|
|
| :--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
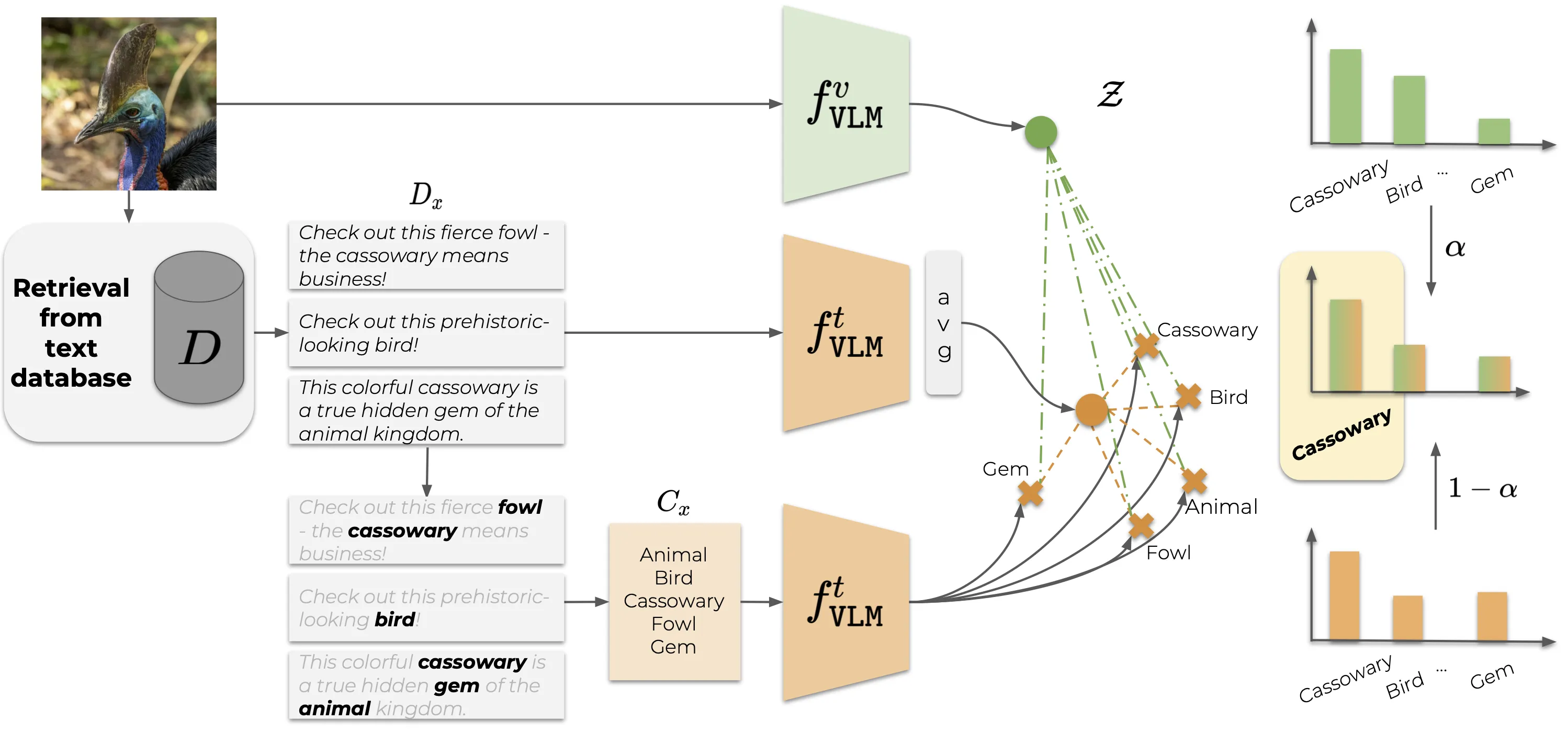
| Overview of CaSED. Given an input image, CaSED retrieves the most relevant captions from an external database filtering them to extract candidate categories. We classify image-to-text and text-to-text, using the retrieved captions centroid as the textual counterpart of the input image. |
 |
|  |
| :-----------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------: |
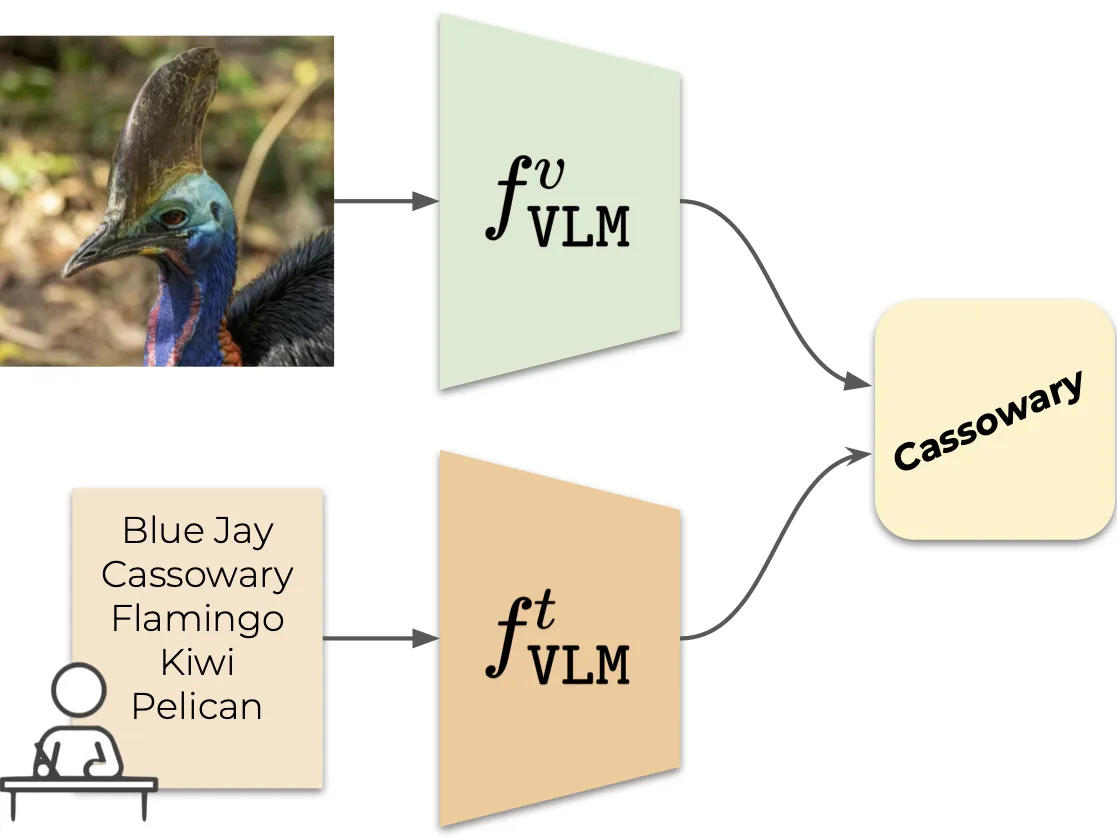
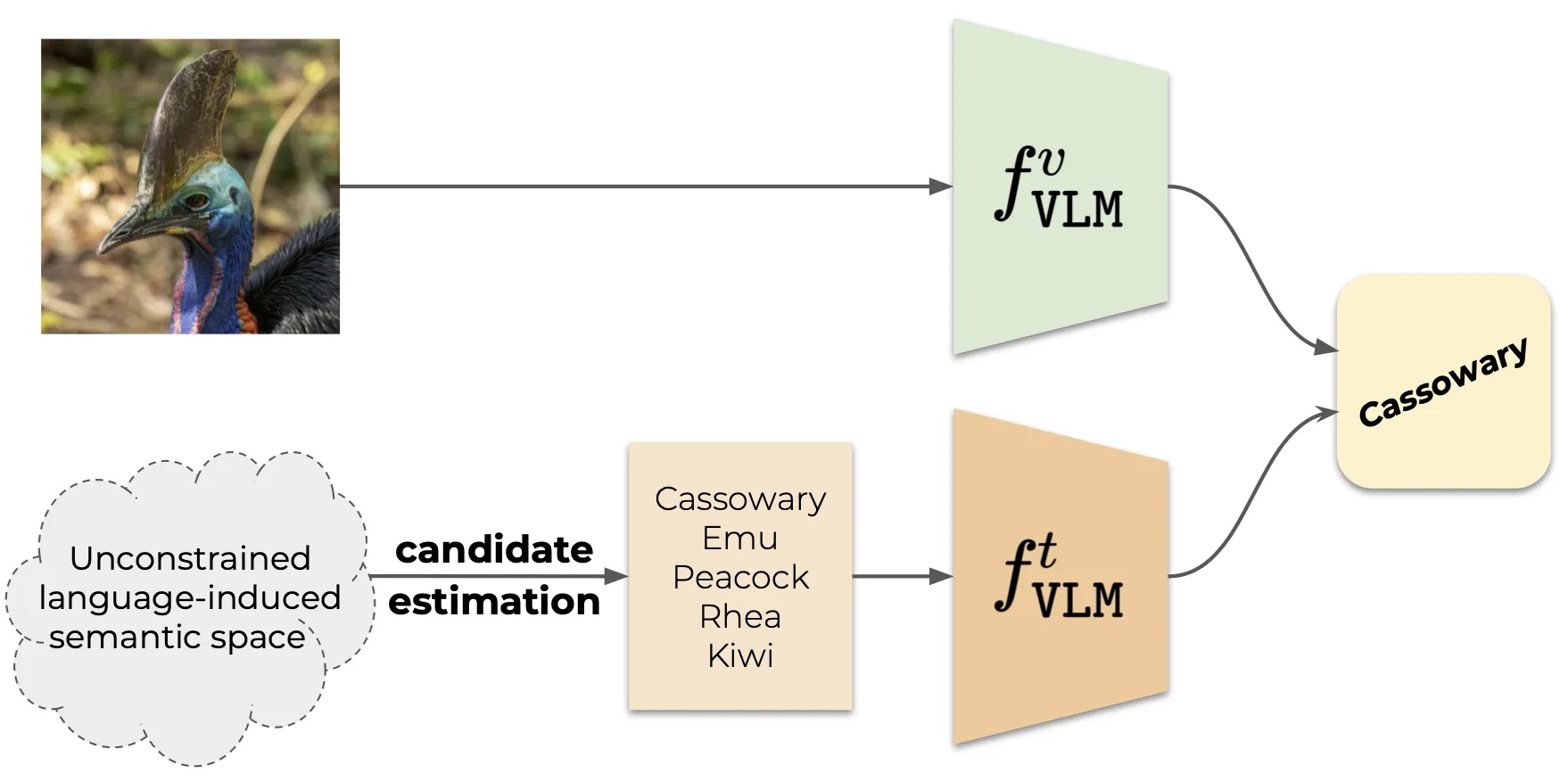
| Vision Language Model (VLM)-based classification | Vocabulary-free Image Classification |
|
| :-----------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------: |
| Vision Language Model (VLM)-based classification | Vocabulary-free Image Classification |