generation. Unlike prior work on view generation that focuses on a single type of scenes, we start at any user-provided location (by a text description or an image) and generate a journey through a long sequence of diverse yet coherently connected 3D scenes. We leverage an LLM to generate textual descriptions of the scenes in this journey, a text-driven point cloud generation pipeline to make a compelling and coherent sequence of 3D scenes, and a large VLM to verify the generated scenes. We show compelling, diverse visual results across various scene types and styles, forming imaginary "wonderjourneys". Project website: https://kovenyu.com/WonderJourney/
VXP: Voxel-Cross-Pixel Large-scale Image-LiDAR Place Recognition
Cross-modal place recognition methods are flexible GPS-alternatives under varying environment conditions and sensor setups. However, this task is non-trivial since extracting consistent and robust global descriptors from different modalities is challenging. To tackle this issue, we propose Voxel-Cross-Pixel (VXP), a novel camera-to-LiDAR place recognition framework that enforces local similarities in a self-supervised manner and effectively brings global context from images and LiDAR scans into a shared feature space. Specifically, VXP is trained in three stages: first, we deploy a visual transformer to compactly represent input images. Secondly, we establish local correspondences between image-based and point cloud-based feature spaces using our novel geometric alignment module. We then aggregate local similarities into an expressive shared latent space. Extensive experiments on the three benchmarks (Oxford RobotCar, ViViD++ and KITTI) demonstrate that our method surpasses the state-of-the-art cross-modal retrieval by a large margin. Our evaluations show that the proposed method is accurate, efficient and light-weight. Our project page is available at: https://yunjinli.github.io/projects-vxp/

I Know About "Up"! Enhancing Spatial Reasoning in Visual Language Models Through 3D Reconstruction
Visual Language Models (VLMs) are essential for various tasks, particularly visual reasoning tasks, due to their robust multi-modal information integration, visual reasoning capabilities, and contextual awareness. However, existing ' visual spatial reasoning capabilities are often inadequate, struggling even with basic tasks such as distinguishing left from right. To address this, we propose the model, designed to enhance the visual spatial reasoning abilities of VLMS. ZeroVLM employs Zero-1-to-3, a 3D reconstruction model for obtaining different views of the input images and incorporates a prompting mechanism to further improve visual spatial reasoning. Experimental results on four visual spatial reasoning datasets show that our achieves up to 19.48% accuracy improvement, which indicates the effectiveness of the 3D reconstruction and prompting mechanisms of our ZeroVLM.

Is your VLM Sky-Ready? A Comprehensive Spatial Intelligence Benchmark for UAV Navigation
Vision-Language Models (VLMs), leveraging their powerful visual perception and reasoning capabilities, have been widely applied in Unmanned Aerial Vehicle (UAV) tasks. However, the spatial intelligence capabilities of existing VLMs in UAV scenarios remain largely unexplored, raising concerns about their effectiveness in navigating and interpreting dynamic environments. To bridge this gap, we introduce SpatialSky-Bench, a comprehensive benchmark specifically designed to evaluate the spatial intelligence capabilities of VLMs in UAV navigation. Our benchmark comprises two categories-Environmental Perception and Scene Understanding-divided into 13 subcategories, including bounding boxes, color, distance, height, and landing safety analysis, among others. Extensive evaluations of various mainstream open-source and closed-source VLMs reveal unsatisfactory performance in complex UAV navigation scenarios, highlighting significant gaps in their spatial capabilities. To address this challenge, we developed the SpatialSky-Dataset, a comprehensive dataset containing 1M samples with diverse annotations across various scenarios. Leveraging this dataset, we introduce Sky-VLM, a specialized VLM designed for UAV spatial reasoning across multiple granularities and contexts. Extensive experimental results demonstrate that Sky-VLM achieves state-of-the-art performance across all benchmark tasks, paving the way for the development of VLMs suitable for UAV scenarios. The source code is available at https://github.com/linglingxiansen/SpatialSKy.
LiveMCP-101: Stress Testing and Diagnosing MCP-enabled Agents on Challenging Queries
Tool calling has emerged as a critical capability for AI agents to interact with the real world and solve complex tasks. While the Model Context Protocol (MCP) provides a powerful standardized framework for tool integration, there is a significant gap in benchmarking how well AI agents can effectively solve multi-step tasks using diverse MCP tools in realistic, dynamic scenarios. In this work, we present LiveMCP-101, a benchmark of 101 carefully curated real-world queries, refined through iterative LLM rewriting and manual review, that require coordinated use of multiple MCP tools including web search, file operations, mathematical reasoning, and data analysis. Moreover, we introduce a novel evaluation approach that leverages ground-truth execution plans rather than raw API outputs, better reflecting the evolving nature of real-world environments. Experiments show that even frontier LLMs achieve a success rate below 60\%, highlighting major challenges in tool orchestration. Detailed ablations and error analysis further reveal distinct failure modes and inefficiencies in token usage, pointing to concrete directions for advancing current models. LiveMCP-101 sets a rigorous standard for evaluating real-world agent capabilities, advancing toward autonomous AI systems that reliably execute complex tasks through tool use.





Context Diffusion: In-Context Aware Image Generation
We propose Context Diffusion, a diffusion-based framework that enables image generation models to learn from visual examples presented in context. Recent work tackles such in-context learning for image generation, where a query image is provided alongside context examples and text prompts. However, the quality and fidelity of the generated images deteriorate when the prompt is not present, demonstrating that these models are unable to truly learn from the visual context. To address this, we propose a novel framework that separates the encoding of the visual context and preserving the structure of the query images. This results in the ability to learn from the visual context and text prompts, but also from either one of them. Furthermore, we enable our model to handle few-shot settings, to effectively address diverse in-context learning scenarios. Our experiments and user study demonstrate that Context Diffusion excels in both in-domain and out-of-domain tasks, resulting in an overall enhancement in image quality and fidelity compared to counterpart models.





Dual-View Visual Contextualization for Web Navigation
Automatic web navigation aims to build a web agent that can follow language instructions to execute complex and diverse tasks on real-world websites. Existing work primarily takes HTML documents as input, which define the contents and action spaces (i.e., actionable elements and operations) of webpages. Nevertheless, HTML documents may not provide a clear task-related context for each element, making it hard to select the right (sequence of) actions. In this paper, we propose to contextualize HTML elements through their "dual views" in webpage screenshots: each HTML element has its corresponding bounding box and visual content in the screenshot. We build upon the insight -- web developers tend to arrange task-related elements nearby on webpages to enhance user experiences -- and propose to contextualize each element with its neighbor elements, using both textual and visual features. The resulting representations of HTML elements are more informative for the agent to take action. We validate our method on the recently released Mind2Web dataset, which features diverse navigation domains and tasks on real-world websites. Our method consistently outperforms the baseline in all the scenarios, including cross-task, cross-website, and cross-domain ones.

Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Recent advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced performance on 2D visual tasks. However, improving their spatial intelligence remains a challenge. Existing 3D MLLMs always rely on additional 3D or 2.5D data to incorporate spatial awareness, restricting their utility in scenarios with only 2D inputs, such as images or videos. In this paper, we present Spatial-MLLM, a novel framework for visual-based spatial reasoning from purely 2D observations. Unlike conventional video MLLMs which rely on CLIP-based visual encoders optimized for semantic understanding, our key insight is to unleash the strong structure prior from the feed-forward visual geometry foundation model. Specifically, we propose a dual-encoder architecture: a pretrained 2D visual encoder to extract semantic features, and a spatial encoder-initialized from the backbone of the visual geometry model-to extract 3D structure features. A connector then integrates both features into unified visual tokens for enhanced spatial understanding. Furthermore, we propose a space-aware frame sampling strategy at inference time, which selects the spatially informative frames of a video sequence, ensuring that even under limited token length, the model focuses on frames critical for spatial reasoning. Beyond architecture improvements, we construct the Spatial-MLLM-120k dataset and train the model on it using supervised fine-tuning and GRPO. Extensive experiments on various real-world datasets demonstrate that our spatial-MLLM achieves state-of-the-art performance in a wide range of visual-based spatial understanding and reasoning tasks. Project page: https://diankun-wu.github.io/Spatial-MLLM/.
Experiences with Model Context Protocol Servers for Science and High Performance Computing
Large language model (LLM)-powered agents are increasingly used to plan and execute scientific workflows, yet most research cyberinfrastructure (CI) exposes heterogeneous APIs and implements security models that present barriers for use by agents. We report on our experience using the Model Context Protocol (MCP) as a unifying interface that makes research capabilities discoverable, invokable, and composable. Our approach is pragmatic: we implement thin MCP servers over mature services, including Globus Transfer, Compute, and Search; status APIs exposed by computing facilities; Octopus event fabric; and domain-specific tools such as Garden and Galaxy. We use case studies in computational chemistry, bioinformatics, quantum chemistry, and filesystem monitoring to illustrate how this MCP-oriented architecture can be used in practice. We distill lessons learned and outline open challenges in evaluation and trust for agent-led science.
ST-VLM: Kinematic Instruction Tuning for Spatio-Temporal Reasoning in Vision-Language Models
Spatio-temporal reasoning is essential in understanding real-world environments in various fields, eg, autonomous driving and sports analytics. Recent advances have improved the spatial reasoning ability of Vision-Language Models (VLMs) by introducing large-scale data, but these models still struggle to analyze kinematic elements like traveled distance and speed of moving objects. To bridge this gap, we construct a spatio-temporal reasoning dataset and benchmark involving kinematic instruction tuning, referred to as STKit and STKit-Bench. They consist of real-world videos with 3D annotations, detailing object motion dynamics: traveled distance, speed, movement direction, inter-object distance comparisons, and relative movement direction. To further scale such data construction to videos without 3D labels, we propose an automatic pipeline to generate pseudo-labels using 4D reconstruction in real-world scale. With our kinematic instruction tuning data for spatio-temporal reasoning, we present ST-VLM, a VLM enhanced for spatio-temporal reasoning, which exhibits outstanding performance on STKit-Bench. Furthermore, we show that ST-VLM generalizes robustly across diverse domains and tasks, outperforming baselines on other spatio-temporal benchmarks (eg, ActivityNet, TVQA+). Finally, by integrating learned spatio-temporal reasoning with existing abilities, ST-VLM enables complex multi-step reasoning. Project page: https://ikodoh.github.io/ST-VLM.


3D Highlighter: Localizing Regions on 3D Shapes via Text Descriptions
We present 3D Highlighter, a technique for localizing semantic regions on a mesh using text as input. A key feature of our system is the ability to interpret "out-of-domain" localizations. Our system demonstrates the ability to reason about where to place non-obviously related concepts on an input 3D shape, such as adding clothing to a bare 3D animal model. Our method contextualizes the text description using a neural field and colors the corresponding region of the shape using a probability-weighted blend. Our neural optimization is guided by a pre-trained CLIP encoder, which bypasses the need for any 3D datasets or 3D annotations. Thus, 3D Highlighter is highly flexible, general, and capable of producing localizations on a myriad of input shapes. Our code is publicly available at https://github.com/threedle/3DHighlighter.



StepGame: A New Benchmark for Robust Multi-Hop Spatial Reasoning in Texts
Inferring spatial relations in natural language is a crucial ability an intelligent system should possess. The bAbI dataset tries to capture tasks relevant to this domain (task 17 and 19). However, these tasks have several limitations. Most importantly, they are limited to fixed expressions, they are limited in the number of reasoning steps required to solve them, and they fail to test the robustness of models to input that contains irrelevant or redundant information. In this paper, we present a new Question-Answering dataset called StepGame for robust multi-hop spatial reasoning in texts. Our experiments demonstrate that state-of-the-art models on the bAbI dataset struggle on the StepGame dataset. Moreover, we propose a Tensor-Product based Memory-Augmented Neural Network (TP-MANN) specialized for spatial reasoning tasks. Experimental results on both datasets show that our model outperforms all the baselines with superior generalization and robustness performance.
SITE: towards Spatial Intelligence Thorough Evaluation
Spatial intelligence (SI) represents a cognitive ability encompassing the visualization, manipulation, and reasoning about spatial relationships, underpinning disciplines from neuroscience to robotics. We introduce SITE, a benchmark dataset towards SI Thorough Evaluation in a standardized format of multi-choice visual question-answering, designed to assess large vision-language models' spatial intelligence across diverse visual modalities (single-image, multi-image, and video) and SI factors (figural to environmental scales, spatial visualization and orientation, intrinsic and extrinsic, static and dynamic). Our approach to curating the benchmark combines a bottom-up survey about 31 existing datasets and a top-down strategy drawing upon three classification systems in cognitive science, which prompt us to design two novel types of tasks about view-taking and dynamic scenes. Extensive experiments reveal that leading models fall behind human experts especially in spatial orientation, a fundamental SI factor. Moreover, we demonstrate a positive correlation between a model's spatial reasoning proficiency and its performance on an embodied AI task.
Learning to Customize Text-to-Image Diffusion In Diverse Context
Most text-to-image customization techniques fine-tune models on a small set of personal concept images captured in minimal contexts. This often results in the model becoming overfitted to these training images and unable to generalize to new contexts in future text prompts. Existing customization methods are built on the success of effectively representing personal concepts as textual embeddings. Thus, in this work, we resort to diversifying the context of these personal concepts solely within the textual space by simply creating a contextually rich set of text prompts, together with a widely used self-supervised learning objective. Surprisingly, this straightforward and cost-effective method significantly improves semantic alignment in the textual space, and this effect further extends to the image space, resulting in higher prompt fidelity for generated images. Additionally, our approach does not require any architectural modifications, making it highly compatible with existing text-to-image customization methods. We demonstrate the broad applicability of our approach by combining it with four different baseline methods, achieving notable CLIP score improvements.
Incorporating Spatial Awareness in Data-Driven Gesture Generation for Virtual Agents
This paper focuses on enhancing human-agent communication by integrating spatial context into virtual agents' non-verbal behaviors, specifically gestures. Recent advances in co-speech gesture generation have primarily utilized data-driven methods, which create natural motion but limit the scope of gestures to those performed in a void. Our work aims to extend these methods by enabling generative models to incorporate scene information into speech-driven gesture synthesis. We introduce a novel synthetic gesture dataset tailored for this purpose. This development represents a critical step toward creating embodied conversational agents that interact more naturally with their environment and users.



XLand-100B: A Large-Scale Multi-Task Dataset for In-Context Reinforcement Learning
Following the success of the in-context learning paradigm in large-scale language and computer vision models, the recently emerging field of in-context reinforcement learning is experiencing a rapid growth. However, its development has been held back by the lack of challenging benchmarks, as all the experiments have been carried out in simple environments and on small-scale datasets. We present XLand-100B, a large-scale dataset for in-context reinforcement learning based on the XLand-MiniGrid environment, as a first step to alleviate this problem. It contains complete learning histories for nearly 30,000 different tasks, covering 100B transitions and 2.5B episodes. It took 50,000 GPU hours to collect the dataset, which is beyond the reach of most academic labs. Along with the dataset, we provide the utilities to reproduce or expand it even further. With this substantial effort, we aim to democratize research in the rapidly growing field of in-context reinforcement learning and provide a solid foundation for further scaling. The code is open-source and available under Apache 2.0 licence at https://github.com/dunno-lab/xland-minigrid-datasets.





SpaCE: The Spatial Confounding Environment
Spatial confounding poses a significant challenge in scientific studies involving spatial data, where unobserved spatial variables can influence both treatment and outcome, possibly leading to spurious associations. To address this problem, we introduce SpaCE: The Spatial Confounding Environment, the first toolkit to provide realistic benchmark datasets and tools for systematically evaluating causal inference methods designed to alleviate spatial confounding. Each dataset includes training data, true counterfactuals, a spatial graph with coordinates, and smoothness and confounding scores characterizing the effect of a missing spatial confounder. It also includes realistic semi-synthetic outcomes and counterfactuals, generated using state-of-the-art machine learning ensembles, following best practices for causal inference benchmarks. The datasets cover real treatment and covariates from diverse domains, including climate, health and social sciences. SpaCE facilitates an automated end-to-end pipeline, simplifying data loading, experimental setup, and evaluating machine learning and causal inference models. The SpaCE project provides several dozens of datasets of diverse sizes and spatial complexity. It is publicly available as a Python package, encouraging community feedback and contributions.
ImageRAG: Enhancing Ultra High Resolution Remote Sensing Imagery Analysis with ImageRAG
Ultra High Resolution (UHR) remote sensing imagery (RSI) (e.g. 100,000 times 100,000 pixels or more) poses a significant challenge for current Remote Sensing Multimodal Large Language Models (RSMLLMs). If choose to resize the UHR image to standard input image size, the extensive spatial and contextual information that UHR images contain will be neglected. Otherwise, the original size of these images often exceeds the token limits of standard RSMLLMs, making it difficult to process the entire image and capture long-range dependencies to answer the query based on the abundant visual context. In this paper, we introduce ImageRAG for RS, a training-free framework to address the complexities of analyzing UHR remote sensing imagery. By transforming UHR remote sensing image analysis task to image's long context selection task, we design an innovative image contextual retrieval mechanism based on the Retrieval-Augmented Generation (RAG) technique, denoted as ImageRAG. ImageRAG's core innovation lies in its ability to selectively retrieve and focus on the most relevant portions of the UHR image as visual contexts that pertain to a given query. Fast path and slow path are proposed in this framework to handle this task efficiently and effectively. ImageRAG allows RSMLLMs to manage extensive context and spatial information from UHR RSI, ensuring the analysis is both accurate and efficient. Codebase will be released in https://github.com/om-ai-lab/ImageRAG
RS-RAG: Bridging Remote Sensing Imagery and Comprehensive Knowledge with a Multi-Modal Dataset and Retrieval-Augmented Generation Model
Recent progress in VLMs has demonstrated impressive capabilities across a variety of tasks in the natural image domain. Motivated by these advancements, the remote sensing community has begun to adopt VLMs for remote sensing vision-language tasks, including scene understanding, image captioning, and visual question answering. However, existing remote sensing VLMs typically rely on closed-set scene understanding and focus on generic scene descriptions, yet lack the ability to incorporate external knowledge. This limitation hinders their capacity for semantic reasoning over complex or context-dependent queries that involve domain-specific or world knowledge. To address these challenges, we first introduced a multimodal Remote Sensing World Knowledge (RSWK) dataset, which comprises high-resolution satellite imagery and detailed textual descriptions for 14,141 well-known landmarks from 175 countries, integrating both remote sensing domain knowledge and broader world knowledge. Building upon this dataset, we proposed a novel Remote Sensing Retrieval-Augmented Generation (RS-RAG) framework, which consists of two key components. The Multi-Modal Knowledge Vector Database Construction module encodes remote sensing imagery and associated textual knowledge into a unified vector space. The Knowledge Retrieval and Response Generation module retrieves and re-ranks relevant knowledge based on image and/or text queries, and incorporates the retrieved content into a knowledge-augmented prompt to guide the VLM in producing contextually grounded responses. We validated the effectiveness of our approach on three representative vision-language tasks, including image captioning, image classification, and visual question answering, where RS-RAG significantly outperformed state-of-the-art baselines.
LongGenBench: Long-context Generation Benchmark
Current long-context benchmarks primarily focus on retrieval-based tests, requiring Large Language Models (LLMs) to locate specific information within extensive input contexts, such as the needle-in-a-haystack (NIAH) benchmark. Long-context generation refers to the ability of a language model to generate coherent and contextually accurate text that spans across lengthy passages or documents. While recent studies show strong performance on NIAH and other retrieval-based long-context benchmarks, there is a significant lack of benchmarks for evaluating long-context generation capabilities. To bridge this gap and offer a comprehensive assessment, we introduce a synthetic benchmark, LongGenBench, which allows for flexible configurations of customized generation context lengths. LongGenBench advances beyond traditional benchmarks by redesigning the format of questions and necessitating that LLMs respond with a single, cohesive long-context answer. Upon extensive evaluation using LongGenBench, we observe that: (1) both API accessed and open source models exhibit performance degradation in long-context generation scenarios, ranging from 1.2% to 47.1%; (2) different series of LLMs exhibit varying trends of performance degradation, with the Gemini-1.5-Flash model showing the least degradation among API accessed models, and the Qwen2 series exhibiting the least degradation in LongGenBench among open source models.




A Multi-Modal Context Reasoning Approach for Conditional Inference on Joint Textual and Visual Clues
Conditional inference on joint textual and visual clues is a multi-modal reasoning task that textual clues provide prior permutation or external knowledge, which are complementary with visual content and pivotal to deducing the correct option. Previous methods utilizing pretrained vision-language models (VLMs) have achieved impressive performances, yet they show a lack of multimodal context reasoning capability, especially for text-modal information. To address this issue, we propose a Multi-modal Context Reasoning approach, named ModCR. Compared to VLMs performing reasoning via cross modal semantic alignment, it regards the given textual abstract semantic and objective image information as the pre-context information and embeds them into the language model to perform context reasoning. Different from recent vision-aided language models used in natural language processing, ModCR incorporates the multi-view semantic alignment information between language and vision by introducing the learnable alignment prefix between image and text in the pretrained language model. This makes the language model well-suitable for such multi-modal reasoning scenario on joint textual and visual clues. We conduct extensive experiments on two corresponding data sets and experimental results show significantly improved performance (exact gain by 4.8% on PMR test set) compared to previous strong baselines. Code Link: https://github.com/YunxinLi/Multimodal-Context-Reasoning.

CARTIER: Cartographic lAnguage Reasoning Targeted at Instruction Execution for Robots
This work explores the capacity of large language models (LLMs) to address problems at the intersection of spatial planning and natural language interfaces for navigation.Our focus is on following relatively complex instructions that are more akin to natural conversation than traditional explicit procedural directives seen in robotics. Unlike most prior work, where navigation directives are provided as imperative commands (e.g., go to the fridge), we examine implicit directives within conversational interactions. We leverage the 3D simulator AI2Thor to create complex and repeatable scenarios at scale, and augment it by adding complex language queries for 40 object types. We demonstrate that a robot can better parse descriptive language queries than existing methods by using an LLM to interpret the user interaction in the context of a list of the objects in the scene.
G3: An Effective and Adaptive Framework for Worldwide Geolocalization Using Large Multi-Modality Models
Worldwide geolocalization aims to locate the precise location at the coordinate level of photos taken anywhere on the Earth. It is very challenging due to 1) the difficulty of capturing subtle location-aware visual semantics, and 2) the heterogeneous geographical distribution of image data. As a result, existing studies have clear limitations when scaled to a worldwide context. They may easily confuse distant images with similar visual contents, or cannot adapt to various locations worldwide with different amounts of relevant data. To resolve these limitations, we propose G3, a novel framework based on Retrieval-Augmented Generation (RAG). In particular, G3 consists of three steps, i.e., Geo-alignment, Geo-diversification, and Geo-verification to optimize both retrieval and generation phases of worldwide geolocalization. During Geo-alignment, our solution jointly learns expressive multi-modal representations for images, GPS and textual descriptions, which allows us to capture location-aware semantics for retrieving nearby images for a given query. During Geo-diversification, we leverage a prompt ensembling method that is robust to inconsistent retrieval performance for different image queries. Finally, we combine both retrieved and generated GPS candidates in Geo-verification for location prediction. Experiments on two well-established datasets IM2GPS3k and YFCC4k verify the superiority of G3 compared to other state-of-the-art methods.


LLplace: The 3D Indoor Scene Layout Generation and Editing via Large Language Model
Designing 3D indoor layouts is a crucial task with significant applications in virtual reality, interior design, and automated space planning. Existing methods for 3D layout design either rely on diffusion models, which utilize spatial relationship priors, or heavily leverage the inferential capabilities of proprietary Large Language Models (LLMs), which require extensive prompt engineering and in-context exemplars via black-box trials. These methods often face limitations in generalization and dynamic scene editing. In this paper, we introduce LLplace, a novel 3D indoor scene layout designer based on lightweight fine-tuned open-source LLM Llama3. LLplace circumvents the need for spatial relationship priors and in-context exemplars, enabling efficient and credible room layout generation based solely on user inputs specifying the room type and desired objects. We curated a new dialogue dataset based on the 3D-Front dataset, expanding the original data volume and incorporating dialogue data for adding and removing objects. This dataset can enhance the LLM's spatial understanding. Furthermore, through dialogue, LLplace activates the LLM's capability to understand 3D layouts and perform dynamic scene editing, enabling the addition and removal of objects. Our approach demonstrates that LLplace can effectively generate and edit 3D indoor layouts interactively and outperform existing methods in delivering high-quality 3D design solutions. Code and dataset will be released.

SpaCE-10: A Comprehensive Benchmark for Multimodal Large Language Models in Compositional Spatial Intelligence
Multimodal Large Language Models (MLLMs) have achieved remarkable progress in various multimodal tasks. To pursue higher intelligence in space, MLLMs require integrating multiple atomic spatial capabilities to handle complex and dynamic tasks. However, existing benchmarks struggle to comprehensively evaluate the spatial intelligence of common MLLMs from the atomic level to the compositional level. To fill this gap, we present SpaCE-10, a comprehensive benchmark for compositional spatial evaluations. In SpaCE-10, we define 10 atomic spatial capabilities, which are combined to form 8 compositional capabilities. Based on these definitions, we propose a novel hierarchical annotation pipeline to generate high-quality and diverse question-answer (QA) pairs. With over 150+ hours of human expert effort, we obtain over 5k QA pairs for 811 real indoor scenes in SpaCE-10, which covers various evaluation settings like point cloud input and multi-choice QA. We conduct an extensive evaluation of common MLLMs on SpaCE-10 and find that even the most advanced MLLM still lags behind humans by large margins. Through our careful study, we also draw several significant findings that benefit the MLLM community. For example, we reveal that the shortcoming of counting capability greatly limits the compositional spatial capabilities of existing MLLMs. The evaluation code and benchmark datasets are available at https://github.com/Cuzyoung/SpaCE-10.

Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
The Model Context Protocol (MCP) is a standardized interface designed to enable seamless interaction between AI models and external tools and resources, breaking down data silos and facilitating interoperability across diverse systems. This paper provides a comprehensive overview of MCP, focusing on its core components, workflow, and the lifecycle of MCP servers, which consists of three key phases: creation, operation, and update. We analyze the security and privacy risks associated with each phase and propose strategies to mitigate potential threats. The paper also examines the current MCP landscape, including its adoption by industry leaders and various use cases, as well as the tools and platforms supporting its integration. We explore future directions for MCP, highlighting the challenges and opportunities that will influence its adoption and evolution within the broader AI ecosystem. Finally, we offer recommendations for MCP stakeholders to ensure its secure and sustainable development as the AI landscape continues to evolve.
Lost in the Haystack: Smaller Needles are More Difficult for LLMs to Find
Large language models (LLMs) face significant challenges with needle-in-a-haystack tasks, where relevant information ("the needle") must be drawn from a large pool of irrelevant context ("the haystack"). Previous studies have highlighted positional bias and distractor quantity as critical factors affecting model performance, yet the influence of gold context size has received little attention. We address this gap by systematically studying how variations in gold context length impact LLM performance on long-context question answering tasks. Our experiments reveal that LLM performance drops sharply when the gold context is shorter, i.e., smaller gold contexts consistently degrade model performance and amplify positional sensitivity, posing a major challenge for agentic systems that must integrate scattered, fine-grained information of varying lengths. This pattern holds across three diverse domains (general knowledge, biomedical reasoning, and mathematical reasoning) and seven state-of-the-art LLMs of various sizes and architectures. Our work provides clear insights to guide the design of robust, context-aware LLM-driven systems.



Advancing Spatial Reasoning in Large Language Models: An In-Depth Evaluation and Enhancement Using the StepGame Benchmark
Artificial intelligence (AI) has made remarkable progress across various domains, with large language models like ChatGPT gaining substantial attention for their human-like text-generation capabilities. Despite these achievements, spatial reasoning remains a significant challenge for these models. Benchmarks like StepGame evaluate AI spatial reasoning, where ChatGPT has shown unsatisfactory performance. However, the presence of template errors in the benchmark has an impact on the evaluation results. Thus there is potential for ChatGPT to perform better if these template errors are addressed, leading to more accurate assessments of its spatial reasoning capabilities. In this study, we refine the StepGame benchmark, providing a more accurate dataset for model evaluation. We analyze GPT's spatial reasoning performance on the rectified benchmark, identifying proficiency in mapping natural language text to spatial relations but limitations in multi-hop reasoning. We provide a flawless solution to the benchmark by combining template-to-relation mapping with logic-based reasoning. This combination demonstrates proficiency in performing qualitative reasoning on StepGame without encountering any errors. We then address the limitations of GPT models in spatial reasoning. We deploy Chain-of-thought and Tree-of-thoughts prompting strategies, offering insights into GPT's ``cognitive process", and achieving remarkable improvements in accuracy. Our investigation not only sheds light on model deficiencies but also proposes enhancements, contributing to the advancement of AI with more robust spatial reasoning capabilities.
MutaGReP: Execution-Free Repository-Grounded Plan Search for Code-Use
When a human requests an LLM to complete a coding task using functionality from a large code repository, how do we provide context from the repo to the LLM? One approach is to add the entire repo to the LLM's context window. However, most tasks involve only fraction of symbols from a repo, longer contexts are detrimental to the LLM's reasoning abilities, and context windows are not unlimited. Alternatively, we could emulate the human ability to navigate a large repo, pick out the right functionality, and form a plan to solve the task. We propose MutaGReP (Mutation-guided Grounded Repository Plan Search), an approach to search for plans that decompose a user request into natural language steps grounded in the codebase. MutaGReP performs neural tree search in plan space, exploring by mutating plans and using a symbol retriever for grounding. On the challenging LongCodeArena benchmark, our plans use less than 5% of the 128K context window for GPT-4o but rival the coding performance of GPT-4o with a context window filled with the repo. Plans produced by MutaGReP allow Qwen 2.5 Coder 32B and 72B to match the performance of GPT-4o with full repo context and enable progress on the hardest LongCodeArena tasks. Project page: zaidkhan.me/MutaGReP


AnyHome: Open-Vocabulary Generation of Structured and Textured 3D Homes
Inspired by cognitive theories, we introduce AnyHome, a framework that translates any text into well-structured and textured indoor scenes at a house-scale. By prompting Large Language Models (LLMs) with designed templates, our approach converts provided textual narratives into amodal structured representations. These representations guarantee consistent and realistic spatial layouts by directing the synthesis of a geometry mesh within defined constraints. A Score Distillation Sampling process is then employed to refine the geometry, followed by an egocentric inpainting process that adds lifelike textures to it. AnyHome stands out with its editability, customizability, diversity, and realism. The structured representations for scenes allow for extensive editing at varying levels of granularity. Capable of interpreting texts ranging from simple labels to detailed narratives, AnyHome generates detailed geometries and textures that outperform existing methods in both quantitative and qualitative measures.
From reactive to cognitive: brain-inspired spatial intelligence for embodied agents
Spatial cognition enables adaptive goal-directed behavior by constructing internal models of space. Robust biological systems consolidate spatial knowledge into three interconnected forms: landmarks for salient cues, route knowledge for movement trajectories, and survey knowledge for map-like representations. While recent advances in multi-modal large language models (MLLMs) have enabled visual-language reasoning in embodied agents, these efforts lack structured spatial memory and instead operate reactively, limiting their generalization and adaptability in complex real-world environments. Here we present Brain-inspired Spatial Cognition for Navigation (BSC-Nav), a unified framework for constructing and leveraging structured spatial memory in embodied agents. BSC-Nav builds allocentric cognitive maps from egocentric trajectories and contextual cues, and dynamically retrieves spatial knowledge aligned with semantic goals. Integrated with powerful MLLMs, BSC-Nav achieves state-of-the-art efficacy and efficiency across diverse navigation tasks, demonstrates strong zero-shot generalization, and supports versatile embodied behaviors in the real physical world, offering a scalable and biologically grounded path toward general-purpose spatial intelligence.
MileBench: Benchmarking MLLMs in Long Context
Despite the advancements and impressive performance of Multimodal Large Language Models (MLLMs) on benchmarks, their effectiveness in real-world, long-context, and multi-image tasks is unclear due to the benchmarks' limited scope. Existing benchmarks often focus on single-image and short-text samples, and when assessing multi-image tasks, they either limit the image count or focus on specific task (e.g time-series captioning), potentially obscuring the performance challenges of MLLMs. To address these limitations, we introduce MileBench, a pioneering benchmark designed to test the MultImodal Long-contExt capabilities of MLLMs. This benchmark comprises not only multimodal long contexts, but also multiple tasks requiring both comprehension and generation. We establish two distinct evaluation sets, diagnostic and realistic, to systematically assess MLLMs' long-context adaptation capacity and their ability to complete tasks in long-context scenarios. Our experimental results, obtained from testing 20 models, revealed that while the closed-source GPT-4(Vision) and Gemini 1.5 outperform others, most open-source MLLMs struggle in long-context situations. Interestingly, the performance gap tends to widen with an increase in the number of images. We strongly encourage an intensification of research efforts towards enhancing MLLMs' long-context capabilities, especially in scenarios involving multiple images.



Spatio-Temporal Context Prompting for Zero-Shot Action Detection
Spatio-temporal action detection encompasses the tasks of localizing and classifying individual actions within a video. Recent works aim to enhance this process by incorporating interaction modeling, which captures the relationship between people and their surrounding context. However, these approaches have primarily focused on fully-supervised learning, and the current limitation lies in the lack of generalization capability to recognize unseen action categories. In this paper, we aim to adapt the pretrained image-language models to detect unseen actions. To this end, we propose a method which can effectively leverage the rich knowledge of visual-language models to perform Person-Context Interaction. Meanwhile, our Context Prompting module will utilize contextual information to prompt labels, thereby enhancing the generation of more representative text features. Moreover, to address the challenge of recognizing distinct actions by multiple people at the same timestamp, we design the Interest Token Spotting mechanism which employs pretrained visual knowledge to find each person's interest context tokens, and then these tokens will be used for prompting to generate text features tailored to each individual. To evaluate the ability to detect unseen actions, we propose a comprehensive benchmark on J-HMDB, UCF101-24, and AVA datasets. The experiments show that our method achieves superior results compared to previous approaches and can be further extended to multi-action videos, bringing it closer to real-world applications. The code and data can be found in https://webber2933.github.io/ST-CLIP-project-page.

Semantic-Aware Scene Recognition
Scene recognition is currently one of the top-challenging research fields in computer vision. This may be due to the ambiguity between classes: images of several scene classes may share similar objects, which causes confusion among them. The problem is aggravated when images of a particular scene class are notably different. Convolutional Neural Networks (CNNs) have significantly boosted performance in scene recognition, albeit it is still far below from other recognition tasks (e.g., object or image recognition). In this paper, we describe a novel approach for scene recognition based on an end-to-end multi-modal CNN that combines image and context information by means of an attention module. Context information, in the shape of semantic segmentation, is used to gate features extracted from the RGB image by leveraging on information encoded in the semantic representation: the set of scene objects and stuff, and their relative locations. This gating process reinforces the learning of indicative scene content and enhances scene disambiguation by refocusing the receptive fields of the CNN towards them. Experimental results on four publicly available datasets show that the proposed approach outperforms every other state-of-the-art method while significantly reducing the number of network parameters. All the code and data used along this paper is available at https://github.com/vpulab/Semantic-Aware-Scene-Recognition

Can Large Vision Language Models Read Maps Like a Human?
In this paper, we introduce MapBench-the first dataset specifically designed for human-readable, pixel-based map-based outdoor navigation, curated from complex path finding scenarios. MapBench comprises over 1600 pixel space map path finding problems from 100 diverse maps. In MapBench, LVLMs generate language-based navigation instructions given a map image and a query with beginning and end landmarks. For each map, MapBench provides Map Space Scene Graph (MSSG) as an indexing data structure to convert between natural language and evaluate LVLM-generated results. We demonstrate that MapBench significantly challenges state-of-the-art LVLMs both zero-shot prompting and a Chain-of-Thought (CoT) augmented reasoning framework that decomposes map navigation into sequential cognitive processes. Our evaluation of both open-source and closed-source LVLMs underscores the substantial difficulty posed by MapBench, revealing critical limitations in their spatial reasoning and structured decision-making capabilities. We release all the code and dataset in https://github.com/taco-group/MapBench.



Guiding Language Models of Code with Global Context using Monitors
Language models of code (LMs) work well when the surrounding code in the vicinity of generation provides sufficient context. This is not true when it becomes necessary to use types or functionality defined in another module or library, especially those not seen during training. LMs suffer from limited awareness of such global context and end up hallucinating, e.g., using types defined in other files incorrectly. Recent work tries to overcome this issue by retrieving global information to augment the local context. However, this bloats the prompt or requires architecture modifications and additional training. Integrated development environments (IDEs) assist developers by bringing the global context at their fingertips using static analysis. We extend this assistance, enjoyed by developers, to the LMs. We propose a notion of monitors that use static analysis in the background to guide the decoding. Unlike a priori retrieval, static analysis is invoked iteratively during the entire decoding process, providing the most relevant suggestions on demand. We demonstrate the usefulness of our proposal by monitoring for type-consistent use of identifiers whenever an LM generates code for object dereference. To evaluate our approach, we curate PragmaticCode, a dataset of open-source projects with their development environments. On models of varying parameter scale, we show that monitor-guided decoding consistently improves the ability of an LM to not only generate identifiers that match the ground truth but also improves compilation rates and agreement with ground truth. We find that LMs with fewer parameters, when guided with our monitor, can outperform larger LMs. With monitor-guided decoding, SantaCoder-1.1B achieves better compilation rate and next-identifier match than the much larger text-davinci-003 model. The datasets and code will be released at https://aka.ms/monitors4codegen .



Spatial Knowledge Graph-Guided Multimodal Synthesis
Recent advances in multimodal large language models (MLLMs) have significantly enhanced their capabilities; however, their spatial perception abilities remain a notable limitation. To address this challenge, multimodal data synthesis offers a promising solution. Yet, ensuring that synthesized data adhere to spatial common sense is a non-trivial task. In this work, we introduce SKG2Data, a novel multimodal synthesis approach guided by spatial knowledge graphs, grounded in the concept of knowledge-to-data generation. SKG2Data automatically constructs a Spatial Knowledge Graph (SKG) to emulate human-like perception of spatial directions and distances, which is subsequently utilized to guide multimodal data synthesis. Extensive experiments demonstrate that data synthesized from diverse types of spatial knowledge, including direction and distance, not only enhance the spatial perception and reasoning abilities of MLLMs but also exhibit strong generalization capabilities. We hope that the idea of knowledge-based data synthesis can advance the development of spatial intelligence.

DeCLIP: Decoupled Learning for Open-Vocabulary Dense Perception
Dense visual prediction tasks have been constrained by their reliance on predefined categories, limiting their applicability in real-world scenarios where visual concepts are unbounded. While Vision-Language Models (VLMs) like CLIP have shown promise in open-vocabulary tasks, their direct application to dense prediction often leads to suboptimal performance due to limitations in local feature representation. In this work, we present our observation that CLIP's image tokens struggle to effectively aggregate information from spatially or semantically related regions, resulting in features that lack local discriminability and spatial consistency. To address this issue, we propose DeCLIP, a novel framework that enhances CLIP by decoupling the self-attention module to obtain ``content'' and ``context'' features respectively. The ``content'' features are aligned with image crop representations to improve local discriminability, while ``context'' features learn to retain the spatial correlations under the guidance of vision foundation models, such as DINO. Extensive experiments demonstrate that DeCLIP significantly outperforms existing methods across multiple open-vocabulary dense prediction tasks, including object detection and semantic segmentation. Code is available at magenta{https://github.com/xiaomoguhz/DeCLIP}.




Link-Context Learning for Multimodal LLMs
The ability to learn from context with novel concepts, and deliver appropriate responses are essential in human conversations. Despite current Multimodal Large Language Models (MLLMs) and Large Language Models (LLMs) being trained on mega-scale datasets, recognizing unseen images or understanding novel concepts in a training-free manner remains a challenge. In-Context Learning (ICL) explores training-free few-shot learning, where models are encouraged to ``learn to learn" from limited tasks and generalize to unseen tasks. In this work, we propose link-context learning (LCL), which emphasizes "reasoning from cause and effect" to augment the learning capabilities of MLLMs. LCL goes beyond traditional ICL by explicitly strengthening the causal relationship between the support set and the query set. By providing demonstrations with causal links, LCL guides the model to discern not only the analogy but also the underlying causal associations between data points, which empowers MLLMs to recognize unseen images and understand novel concepts more effectively. To facilitate the evaluation of this novel approach, we introduce the ISEKAI dataset, comprising exclusively of unseen generated image-label pairs designed for link-context learning. Extensive experiments show that our LCL-MLLM exhibits strong link-context learning capabilities to novel concepts over vanilla MLLMs. Code and data will be released at https://github.com/isekai-portal/Link-Context-Learning.





Scaling Spatial Intelligence with Multimodal Foundation Models
Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.

Embedding-to-Prefix: Parameter-Efficient Personalization for Pre-Trained Large Language Models
Large language models (LLMs) excel at generating contextually relevant content. However, tailoring these outputs to individual users for effective personalization is a significant challenge. While rich user-specific information often exists as pre-existing user representations, such as embeddings learned from preferences or behaviors, current methods to leverage these for LLM personalization typically require costly fine-tuning or token-heavy prompting. We propose Embedding-to-Prefix (E2P), a parameter-efficient method that injects pre-computed context embeddings into an LLM's hidden representation space through a learned projection to a single soft token prefix. This enables effective personalization while keeping the backbone model frozen and avoiding expensive adaptation techniques. We evaluate E2P across two public datasets and in a production setting: dialogue personalization on Persona-Chat, contextual headline generation on PENS, and large-scale personalization for music and podcast consumption. Results show that E2P preserves contextual signals and achieves strong performance with minimal computational overhead, offering a scalable, efficient solution for contextualizing generative AI systems.

OmniGeo: Towards a Multimodal Large Language Models for Geospatial Artificial Intelligence
The rapid advancement of multimodal large language models (LLMs) has opened new frontiers in artificial intelligence, enabling the integration of diverse large-scale data types such as text, images, and spatial information. In this paper, we explore the potential of multimodal LLMs (MLLM) for geospatial artificial intelligence (GeoAI), a field that leverages spatial data to address challenges in domains including Geospatial Semantics, Health Geography, Urban Geography, Urban Perception, and Remote Sensing. We propose a MLLM (OmniGeo) tailored to geospatial applications, capable of processing and analyzing heterogeneous data sources, including satellite imagery, geospatial metadata, and textual descriptions. By combining the strengths of natural language understanding and spatial reasoning, our model enhances the ability of instruction following and the accuracy of GeoAI systems. Results demonstrate that our model outperforms task-specific models and existing LLMs on diverse geospatial tasks, effectively addressing the multimodality nature while achieving competitive results on the zero-shot geospatial tasks. Our code will be released after publication.
Se^2: Sequential Example Selection for In-Context Learning
The remarkable capability of large language models (LLMs) for in-context learning (ICL) needs to be activated by demonstration examples. Prior work has extensively explored the selection of examples for ICL, predominantly following the "select then organize" paradigm, such approaches often neglect the internal relationships between examples and exist an inconsistency between the training and inference. In this paper, we formulate the problem as a sequential selection problem and introduce Se^2, a sequential-aware method that leverages the LLM's feedback on varying context, aiding in capturing inter-relationships and sequential information among examples, significantly enriching the contextuality and relevance of ICL prompts. Meanwhile, we utilize beam search to seek and construct example sequences, enhancing both quality and diversity. Extensive experiments across 23 NLP tasks from 8 distinct categories illustrate that Se^2 markedly surpasses competitive baselines and achieves 42% relative improvement over random selection. Further in-depth analysis show the effectiveness of proposed strategies, highlighting Se^2's exceptional stability and adaptability across various scenarios. Our code will be released to facilitate future research.

Imaginative World Modeling with Scene Graphs for Embodied Agent Navigation
Semantic navigation requires an agent to navigate toward a specified target in an unseen environment. Employing an imaginative navigation strategy that predicts future scenes before taking action, can empower the agent to find target faster. Inspired by this idea, we propose SGImagineNav, a novel imaginative navigation framework that leverages symbolic world modeling to proactively build a global environmental representation. SGImagineNav maintains an evolving hierarchical scene graphs and uses large language models to predict and explore unseen parts of the environment. While existing methods solely relying on past observations, this imaginative scene graph provides richer semantic context, enabling the agent to proactively estimate target locations. Building upon this, SGImagineNav adopts an adaptive navigation strategy that exploits semantic shortcuts when promising and explores unknown areas otherwise to gather additional context. This strategy continuously expands the known environment and accumulates valuable semantic contexts, ultimately guiding the agent toward the target. SGImagineNav is evaluated in both real-world scenarios and simulation benchmarks. SGImagineNav consistently outperforms previous methods, improving success rate to 65.4 and 66.8 on HM3D and HSSD, and demonstrating cross-floor and cross-room navigation in real-world environments, underscoring its effectiveness and generalizability.
InComeS: Integrating Compression and Selection Mechanisms into LLMs for Efficient Model Editing
Although existing model editing methods perform well in recalling exact edit facts, they often struggle in complex scenarios that require deeper semantic understanding rather than mere knowledge regurgitation. Leveraging the strong contextual reasoning abilities of large language models (LLMs), in-context learning (ICL) becomes a promising editing method by comprehending edit information through context encoding. However, this method is constrained by the limited context window of LLMs, leading to degraded performance and efficiency as the number of edits increases. To overcome this limitation, we propose InComeS, a flexible framework that enhances LLMs' ability to process editing contexts through explicit compression and selection mechanisms. Specifically, InComeS compresses each editing context into the key-value (KV) cache of a special gist token, enabling efficient handling of multiple edits without being restricted by the model's context window. Furthermore, specialized cross-attention modules are added to dynamically select the most relevant information from the gist pools, enabling adaptive and effective utilization of edit information. We conduct experiments on diverse model editing benchmarks with various editing formats, and the results demonstrate the effectiveness and efficiency of our method.
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
The rapid advancement of Large Multimodal Models (LMMs) for 2D images and videos has motivated extending these models to understand 3D scenes, aiming for human-like visual-spatial intelligence. Nevertheless, achieving deep spatial understanding comparable to human capabilities poses significant challenges in model encoding and data acquisition. Existing methods frequently depend on external depth sensors for geometry capture or utilize off-the-shelf algorithms for pre-constructing 3D maps, thereby limiting their scalability, especially with prevalent monocular video inputs and for time-sensitive applications. In this work, we introduce VLM-3R, a unified framework for Vision-Language Models (VLMs) that incorporates 3D Reconstructive instruction tuning. VLM-3R processes monocular video frames by employing a geometry encoder to derive implicit 3D tokens that represent spatial understanding. Leveraging our Spatial-Visual-View Fusion and over 200K curated 3D reconstructive instruction tuning question-answer (QA) pairs, VLM-3R effectively aligns real-world spatial context with language instructions. This enables monocular 3D spatial assistance and embodied reasoning. To facilitate the evaluation of temporal reasoning, we introduce the Vision-Spatial-Temporal Intelligence benchmark, featuring over 138.6K QA pairs across five distinct tasks focused on evolving spatial relationships. Extensive experiments demonstrate that our model, VLM-3R, not only facilitates robust visual-spatial reasoning but also enables the understanding of temporal 3D context changes, excelling in both accuracy and scalability.


Context is Environment
Two lines of work are taking the central stage in AI research. On the one hand, the community is making increasing efforts to build models that discard spurious correlations and generalize better in novel test environments. Unfortunately, the bitter lesson so far is that no proposal convincingly outperforms a simple empirical risk minimization baseline. On the other hand, large language models (LLMs) have erupted as algorithms able to learn in-context, generalizing on-the-fly to eclectic contextual circumstances that users enforce by means of prompting. In this paper, we argue that context is environment, and posit that in-context learning holds the key to better domain generalization. Via extensive theory and experiments, we show that paying attention to contextx2013x2013unlabeled examples as they arrivex2013x2013allows our proposed In-Context Risk Minimization (ICRM) algorithm to zoom-in on the test environment risk minimizer, leading to significant out-of-distribution performance improvements. From all of this, two messages are worth taking home. Researchers in domain generalization should consider environment as context, and harness the adaptive power of in-context learning. Researchers in LLMs should consider context as environment, to better structure data towards generalization.

Functional Map of the World
We present a new dataset, Functional Map of the World (fMoW), which aims to inspire the development of machine learning models capable of predicting the functional purpose of buildings and land use from temporal sequences of satellite images and a rich set of metadata features. The metadata provided with each image enables reasoning about location, time, sun angles, physical sizes, and other features when making predictions about objects in the image. Our dataset consists of over 1 million images from over 200 countries. For each image, we provide at least one bounding box annotation containing one of 63 categories, including a "false detection" category. We present an analysis of the dataset along with baseline approaches that reason about metadata and temporal views. Our data, code, and pretrained models have been made publicly available.
RepoFusion: Training Code Models to Understand Your Repository
Despite the huge success of Large Language Models (LLMs) in coding assistants like GitHub Copilot, these models struggle to understand the context present in the repository (e.g., imports, parent classes, files with similar names, etc.), thereby producing inaccurate code completions. This effect is more pronounced when using these assistants for repositories that the model has not seen during training, such as proprietary software or work-in-progress code projects. Recent work has shown the promise of using context from the repository during inference. In this work, we extend this idea and propose RepoFusion, a framework to train models to incorporate relevant repository context. Experiments on single-line code completion show that our models trained with repository context significantly outperform much larger code models as CodeGen-16B-multi (sim73times larger) and closely match the performance of the sim 70times larger StarCoderBase model that was trained with the Fill-in-the-Middle objective. We find these results to be a novel and compelling demonstration of the gains that training with repository context can bring. We carry out extensive ablation studies to investigate the impact of design choices such as context type, number of contexts, context length, and initialization within our framework. Lastly, we release Stack-Repo, a dataset of 200 Java repositories with permissive licenses and near-deduplicated files that are augmented with three types of repository contexts. Additionally, we are making available the code and trained checkpoints for our work. Our released resources can be found at https://huggingface.co/RepoFusion.




An Adaptive Deep RL Method for Non-Stationary Environments with Piecewise Stable Context
One of the key challenges in deploying RL to real-world applications is to adapt to variations of unknown environment contexts, such as changing terrains in robotic tasks and fluctuated bandwidth in congestion control. Existing works on adaptation to unknown environment contexts either assume the contexts are the same for the whole episode or assume the context variables are Markovian. However, in many real-world applications, the environment context usually stays stable for a stochastic period and then changes in an abrupt and unpredictable manner within an episode, resulting in a segment structure, which existing works fail to address. To leverage the segment structure of piecewise stable context in real-world applications, in this paper, we propose a \textbf{Segmented Context Belief Augmented Deep~(SeCBAD)} RL method. Our method can jointly infer the belief distribution over latent context with the posterior over segment length and perform more accurate belief context inference with observed data within the current context segment. The inferred belief context can be leveraged to augment the state, leading to a policy that can adapt to abrupt variations in context. We demonstrate empirically that SeCBAD can infer context segment length accurately and outperform existing methods on a toy grid world environment and Mujuco tasks with piecewise-stable context.

Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
Multi-modal models have achieved remarkable progress in recent years. Nevertheless, they continue to exhibit notable limitations in spatial understanding and reasoning, which are fundamental capabilities to achieving artificial general intelligence. With the recent release of GPT-5, allegedly the most powerful AI model to date, it is timely to examine where the leading models stand on the path toward spatial intelligence. First, we propose a comprehensive taxonomy of spatial tasks that unifies existing benchmarks and discuss the challenges in ensuring fair evaluation. We then evaluate state-of-the-art proprietary and open-source models on eight key benchmarks, at a cost exceeding one billion total tokens. Our empirical study reveals that (1) GPT-5 demonstrates unprecedented strength in spatial intelligence, yet (2) still falls short of human performance across a broad spectrum of tasks. Moreover, we (3) identify the more challenging spatial intelligence problems for multi-modal models, and (4) proprietary models do not exhibit a decisive advantage when facing the most difficult problems. In addition, we conduct a qualitative evaluation across a diverse set of scenarios that are intuitive for humans yet fail even the most advanced multi-modal models.

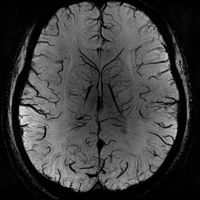

SpatialScore: Towards Unified Evaluation for Multimodal Spatial Understanding
Multimodal large language models (MLLMs) have achieved impressive success in question-answering tasks, yet their capabilities for spatial understanding are less explored. This work investigates a critical question: do existing MLLMs possess 3D spatial perception and understanding abilities? Concretely, we make the following contributions in this paper: (i) we introduce VGBench, a benchmark specifically designed to assess MLLMs for visual geometry perception, e.g., camera pose and motion estimation; (ii) we propose SpatialScore, the most comprehensive and diverse multimodal spatial understanding benchmark to date, integrating VGBench with relevant data from the other 11 existing datasets. This benchmark comprises 28K samples across various spatial understanding tasks, modalities, and QA formats, along with a carefully curated challenging subset, SpatialScore-Hard; (iii) we develop SpatialAgent, a novel multi-agent system incorporating 9 specialized tools for spatial understanding, supporting both Plan-Execute and ReAct reasoning paradigms; (iv) we conduct extensive evaluations to reveal persistent challenges in spatial reasoning while demonstrating the effectiveness of SpatialAgent. We believe SpatialScore will offer valuable insights and serve as a rigorous benchmark for the next evolution of MLLMs.


Benchmarking Spatial Relationships in Text-to-Image Generation
Spatial understanding is a fundamental aspect of computer vision and integral for human-level reasoning about images, making it an important component for grounded language understanding. While recent text-to-image synthesis (T2I) models have shown unprecedented improvements in photorealism, it is unclear whether they have reliable spatial understanding capabilities. We investigate the ability of T2I models to generate correct spatial relationships among objects and present VISOR, an evaluation metric that captures how accurately the spatial relationship described in text is generated in the image. To benchmark existing models, we introduce a dataset, SR_{2D}, that contains sentences describing two or more objects and the spatial relationships between them. We construct an automated evaluation pipeline to recognize objects and their spatial relationships, and employ it in a large-scale evaluation of T2I models. Our experiments reveal a surprising finding that, although state-of-the-art T2I models exhibit high image quality, they are severely limited in their ability to generate multiple objects or the specified spatial relations between them. Our analyses demonstrate several biases and artifacts of T2I models such as the difficulty with generating multiple objects, a bias towards generating the first object mentioned, spatially inconsistent outputs for equivalent relationships, and a correlation between object co-occurrence and spatial understanding capabilities. We conduct a human study that shows the alignment between VISOR and human judgement about spatial understanding. We offer the SR_{2D} dataset and the VISOR metric to the community in support of T2I reasoning research.
Multiverse of Greatness: Generating Story Branches with LLMs
This paper presents Dynamic Context Prompting/Programming (DCP/P), a novel framework for interacting with LLMs to generate graph-based content with a dynamic context window history. While there is an existing study utilizing LLMs to generate a visual novel game, the previous study involved a manual process of output extraction and did not provide flexibility in generating a longer, coherent story. We evaluate DCP/P against our baseline, which does not provide context history to an LLM and only relies on the initial story data. Through objective evaluation, we show that simply providing the LLM with a summary leads to a subpar story compared to additionally providing the LLM with the proper context of the story. We also provide an extensive qualitative analysis and discussion. We qualitatively examine the quality of the objectively best-performing generated game from each approach. In addition, we examine biases in word choices and word sentiment of the generated content. We find a consistent observation with previous studies that LLMs are biased towards certain words, even with a different LLM family. Finally, we provide a comprehensive discussion on opportunities for future studies.

Quantifying Spatial Audio Quality Impairment
Spatial audio quality is a highly multifaceted concept, with many interactions between environmental, geometrical, anatomical, psychological, and contextual considerations. Methods for characterization or evaluation of the geometrical components of spatial audio quality, however, remain scarce, despite being perhaps the least subjective aspect of spatial audio quality to quantify. By considering interchannel time and level differences relative to a reference signal, it is possible to construct a signal model to isolate some of the spatial distortion. By using a combination of least-square optimization and heuristics, we propose a signal decomposition method to isolate the spatial error from a processed signal, in terms of interchannel gain leakages and changes in relative delays. This allows the computation of simple energy-ratio metrics, providing objective measures of spatial and non-spatial signal qualities, with minimal assumptions and no dataset dependency. Experiments demonstrate the robustness of the method against common spatial signal degradation introduced by, e.g., audio compression and music source separation. Implementation is available at https://github.com/karnwatcharasupat/spauq.


LEGO-Puzzles: How Good Are MLLMs at Multi-Step Spatial Reasoning?
Multi-step spatial reasoning entails understanding and reasoning about spatial relationships across multiple sequential steps, which is crucial for tackling complex real-world applications, such as robotic manipulation, autonomous navigation, and automated assembly. To assess how well current Multimodal Large Language Models (MLLMs) have acquired this fundamental capability, we introduce LEGO-Puzzles, a scalable benchmark designed to evaluate both spatial understanding and sequential reasoning in MLLMs through LEGO-based tasks. LEGO-Puzzles consists of 1,100 carefully curated visual question-answering (VQA) samples spanning 11 distinct tasks, ranging from basic spatial understanding to complex multi-step reasoning. Based on LEGO-Puzzles, we conduct a comprehensive evaluation of state-of-the-art MLLMs and uncover significant limitations in their spatial reasoning capabilities: even the most powerful MLLMs can answer only about half of the test cases, whereas human participants achieve over 90\% accuracy. In addition to VQA tasks, we evaluate MLLMs' abilities to generate LEGO images following assembly illustrations. Our experiments show that only Gemini-2.0-Flash and GPT-4o exhibit a limited ability to follow these instructions, while other MLLMs either replicate the input image or generate completely irrelevant outputs. Overall, LEGO-Puzzles exposes critical deficiencies in existing MLLMs' spatial understanding and sequential reasoning capabilities, and underscores the need for further advancements in multimodal spatial reasoning.




Instance-Level Semantic Maps for Vision Language Navigation
Humans have a natural ability to perform semantic associations with the surrounding objects in the environment. This allows them to create a mental map of the environment, allowing them to navigate on-demand when given linguistic instructions. A natural goal in Vision Language Navigation (VLN) research is to impart autonomous agents with similar capabilities. Recent works take a step towards this goal by creating a semantic spatial map representation of the environment without any labeled data. However, their representations are limited for practical applicability as they do not distinguish between different instances of the same object. In this work, we address this limitation by integrating instance-level information into spatial map representation using a community detection algorithm and utilizing word ontology learned by large language models (LLMs) to perform open-set semantic associations in the mapping representation. The resulting map representation improves the navigation performance by two-fold (233%) on realistic language commands with instance-specific descriptions compared to the baseline. We validate the practicality and effectiveness of our approach through extensive qualitative and quantitative experiments.


InternSpatial: A Comprehensive Dataset for Spatial Reasoning in Vision-Language Models
Recent benchmarks and datasets have been proposed to improve spatial reasoning in vision-language models (VLMs), yet existing open resources remain limited in scale, visual diversity, and instruction expressiveness. In this work, we introduce InternSpatial, the largest open-source dataset for spatial reasoning in VLMs, along with InternSpatial-Bench, a corresponding evaluation benchmark designed to assess spatial understanding under diverse instruction formats. InternSpatial comprises 12 million QA pairs spanning both single-view and multi-view settings, drawn from diverse visual environments and supporting 19 instruction formats that reflect varied query styles. For evaluation, we propose InternSpatial-Bench for single-view tasks and expand multi-view reasoning by introducing a novel rotation angle prediction task that has not been explored in prior work. Experimental results show that models trained on InternSpatial achieve 12.1% improvement on InternSpatial-Bench and 10.7% on VSI-Bench, while maintaining strong performance on general-purpose benchmarks. We hope these resources will support the development of spatially capable VLMs in practical applications such as robotics and embodied AI.
Can MLLMs Perform Text-to-Image In-Context Learning?
The evolution from Large Language Models (LLMs) to Multimodal Large Language Models (MLLMs) has spurred research into extending In-Context Learning (ICL) to its multimodal counterpart. Existing such studies have primarily concentrated on image-to-text ICL. However, the Text-to-Image ICL (T2I-ICL), with its unique characteristics and potential applications, remains underexplored. To address this gap, we formally define the task of T2I-ICL and present CoBSAT, the first T2I-ICL benchmark dataset, encompassing ten tasks. Utilizing our dataset to benchmark six state-of-the-art MLLMs, we uncover considerable difficulties MLLMs encounter in solving T2I-ICL. We identify the primary challenges as the inherent complexity of multimodality and image generation. To overcome these challenges, we explore strategies like fine-tuning and Chain-of-Thought prompting, demonstrating notable improvements. Our code and dataset are available at https://github.com/UW-Madison-Lee-Lab/CoBSAT.

Joint 2D-3D-Semantic Data for Indoor Scene Understanding
We present a dataset of large-scale indoor spaces that provides a variety of mutually registered modalities from 2D, 2.5D and 3D domains, with instance-level semantic and geometric annotations. The dataset covers over 6,000m2 and contains over 70,000 RGB images, along with the corresponding depths, surface normals, semantic annotations, global XYZ images (all in forms of both regular and 360{\deg} equirectangular images) as well as camera information. It also includes registered raw and semantically annotated 3D meshes and point clouds. The dataset enables development of joint and cross-modal learning models and potentially unsupervised approaches utilizing the regularities present in large-scale indoor spaces. The dataset is available here: http://3Dsemantics.stanford.edu/

Spatial 3D-LLM: Exploring Spatial Awareness in 3D Vision-Language Models
New era has unlocked exciting possibilities for extending Large Language Models (LLMs) to tackle 3D vision-language tasks. However, most existing 3D multimodal LLMs (MLLMs) rely on compressing holistic 3D scene information or segmenting independent objects to perform these tasks, which limits their spatial awareness due to insufficient representation of the richness inherent in 3D scenes. To overcome these limitations, we propose Spatial 3D-LLM, a 3D MLLM specifically designed to enhance spatial awareness for 3D vision-language tasks by enriching the spatial embeddings of 3D scenes. Spatial 3D-LLM integrates an LLM backbone with a progressive spatial awareness scheme that progressively captures spatial information as the perception field expands, generating location-enriched 3D scene embeddings to serve as visual prompts. Furthermore, we introduce two novel tasks: 3D object distance measurement and 3D layout editing, and construct a 3D instruction dataset, MODEL, to evaluate the model's spatial awareness capabilities. Experimental results demonstrate that Spatial 3D-LLM achieves state-of-the-art performance across a wide range of 3D vision-language tasks, revealing the improvements stemmed from our progressive spatial awareness scheme of mining more profound spatial information. Our code is available at https://github.com/bjshuyuan/Spatial-3D-LLM.
SpatialPrompting: Keyframe-driven Zero-Shot Spatial Reasoning with Off-the-Shelf Multimodal Large Language Models
This study introduces SpatialPrompting, a novel framework that harnesses the emergent reasoning capabilities of off-the-shelf multimodal large language models to achieve zero-shot spatial reasoning in three-dimensional (3D) environments. Unlike existing methods that rely on expensive 3D-specific fine-tuning with specialized 3D inputs such as point clouds or voxel-based features, SpatialPrompting employs a keyframe-driven prompt generation strategy. This framework uses metrics such as vision-language similarity, Mahalanobis distance, field of view, and image sharpness to select a diverse and informative set of keyframes from image sequences and then integrates them with corresponding camera pose data to effectively abstract spatial relationships and infer complex 3D structures. The proposed framework not only establishes a new paradigm for flexible spatial reasoning that utilizes intuitive visual and positional cues but also achieves state-of-the-art zero-shot performance on benchmark datasets, such as ScanQA and SQA3D, across several metrics. The proposed method effectively eliminates the need for specialized 3D inputs and fine-tuning, offering a simpler and more scalable alternative to conventional approaches.
Long Context is Not Long at All: A Prospector of Long-Dependency Data for Large Language Models
Long-context modeling capabilities are important for large language models (LLMs) in various applications. However, directly training LLMs with long context windows is insufficient to enhance this capability since some training samples do not exhibit strong semantic dependencies across long contexts. In this study, we propose a data mining framework ProLong that can assign each training sample with a long dependency score, which can be used to rank and filter samples that are more advantageous for enhancing long-context modeling abilities in LLM training. Specifically, we first use delta perplexity scores to measure the Dependency Strength between text segments in a given document. Then we refine this metric based on the Dependency Distance of these segments to incorporate spatial relationships across long-contexts. Final results are calibrated with a Dependency Specificity metric to prevent trivial dependencies introduced by repetitive patterns. Moreover, a random sampling approach is proposed to optimize the computational efficiency of ProLong. Comprehensive experiments on multiple benchmarks indicate that ProLong effectively identifies documents that carry long dependencies and LLMs trained on these documents exhibit significantly enhanced long-context modeling capabilities.



Charting New Territories: Exploring the Geographic and Geospatial Capabilities of Multimodal LLMs
Multimodal large language models (MLLMs) have shown remarkable capabilities across a broad range of tasks but their knowledge and abilities in the geographic and geospatial domains are yet to be explored, despite potential wide-ranging benefits to navigation, environmental research, urban development, and disaster response. We conduct a series of experiments exploring various vision capabilities of MLLMs within these domains, particularly focusing on the frontier model GPT-4V, and benchmark its performance against open-source counterparts. Our methodology involves challenging these models with a small-scale geographic benchmark consisting of a suite of visual tasks, testing their abilities across a spectrum of complexity. The analysis uncovers not only where such models excel, including instances where they outperform humans, but also where they falter, providing a balanced view of their capabilities in the geographic domain. To enable the comparison and evaluation of future models, our benchmark will be publicly released.

Can Transformers Capture Spatial Relations between Objects?
Spatial relationships between objects represent key scene information for humans to understand and interact with the world. To study the capability of current computer vision systems to recognize physically grounded spatial relations, we start by proposing precise relation definitions that permit consistently annotating a benchmark dataset. Despite the apparent simplicity of this task relative to others in the recognition literature, we observe that existing approaches perform poorly on this benchmark. We propose new approaches exploiting the long-range attention capabilities of transformers for this task, and evaluating key design principles. We identify a simple "RelatiViT" architecture and demonstrate that it outperforms all current approaches. To our knowledge, this is the first method to convincingly outperform naive baselines on spatial relation prediction in in-the-wild settings. The code and datasets are available in https://sites.google.com/view/spatial-relation.
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Spatial pyramid pooling module or encode-decoder structure are used in deep neural networks for semantic segmentation task. The former networks are able to encode multi-scale contextual information by probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information. In this work, we propose to combine the advantages from both methods. Specifically, our proposed model, DeepLabv3+, extends DeepLabv3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further explore the Xception model and apply the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network. We demonstrate the effectiveness of the proposed model on PASCAL VOC 2012 and Cityscapes datasets, achieving the test set performance of 89.0\% and 82.1\% without any post-processing. Our paper is accompanied with a publicly available reference implementation of the proposed models in Tensorflow at https://github.com/tensorflow/models/tree/master/research/deeplab.
Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
Long-context language models (LCLMs) have the potential to revolutionize our approach to tasks traditionally reliant on external tools like retrieval systems or databases. Leveraging LCLMs' ability to natively ingest and process entire corpora of information offers numerous advantages. It enhances user-friendliness by eliminating the need for specialized knowledge of tools, provides robust end-to-end modeling that minimizes cascading errors in complex pipelines, and allows for the application of sophisticated prompting techniques across the entire system. To assess this paradigm shift, we introduce LOFT, a benchmark of real-world tasks requiring context up to millions of tokens designed to evaluate LCLMs' performance on in-context retrieval and reasoning. Our findings reveal LCLMs' surprising ability to rival state-of-the-art retrieval and RAG systems, despite never having been explicitly trained for these tasks. However, LCLMs still face challenges in areas like compositional reasoning that are required in SQL-like tasks. Notably, prompting strategies significantly influence performance, emphasizing the need for continued research as context lengths grow. Overall, LOFT provides a rigorous testing ground for LCLMs, showcasing their potential to supplant existing paradigms and tackle novel tasks as model capabilities scale.


Making Text Embedders Few-Shot Learners
Large language models (LLMs) with decoder-only architectures demonstrate remarkable in-context learning (ICL) capabilities. This feature enables them to effectively handle both familiar and novel tasks by utilizing examples provided within their input context. Recognizing the potential of this capability, we propose leveraging the ICL feature in LLMs to enhance the process of text embedding generation. To this end, we introduce a novel model bge-en-icl, which employs few-shot examples to produce high-quality text embeddings. Our approach integrates task-related examples directly into the query side, resulting in significant improvements across various tasks. Additionally, we have investigated how to effectively utilize LLMs as embedding models, including various attention mechanisms, pooling methods, etc. Our findings suggest that retaining the original framework often yields the best results, underscoring that simplicity is best. Experimental results on the MTEB and AIR-Bench benchmarks demonstrate that our approach sets new state-of-the-art (SOTA) performance. Our model, code and dataset are freely available at https://github.com/FlagOpen/FlagEmbedding .


StreetViewAI: Making Street View Accessible Using Context-Aware Multimodal AI
Interactive streetscape mapping tools such as Google Street View (GSV) and Meta Mapillary enable users to virtually navigate and experience real-world environments via immersive 360{\deg} imagery but remain fundamentally inaccessible to blind users. We introduce StreetViewAI, the first-ever accessible street view tool, which combines context-aware, multimodal AI, accessible navigation controls, and conversational speech. With StreetViewAI, blind users can virtually examine destinations, engage in open-world exploration, or virtually tour any of the over 220 billion images and 100+ countries where GSV is deployed. We iteratively designed StreetViewAI with a mixed-visual ability team and performed an evaluation with eleven blind users. Our findings demonstrate the value of an accessible street view in supporting POI investigations and remote route planning. We close by enumerating key guidelines for future work.
Video Panels for Long Video Understanding
Recent Video-Language Models (VLMs) achieve promising results on long-video understanding, but their performance still lags behind that achieved on tasks involving images or short videos. This has led to great interest in improving the long context modeling of VLMs by introducing novel modules and additional complexity. % additional training time. In this paper, we take a different approach: rather than fine-tuning VLMs with the limited data available, we attempt to maximize the performance of existing models. To this end, we propose a novel visual prompting strategy specifically designed for long-video understanding. By combining multiple frames as panels into one image, we effectively trade off spatial details for temporal resolution. Our approach is training-free, parameter-free, and model-agnostic, and can be seamlessly integrated into existing VLMs. Extensive experiments on five established benchmarks across a wide range of model architectures, sizes, and context windows confirm the consistency of our approach. For the TimeScope (Long) dataset, which has the longest videos, the accuracy for video question answering is improved by up to 19.4\%. Overall, our method raises the bar for long video understanding models. We will make our code available upon acceptance.
Controllable Context Sensitivity and the Knob Behind It
When making predictions, a language model must trade off how much it relies on its context vs. its prior knowledge. Choosing how sensitive the model is to its context is a fundamental functionality, as it enables the model to excel at tasks like retrieval-augmented generation and question-answering. In this paper, we search for a knob which controls this sensitivity, determining whether language models answer from the context or their prior knowledge. To guide this search, we design a task for controllable context sensitivity. In this task, we first feed the model a context (Paris is in England) and a question (Where is Paris?); we then instruct the model to either use its prior or contextual knowledge and evaluate whether it generates the correct answer for both intents (either France or England). When fine-tuned on this task, instruction-tuned versions of Llama-3.1, Mistral-v0.3, and Gemma-2 can solve it with high accuracy (85-95%). Analyzing these high-performing models, we narrow down which layers may be important to context sensitivity using a novel linear time algorithm. Then, in each model, we identify a 1-D subspace in a single layer that encodes whether the model follows context or prior knowledge. Interestingly, while we identify this subspace in a fine-tuned model, we find that the exact same subspace serves as an effective knob in not only that model but also non-fine-tuned instruct and base models of that model family. Finally, we show a strong correlation between a model's performance and how distinctly it separates context-agreeing from context-ignoring answers in this subspace. These results suggest a single subspace facilitates how the model chooses between context and prior knowledge, hinting at a simple fundamental mechanism that controls this behavior.

Context Is What You Need: The Maximum Effective Context Window for Real World Limits of LLMs
Large language model (LLM) providers boast big numbers for maximum context window sizes. To test the real world use of context windows, we 1) define a concept of maximum effective context window, 2) formulate a testing method of a context window's effectiveness over various sizes and problem types, and 3) create a standardized way to compare model efficacy for increasingly larger context window sizes to find the point of failure. We collected hundreds of thousands of data points across several models and found significant differences between reported Maximum Context Window (MCW) size and Maximum Effective Context Window (MECW) size. Our findings show that the MECW is, not only, drastically different from the MCW but also shifts based on the problem type. A few top of the line models in our test group failed with as little as 100 tokens in context; most had severe degradation in accuracy by 1000 tokens in context. All models fell far short of their Maximum Context Window by as much as 99 percent. Our data reveals the Maximum Effective Context Window shifts based on the type of problem provided, offering clear and actionable insights into how to improve model accuracy and decrease model hallucination rates.

GeoSynth: Contextually-Aware High-Resolution Satellite Image Synthesis
We present GeoSynth, a model for synthesizing satellite images with global style and image-driven layout control. The global style control is via textual prompts or geographic location. These enable the specification of scene semantics or regional appearance respectively, and can be used together. We train our model on a large dataset of paired satellite imagery, with automatically generated captions, and OpenStreetMap data. We evaluate various combinations of control inputs, including different types of layout controls. Results demonstrate that our model can generate diverse, high-quality images and exhibits excellent zero-shot generalization. The code and model checkpoints are available at https://github.com/mvrl/GeoSynth.

SIMS-V: Simulated Instruction-Tuning for Spatial Video Understanding
Despite impressive high-level video comprehension, multimodal language models struggle with spatial reasoning across time and space. While current spatial training approaches rely on real-world video data, obtaining diverse footage with precise spatial annotations remains a bottleneck. To alleviate this bottleneck, we present SIMS-V -- a systematic data-generation framework that leverages the privileged information of 3D simulators to create spatially-rich video training data for multimodal language models. Using this framework, we investigate which properties of simulated data drive effective real-world transfer through systematic ablations of question types, mixes, and scales. We identify a minimal set of three question categories (metric measurement, perspective-dependent reasoning, and temporal tracking) that prove most effective for developing transferable spatial intelligence, outperforming comprehensive coverage despite using fewer question types. These insights enable highly efficient training: our 7B-parameter video LLM fine-tuned on just 25K simulated examples outperforms the larger 72B baseline and achieves competitive performance with proprietary models on rigorous real-world spatial reasoning benchmarks. Our approach demonstrates robust generalization, maintaining performance on general video understanding while showing substantial improvements on embodied and real-world spatial tasks.

Thus Spake Long-Context Large Language Model
Long context is an important topic in Natural Language Processing (NLP), running through the development of NLP architectures, and offers immense opportunities for Large Language Models (LLMs) giving LLMs the lifelong learning potential akin to humans. Unfortunately, the pursuit of a long context is accompanied by numerous obstacles. Nevertheless, long context remains a core competitive advantage for LLMs. In the past two years, the context length of LLMs has achieved a breakthrough extension to millions of tokens. Moreover, the research on long-context LLMs has expanded from length extrapolation to a comprehensive focus on architecture, infrastructure, training, and evaluation technologies. Inspired by the symphonic poem, Thus Spake Zarathustra, we draw an analogy between the journey of extending the context of LLM and the attempts of humans to transcend its mortality. In this survey, We will illustrate how LLM struggles between the tremendous need for a longer context and its equal need to accept the fact that it is ultimately finite. To achieve this, we give a global picture of the lifecycle of long-context LLMs from four perspectives: architecture, infrastructure, training, and evaluation, showcasing the full spectrum of long-context technologies. At the end of this survey, we will present 10 unanswered questions currently faced by long-context LLMs. We hope this survey can serve as a systematic introduction to the research on long-context LLMs.




SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.




Teaching VLMs to Localize Specific Objects from In-context Examples
Vision-Language Models (VLMs) have shown remarkable capabilities across diverse visual tasks, including image recognition, video understanding, and Visual Question Answering (VQA) when explicitly trained for these tasks. Despite these advances, we find that current VLMs lack a fundamental cognitive ability: learning to localize objects in a scene by taking into account the context. In this work, we focus on the task of few-shot personalized localization, where a model is given a small set of annotated images (in-context examples) -- each with a category label and bounding box -- and is tasked with localizing the same object type in a query image. To provoke personalized localization abilities in models, we present a data-centric solution that fine-tunes them using carefully curated data from video object tracking datasets. By leveraging sequences of frames tracking the same object across multiple shots, we simulate instruction-tuning dialogues that promote context awareness. To reinforce this, we introduce a novel regularization technique that replaces object labels with pseudo-names, ensuring the model relies on visual context rather than prior knowledge. Our method significantly enhances few-shot localization performance without sacrificing generalization, as demonstrated on several benchmarks tailored to personalized localization. This work is the first to explore and benchmark personalized few-shot localization for VLMs, laying a foundation for future research in context-driven vision-language applications. The code for our project is available at https://github.com/SivanDoveh/IPLoc

sMoRe: Enhancing Object Manipulation and Organization in Mixed Reality Spaces with LLMs and Generative AI
In mixed reality (MR) environments, understanding space and creating virtual objects is crucial to providing an intuitive and rich user experience. This paper introduces sMoRe (Spatial Mapping and Object Rendering Environment), an MR application that combines Generative AI (GenAI) with large language models (LLMs) to assist users in creating, placing, and managing virtual objects within physical spaces. sMoRe allows users to use voice or typed text commands to create and place virtual objects using GenAI while specifying spatial constraints. The system leverages LLMs to interpret users' commands, analyze the current scene, and identify optimal locations. Additionally, sMoRe integrates text-to-3D generative AI to dynamically create 3D objects based on users' descriptions. Our user study demonstrates the effectiveness of sMoRe in enhancing user comprehension, interaction, and organization of the MR environment.