
Maxim Sentiment Model
Introduction
In the digital era, technology has transformed many aspects of life, including the way people access transportation services. The emergence of online motorcycle taxi applications has made mobility easier and more practical. In Indonesia, the market is dominated by Gojek and Grab; however, the rise of Maxim as an alternative demonstrates that the demand for online transportation services continues to grow, while also reflecting society’s increasing reliance on technology in daily activities. In this context, Maxim, as one of the online transportation service providers, offers an interesting dynamic to study. As a new competitor amid the dominance of Gojek and Grab, Maxim has received numerous user reviews related to service quality, pricing, and overall application experience. These reviews can serve as valuable material for analysis to understand how society perceives Maxim in comparison to its competitors. Therefore, this study proposes a sentiment analysis model that employs the Gated Recurrent Unit (GRU) method to process user reviews, supported by FastText as the word embedding technique. This approach is expected to capture user perception patterns more accurately while providing insights into Maxim’s position in the online transportation industry.
Objectives
Analyzing user reviews of Maxim to identify positive and negative sentiments contained in the application reviews, thereby providing an overview of public perception toward the online transportation service.
Testing the combination of the Gated Recurrent Unit (GRU) method and FastText in analyzing each user review, in order to evaluate the effectiveness of the model in producing accurate sentiment classification.
Literature Review
FastText is a word embedding technique developed by Facebook AI Research. Unlike Word2Vec, which represents a word as a single vector, FastText breaks down words into subword units (n-grams). This enables FastText to better handle rare or out-of-vocabulary words, as well as languages with high morphological variation.
Gated Recurrent Unit (GRU) is a type of Recurrent Neural Network (RNN) designed to process sequential data, such as text or speech. GRU has gating mechanisms (update gate and reset gate) that make it simpler compared to Long Short-Term Memory (LSTM), yet still effective in retaining important information and discarding irrelevant data. Due to its lighter architecture, GRU is often chosen for natural language processing tasks involving large datasets.
Methodology
Data Collection
The first step carried out in this study was data collection. This process was conducted by scraping user reviews or comments of the Maxim application available on the Google Play Store. The data collection period was set from 2020 to 2024 in order to obtain a more comprehensive overview of user perceptions during that timeframe. From this process, a total of 423,364 reviews were successfully gathered, which were then used as the primary dataset in this research.
| No | userName | review | rating | at |
|---|---|---|---|---|
| 0 | Pengguna Google | terimakasih kasih bapak | 5 | 2024-12-30 23:59:57 |
| 1 | Pengguna Google | aku suka pakai Maxim tapi sekarang daftar susa... | 2 | 2024-12-30 23:47:00 |
| 2 | Pengguna Google | penjemputan nya sllu tepat wkt, tdk perlu menu... | 5 | 2024-12-30 23:46:58 |
| 3 | Pengguna Google | alternatif ojol yg membantu | 5 | 2024-12-30 23:46:05 |
| 4 | Pengguna Google | cepat tepat | 5 | 2024-12-30 23:45:00 |
| ... | ... | ... | ... | ... |
| 423359 | Pengguna Google | Semoga lebih jaya | 5 | 2020-01-01 01:39:06 |
| 423360 | Pengguna Google | Bagus banget... Murah banget.... Suka banget... | 5 | 2020-01-01 01:28:46 |
| 423361 | Pengguna Google | Tiap mau order mshh bingunxx dengann titik pen... | 5 | 2020-01-01 01:26:21 |
| 423362 | Pengguna Google | Mantap | 5 | 2020-01-01 01:05:44 |
| 423363 | Pengguna Google | Low Price.. | 5 | 2020-01-01 00:41:32 |
Manual Sentiment Labeling
Before the cleaning stage, manual sentiment labeling was performed by the researcher by reading and analyzing each review from the Play Store. Reviews were labeled as positive, negative, or neutral to ensure that the main meaning remained identifiable even after the data was cleaned. These labeled data were then used in the cleaning and preprocessing stages before being processed by the GRU model with FastText.
| No | userName | review | rating | at | label |
|---|---|---|---|---|---|
| 0 | Pengguna Google | terimakasih kasih bapak | 5 | 2024-12-30 23:59:57 | POSITIF |
| 1 | Pengguna Google | aku suka pakai Maxim tapi sekarang daftar susa... | 2 | 2024-12-30 23:47:00 | NEGATIF |
| 2 | Pengguna Google | penjemputan nya sllu tepat wkt, tdk perlu menu... | 5 | 2024-12-30 23:46:58 | POSITIF |
| 3 | Pengguna Google | alternatif ojol yg membantu | 5 | 2024-12-30 23:46:05 | NETRAL |
| 4 | Pengguna Google | cepat tepat | 5 | 2024-12-30 23:45:00 | POSITIF |
| ... | ... | ... | ... | ... | ... |
| 423359 | Pengguna Google | Semoga lebih jaya | 5 | 2020-01-01 01:39:06 | POSITIF |
| 423360 | Pengguna Google | Bagus banget... Murah banget.... Suka banget... | 5 | 2020-01-01 01:28:46 | POSITIF |
| 423361 | Pengguna Google | Tiap mau order mshh bingunxx dengann titik pen... | 5 | 2020-01-01 01:26:21 | POSITIF |
| 423362 | Pengguna Google | Mantap | 5 | 2020-01-01 01:05:44 | POSITIF |
| 423363 | Pengguna Google | Low Price.. | 5 | 2020-01-01 00:41:32 | POSITIF |
Data Filtering
After sentiment labels were assigned, the next step was data cleaning, which involved removing emojis, symbols, non-alphabetic characters, and missing values. The data were also filtered by eliminating reviews labeled as neutral, leaving only two sentiment categories: positive and negative. Following this process, the dataset was reduced from 423,364 to 401,631 reviews, which were then ready for subsequent processing.
Word Tokenization
After the data has undergone the filtering stage, word tokenization is performed to break down each Maxim user review into individual word units (tokens). This process not only serves as a technical step to prepare the text for processing by the GRU model but also forms the basis for analysis, as each token represents meaning that can influence sentiment classification. Through tokenization, sentence structures are transformed into more measurable sequences of words, facilitating the model’s pattern learning and enabling FastText to generate more contextual vector representations.
| No | userName | review | rating | at | label | token |
|---|---|---|---|---|---|---|
| 0 | Pengguna Google | terimakasih kasih bapak | 5 | 2024-12-30 23:59:57 | POSITIF | [terimakasih, kasih, bapak] |
| 1 | Pengguna Google | aku suka pakai Maxim tapi sekarang daftar susa... | 2 | 2024-12-30 23:47:00 | NEGATIF | [aku, suka, pakai, Maxim, tapi, sekarang, daft...] |
| 2 | Pengguna Google | penjemputan nya sllu tepat wkt tdk perlu menu... | 5 | 2024-12-30 23:46:58 | POSITIF | [penjemputan, nya, sllu, tepat, wkt, tdk, perl...] |
| 4 | Pengguna Google | cepat tepat | 5 | 2024-12-30 23:45:00 | POSITIF | [cepat, tepat] |
| 5 | Pengguna Google | Bagus | 5 | 2024-12-30 23:40:18 | POSITIF | [Bagus] |
Results
Data Exploration
Sentiment Trend Graph
The review data of the Maxim application indicates that the number of reviews has steadily increased each year, reflecting the growing popularity of the application. Positive reviews have consistently dominated, rising from 75% in 2020 to 82% in 2024, which demonstrates an improvement in user satisfaction. Meanwhile, negative reviews experienced an increase up until 2023 but declined again in 2024, suggesting improvements in the quality of the application. Overall, this trend reflects both the rapid growth of the user base and the increasing level of satisfaction with the Maxim application.
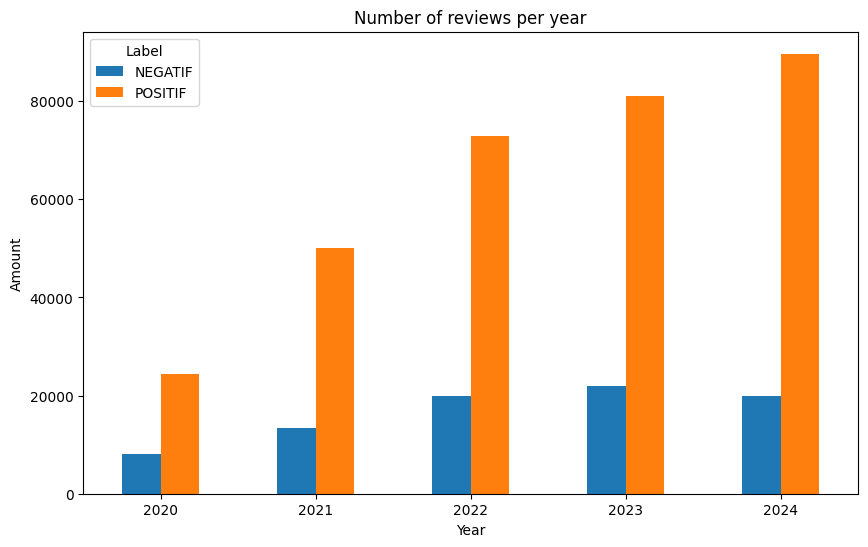
| Tahun | Negatif | Positif |
|---|---|---|
| 2020 | 8,076 | 24,487 |
| 2021 | 13,391 | 50,128 |
| 2022 | 19,825 | 72,918 |
| 2023 | 22,036 | 81,069 |
| 2024 | 20,009 | 89,692 |
WordCloud
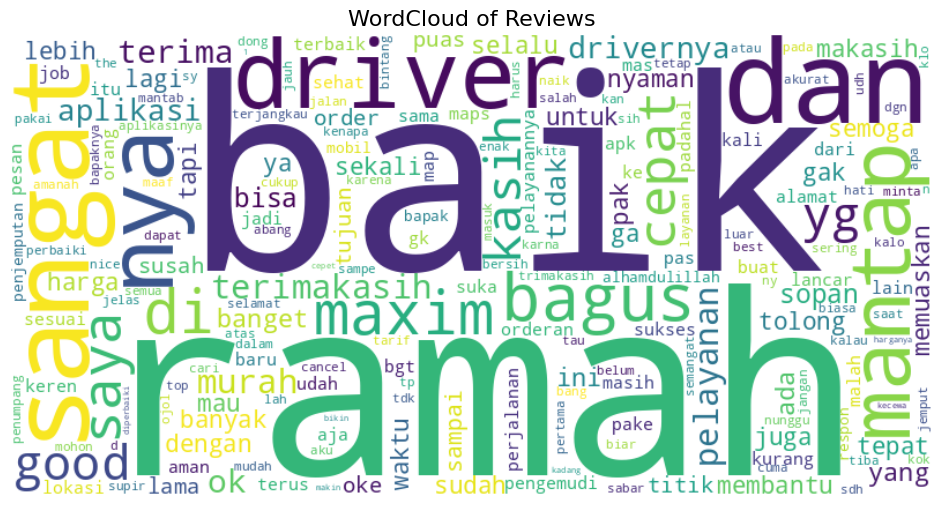
The WordCloud generated from Maxim application reviews shows that the majority of users provided positive feedback, with dominant words such as good, friendly, driver, very, excellent, fast, and great. These words reflect user appreciation for driver friendliness, fast service, and the overall quality of the platform. Negative terms such as slow, lacking, and problem also appear, but their smaller size indicates that they are far less frequent and not dominant. Overall, the WordCloud reinforces the finding that user experiences with the Maxim application tend to be positive and satisfactory.
Building the FastText Model
The FastText model was trained using tokenized data with 500-dimensional vectors, a context window of five words, and by ignoring words that appeared fewer than five times. The Skip-gram algorithm was employed, with a total of 30 epochs to ensure more stable embeddings. As a result of this training, the model processed 2.19 million raw words with 1.59 million effective words in 10.2 seconds, while the overall training covered 65.87 million raw words and 47.80 million effective words, completed in 306 seconds. This demonstrates that the training process was fast and efficient, even when using a large dataset.
Data Preprocessing
The preprocessing stage began by converting all review texts to lowercase to maintain consistency and avoid differences in meaning between uppercase and lowercase words. Next, the data were divided into features (X) and labels (y), then split into training and testing sets with an 80:20 ratio using stratified sampling to preserve class distribution. The pre-trained FastText model was then loaded, and each review was converted into an embedding vector by averaging the word vectors of its tokens. To address class imbalance, the training data were balanced through a combination of undersampling the majority class to 70% and applying SMOTE to increase minority class samples to an equal proportion. Labels were then encoded into numeric form using LabelEncoder. Finally, all data were transformed into PyTorch tensors and organized into a DataLoader with a batch size of 32, making them ready for the model training process.
Building the GRU Model
This stage involved constructing a GRU (Gated Recurrent Unit) classifier architecture for text classification based on FastText embeddings. The model was defined with three bidirectional GRU layers, each with a hidden state size of 64, followed by a fully connected layer, ReLU activation function, and dropout to prevent overfitting. The final output was projected to match the number of data labels. The loss function used was CrossEntropyLoss, and optimization was performed using the Adam algorithm with a learning rate of 0.001. Additionally, a ReduceLROnPlateau scheduler was applied to adaptively reduce the learning rate when the loss failed to decrease. The training process was executed for 20 epochs, where in each iteration the model performed a forward pass, loss calculation, backpropagation, and parameter updates. The training results were presented as the average loss per epoch, which helped monitor the model’s performance and convergence throughout the training.
Evaluation
Graph of Loss per Epoch
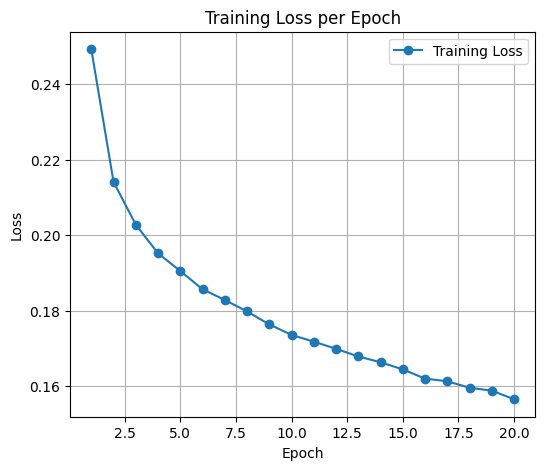
The training loss graph per epoch shows a consistent decrease from the beginning to the end of the training process. In the first epoch, the loss was 0.2493, then gradually decreased to 0.1565 by the 20th epoch. This downward trend indicates that the GRU model was able to learn effectively from the data, with each epoch producing increasingly optimized parameters. The stable and steadily decreasing loss curve, without significant spikes, also demonstrates that the training process was effective and did not experience overfitting at this stage.
Confusion Matrix
The evaluation results using the confusion matrix indicate that the model performed well, achieving an overall accuracy of 92%. For the negative class, the precision reached 0.73 and recall 0.95, showing that the model is better at detecting negative data, although some positive predictions were misclassified. Meanwhile, for the positive class, precision was very high at 0.98 with a recall of 0.91, meaning the model was highly accurate in predicting positive data, though a small portion of positives was missed. The balanced f1-scores (0.83 for negative and 0.95 for positive) demonstrate that the model performs consistently across both classes, with a weighted average of 0.92, indicating that the model
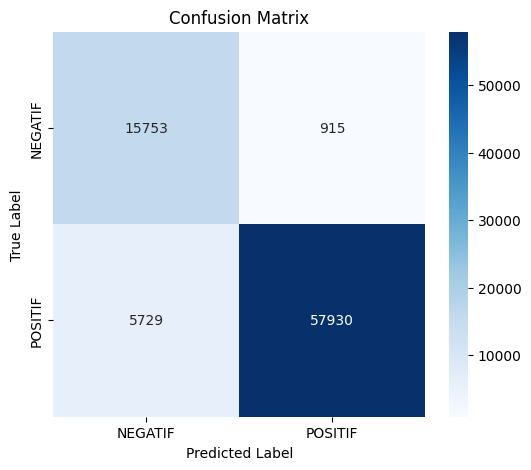
| Label | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| NEGATIF | 0.73 | 0.95 | 0.83 | 16668 |
| POSITIF | 0.98 | 0.91 | 0.95 | 63659 |
| Accuracy | 0.92 | 80327 | ||
| Macro Avg | 0.86 | 0.93 | 0.89 | 80327 |
| Weighted Avg | 0.93 | 0.92 | 0.92 | 80327 |
Conclusion
The sentiment analysis model built by combining FastText and GRU has proven effective in processing user reviews of the Maxim application. FastText is capable of generating more contextual word representations by utilizing subwords, maintaining accuracy even when encountering variations or new words. These vector representations are then processed by the GRU, which excels at handling sequential data such as text, allowing it to recognize sentiment patterns more effectively. Evaluation results show a high accuracy of 92%, with balanced precision, recall, and f1-scores, indicating that the FastText-GRU combination is reliable for sentiment classification of online transportation service reviews.
- Downloads last month
- -