

AFM-4.5B-Base-Pre-Anneal
AFM-4.5B-Base-Pre-Anneal is a 4.5 billion parameter instruction-tuned model developed by Arcee.ai, designed for enterprise-grade performance across diverse deployment environments from cloud to edge. The base model was trained on a dataset of 6.5 trillion tokens of general pretraining data. We use a modified version of TorchTitan for pretraining.
The development of AFM-4.5B prioritized data quality as a fundamental requirement for achieving robust model performance. We collaborated with DatologyAI, a company specializing in large-scale data curation. DatologyAI's curation pipeline integrates a suite of proprietary algorithms—model-based quality filtering, embedding-based curation, target distribution-matching, source mixing, and synthetic data. Their expertise enabled the creation of a curated dataset tailored to support strong real-world performance.
The model architecture follows a standard transformer decoder-only design based on Vaswani et al., incorporating several key modifications for enhanced performance and efficiency. Notable architectural features include grouped query attention for improved inference efficiency and ReLU^2 activation functions instead of SwiGLU to enable sparsification while maintaining or exceeding performance benchmarks.
The model available in this repo is the base model before it was annealed with math and code and before merging and context extension.

Model Details
- Model Architecture: ArceeForCausalLM
- Parameters: 4.5B
- Training Tokens: 6.5T - this model is pre-annealing with math and code and uses only the general dataset.
- License: Apache-2.0
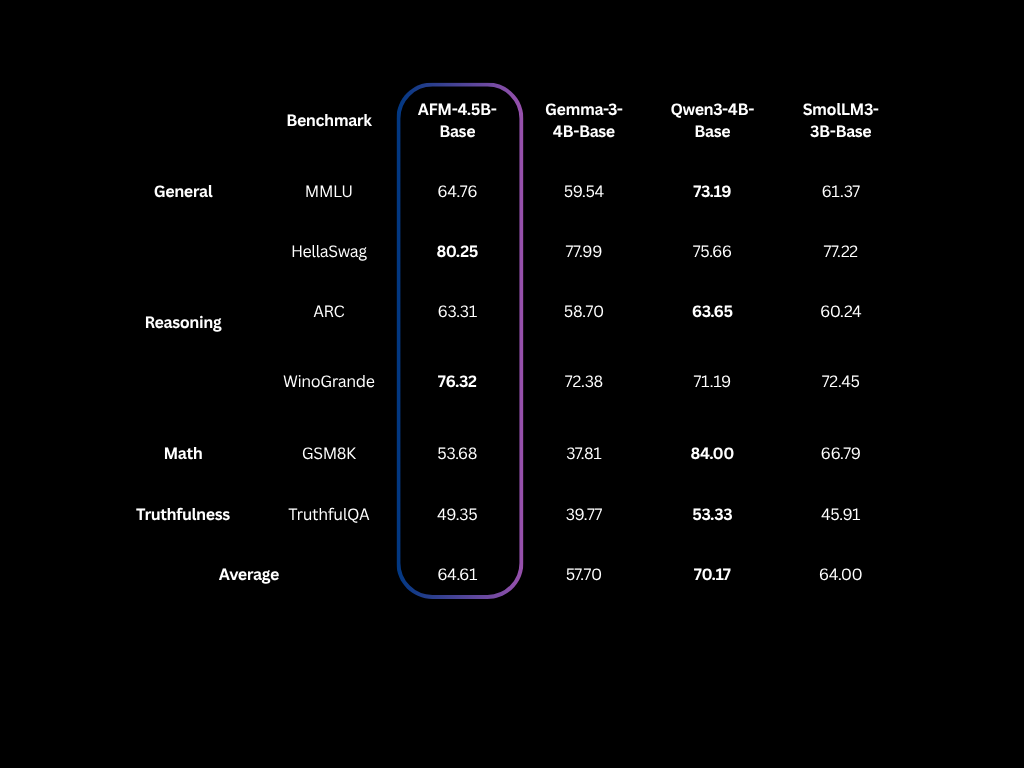
Benchmarks
How to use with transformers
You can use the model directly with the transformers library.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "arcee-ai/AFM-4.5B-Base-Pre-Anneal"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "Once upon a time "
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(model.device)
# Generate text
outputs = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.7,
top_p=0.95
)
generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)[0]
print(generated_text)
License
AFM-4.5B is released under the Apache-2.0 license.
- Downloads last month
- 70