
text
stringlengths 0
2k
| heading1
stringlengths 4
79
| source_page_url
stringclasses 180
values | source_page_title
stringclasses 180
values |
|---|---|---|---|
To gather feedback on your chat model, set `gr.ChatInterface(flagging_mode="manual")` and users will be able to thumbs-up or thumbs-down assistant responses. Each flagged response, along with the entire chat history, will get saved in a CSV file in the app working directory (this can be configured via the `flagging_dir` parameter).
You can also change the feedback options via `flagging_options` parameter. The default options are "Like" and "Dislike", which appear as the thumbs-up and thumbs-down icons. Any other options appear under a dedicated flag icon. This example shows a ChatInterface that has both chat history (mentioned in the previous section) and user feedback enabled:
$code_chatinterface_streaming_echo
Note that in this example, we set several flagging options: "Like", "Spam", "Inappropriate", "Other". Because the case-sensitive string "Like" is one of the flagging options, the user will see a thumbs-up icon next to each assistant message. The three other flagging options will appear in a dropdown under the flag icon.
|
Collecting User Feedback
|
https://gradio.app/guides/creating-a-chatbot-fast
|
Chatbots - Creating A Chatbot Fast Guide
|
Now that you've learned about the `gr.ChatInterface` class and how it can be used to create chatbot UIs quickly, we recommend reading one of the following:
* [Our next Guide](../guides/chatinterface-examples) shows examples of how to use `gr.ChatInterface` with popular LLM libraries.
* If you'd like to build very custom chat applications from scratch, you can build them using the low-level Blocks API, as [discussed in this Guide](../guides/creating-a-custom-chatbot-with-blocks).
* Once you've deployed your Gradio Chat Interface, its easy to use in other applications because of the built-in API. Here's a tutorial on [how to deploy a Gradio chat interface as a Discord bot](../guides/creating-a-discord-bot-from-a-gradio-app).
|
What's Next?
|
https://gradio.app/guides/creating-a-chatbot-fast
|
Chatbots - Creating A Chatbot Fast Guide
|
First, we'll build the UI without handling these events and build from there.
We'll use the Hugging Face InferenceClient in order to get started without setting up
any API keys.
This is what the first draft of our application looks like:
```python
from huggingface_hub import InferenceClient
import gradio as gr
client = InferenceClient()
def respond(
prompt: str,
history,
):
if not history:
history = [{"role": "system", "content": "You are a friendly chatbot"}]
history.append({"role": "user", "content": prompt})
yield history
response = {"role": "assistant", "content": ""}
for message in client.chat_completion(
history,
temperature=0.95,
top_p=0.9,
max_tokens=512,
stream=True,
model="HuggingFaceH4/zephyr-7b-beta"
):
response["content"] += message.choices[0].delta.content or ""
yield history + [response]
with gr.Blocks() as demo:
gr.Markdown("Chat with Hugging Face Zephyr 7b 🤗")
chatbot = gr.Chatbot(
label="Agent",
type="messages",
avatar_images=(
None,
"https://em-content.zobj.net/source/twitter/376/hugging-face_1f917.png",
),
)
prompt = gr.Textbox(max_lines=1, label="Chat Message")
prompt.submit(respond, [prompt, chatbot], [chatbot])
prompt.submit(lambda: "", None, [prompt])
if __name__ == "__main__":
demo.launch()
```
|
The UI
|
https://gradio.app/guides/chatbot-specific-events
|
Chatbots - Chatbot Specific Events Guide
|
Our undo event will populate the textbox with the previous user message and also remove all subsequent assistant responses.
In order to know the index of the last user message, we can pass `gr.UndoData` to our event handler function like so:
```python
def handle_undo(history, undo_data: gr.UndoData):
return history[:undo_data.index], history[undo_data.index]['content']
```
We then pass this function to the `undo` event!
```python
chatbot.undo(handle_undo, chatbot, [chatbot, prompt])
```
You'll notice that every bot response will now have an "undo icon" you can use to undo the response -

Tip: You can also access the content of the user message with `undo_data.value`
|
The Undo Event
|
https://gradio.app/guides/chatbot-specific-events
|
Chatbots - Chatbot Specific Events Guide
|
The retry event will work similarly. We'll use `gr.RetryData` to get the index of the previous user message and remove all the subsequent messages from the history. Then we'll use the `respond` function to generate a new response. We could also get the previous prompt via the `value` property of `gr.RetryData`.
```python
def handle_retry(history, retry_data: gr.RetryData):
new_history = history[:retry_data.index]
previous_prompt = history[retry_data.index]['content']
yield from respond(previous_prompt, new_history)
...
chatbot.retry(handle_retry, chatbot, chatbot)
```
You'll see that the bot messages have a "retry" icon now -

Tip: The Hugging Face inference API caches responses, so in this demo, the retry button will not generate a new response.
|
The Retry Event
|
https://gradio.app/guides/chatbot-specific-events
|
Chatbots - Chatbot Specific Events Guide
|
By now you should hopefully be seeing the pattern!
To let users like a message, we'll add a `.like` event to our chatbot.
We'll pass it a function that accepts a `gr.LikeData` object.
In this case, we'll just print the message that was either liked or disliked.
```python
def handle_like(data: gr.LikeData):
if data.liked:
print("You upvoted this response: ", data.value)
else:
print("You downvoted this response: ", data.value)
...
chatbot.like(vote, None, None)
```
|
The Like Event
|
https://gradio.app/guides/chatbot-specific-events
|
Chatbots - Chatbot Specific Events Guide
|
Same idea with the edit listener! with `gr.Chatbot(editable=True)`, you can capture user edits. The `gr.EditData` object tells us the index of the message edited and the new text of the mssage. Below, we use this object to edit the history, and delete any subsequent messages.
```python
def handle_edit(history, edit_data: gr.EditData):
new_history = history[:edit_data.index]
new_history[-1]['content'] = edit_data.value
return new_history
...
chatbot.edit(handle_edit, chatbot, chatbot)
```
|
The Edit Event
|
https://gradio.app/guides/chatbot-specific-events
|
Chatbots - Chatbot Specific Events Guide
|
As a bonus, we'll also cover the `.clear()` event, which is triggered when the user clicks the clear icon to clear all messages. As a developer, you can attach additional events that should happen when this icon is clicked, e.g. to handle clearing of additional chatbot state:
```python
from uuid import uuid4
import gradio as gr
def clear():
print("Cleared uuid")
return uuid4()
def chat_fn(user_input, history, uuid):
return f"{user_input} with uuid {uuid}"
with gr.Blocks() as demo:
uuid_state = gr.State(
uuid4
)
chatbot = gr.Chatbot(type="messages")
chatbot.clear(clear, outputs=[uuid_state])
gr.ChatInterface(
chat_fn,
additional_inputs=[uuid_state],
chatbot=chatbot,
type="messages"
)
demo.launch()
```
In this example, the `clear` function, bound to the `chatbot.clear` event, returns a new UUID into our session state, when the chat history is cleared via the trash icon. This can be seen in the `chat_fn` function, which references the UUID saved in our session state.
This example also shows that you can use these events with `gr.ChatInterface` by passing in a custom `gr.Chatbot` object.
|
The Clear Event
|
https://gradio.app/guides/chatbot-specific-events
|
Chatbots - Chatbot Specific Events Guide
|
That's it! You now know how you can implement the retry, undo, like, and clear events for the Chatbot.
|
Conclusion
|
https://gradio.app/guides/chatbot-specific-events
|
Chatbots - Chatbot Specific Events Guide
|
3D models are becoming more popular in machine learning and make for some of the most fun demos to experiment with. Using `gradio`, you can easily build a demo of your 3D image model and share it with anyone. The Gradio 3D Model component accepts 3 file types including: _.obj_, _.glb_, & _.gltf_.
This guide will show you how to build a demo for your 3D image model in a few lines of code; like the one below. Play around with 3D object by clicking around, dragging and zooming:
<gradio-app space="gradio/Model3D"> </gradio-app>
Prerequisites
Make sure you have the `gradio` Python package already [installed](https://gradio.app/guides/quickstart).
|
Introduction
|
https://gradio.app/guides/how-to-use-3D-model-component
|
Other Tutorials - How To Use 3D Model Component Guide
|
Let's take a look at how to create the minimal interface above. The prediction function in this case will just return the original 3D model mesh, but you can change this function to run inference on your machine learning model. We'll take a look at more complex examples below.
```python
import gradio as gr
import os
def load_mesh(mesh_file_name):
return mesh_file_name
demo = gr.Interface(
fn=load_mesh,
inputs=gr.Model3D(),
outputs=gr.Model3D(
clear_color=[0.0, 0.0, 0.0, 0.0], label="3D Model"),
examples=[
[os.path.join(os.path.dirname(__file__), "files/Bunny.obj")],
[os.path.join(os.path.dirname(__file__), "files/Duck.glb")],
[os.path.join(os.path.dirname(__file__), "files/Fox.gltf")],
[os.path.join(os.path.dirname(__file__), "files/face.obj")],
],
)
if __name__ == "__main__":
demo.launch()
```
Let's break down the code above:
`load_mesh`: This is our 'prediction' function and for simplicity, this function will take in the 3D model mesh and return it.
Creating the Interface:
- `fn`: the prediction function that is used when the user clicks submit. In our case this is the `load_mesh` function.
- `inputs`: create a model3D input component. The input expects an uploaded file as a {str} filepath.
- `outputs`: create a model3D output component. The output component also expects a file as a {str} filepath.
- `clear_color`: this is the background color of the 3D model canvas. Expects RGBa values.
- `label`: the label that appears on the top left of the component.
- `examples`: list of 3D model files. The 3D model component can accept _.obj_, _.glb_, & _.gltf_ file types.
- `cache_examples`: saves the predicted output for the examples, to save time on inference.
|
Taking a Look at the Code
|
https://gradio.app/guides/how-to-use-3D-model-component
|
Other Tutorials - How To Use 3D Model Component Guide
|
Below is a demo that uses the DPT model to predict the depth of an image and then uses 3D Point Cloud to create a 3D object. Take a look at the [app.py](https://huggingface.co/spaces/gradio/dpt-depth-estimation-3d-obj/blob/main/app.py) file for a peek into the code and the model prediction function.
<gradio-app space="gradio/dpt-depth-estimation-3d-obj"> </gradio-app>
---
And you're done! That's all the code you need to build an interface for your Model3D model. Here are some references that you may find useful:
- Gradio's ["Getting Started" guide](https://gradio.app/getting_started/)
- The first [3D Model Demo](https://huggingface.co/spaces/gradio/Model3D) and [complete code](https://huggingface.co/spaces/gradio/Model3D/tree/main) (on Hugging Face Spaces)
|
Exploring a more complex Model3D Demo:
|
https://gradio.app/guides/how-to-use-3D-model-component
|
Other Tutorials - How To Use 3D Model Component Guide
|
Let's deploy a Gradio-style "Hello, world" app that lets a user input their name and then responds with a short greeting. We're not going to use this code as-is in our app, but it's useful to see what the initial Gradio version looks like.
```python
import gradio as gr
A simple Gradio interface for a greeting function
def greet(name):
return f"Hello {name}!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch()
```
To deploy this app on Modal you'll need to
- define your container image,
- wrap the Gradio app in a Modal Function,
- and deploy it using Modal's CLI!
Prerequisite: Install and set up Modal
Before you get started, you'll need to create a Modal account if you don't already have one. Then you can set up your environment by authenticating with those account credentials.
- Sign up at [modal.com](https://www.modal.com?utm_source=partner&utm_medium=github&utm_campaign=livekit).
- Install the Modal client in your local development environment.
```bash
pip install modal
```
- Authenticate your account.
```
modal setup
```
Great, now we can start building our app!
Step 1: Define our `modal.Image`
To start, let's make a new file named `gradio_app.py`, import `modal`, and define our image. Modal `Images` are defined by sequentially calling methods on our `Image` instance.
For this simple app, we'll
- start with the `debian_slim` image,
- choose a Python version (3.12),
- and install the dependencies - only `fastapi` and `gradio`.
```python
import modal
app = modal.App("gradio-app")
web_image = modal.Image.debian_slim(python_version="3.12").uv_pip_install(
"fastapi[standard]",
"gradio",
)
```
Note, that you don't need to install `gradio` or `fastapi` in your local environement - only `modal` is required locally.
Step 2: Wrap the Gradio app in a Modal-deployed FastAPI app
Like many Gradio apps, the example above is run by calling `launch()` on our demo at the end of the script. However, Modal doesn't ru
|
Deploying a simple Gradio app on Modal
|
https://gradio.app/guides/deploying-gradio-with-modal
|
Other Tutorials - Deploying Gradio With Modal Guide
|
.
Step 2: Wrap the Gradio app in a Modal-deployed FastAPI app
Like many Gradio apps, the example above is run by calling `launch()` on our demo at the end of the script. However, Modal doesn't run scripts, it runs functions - serverless functions to be exact.
To get Modal to serve our `demo`, we can leverage Gradio and Modal's support for `fastapi` apps. We do this with the `@modal.asgi_app()` function decorator which deploys the web app returned by the function. And we use the `mount_gradio_app` function to add our Gradio `demo` as a route in the web app.
```python
with web_image.imports():
import gradio as gr
from gradio.routes import mount_gradio_app
from fastapi import FastAPI
@app.function(
image=web_image,
max_containers = 1, we'll come to this later
)
@modal.concurrent(max_inputs=100) allow multiple users at one time
@modal.asgi_app()
def ui():
"""A simple Gradio interface for a greeting function."""
def greet(name):
return f"Hello {name}!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
return mount_gradio_app(app=FastAPI(), blocks=demo, path="/")
```
Let's quickly review what's going on here:
- We use the `Image.imports` context manager to define our imports. These will be available when your function runs in the cloud.
- We move our code inside a Python function, `ui`, and decorate it with `@app.function` which wraps it as a Modal serverless Function. We provide the image and other parameters (we'll cover this later) as inputs to the decorator.
- We add the `@modal.concurrent` decorator which allows multiple requests per container to be processed at the same time.
- We add the `@modal.asgi_app` decorator which tells Modal that this particular function is serving an ASGI app (here a `fastapi` app). To use this decorator, your ASGI app needs to be the return value from the function.
Step 3: Deploying on Modal
To deploy the app, just run the following command:
```bash
modal deploy <pat
|
Deploying a simple Gradio app on Modal
|
https://gradio.app/guides/deploying-gradio-with-modal
|
Other Tutorials - Deploying Gradio With Modal Guide
|
app). To use this decorator, your ASGI app needs to be the return value from the function.
Step 3: Deploying on Modal
To deploy the app, just run the following command:
```bash
modal deploy <path-to-file>
```
The first time you run your app, Modal will build and cache the image which, takes about 30 seconds. As long as you don't change the image, subsequent deployments will only take a few seconds.
After the image builds Modal will print the URL to your webapp and to your Modal dashboard. The webapp URL should look something like `https://{workspace}-{environment}--gradio-app-ui.modal.run`. Paste it into your web browser a try out your app!
|
Deploying a simple Gradio app on Modal
|
https://gradio.app/guides/deploying-gradio-with-modal
|
Other Tutorials - Deploying Gradio With Modal Guide
|
Sticky Sessions
Modal Functions are serverless which means that each client request is considered independent. While this facilitates autoscaling, it can also mean that extra care should be taken if your application requires any sort of server-side statefulness.
Gradio relies on a REST API, which is itself stateless. But it does require sticky sessions, meaning that every request from a particular client must be routed to the same container. However, Modal does not make any guarantees in this regard.
A simple way to satisfy this constraint is to set `max_containers = 1` in the `@app.function` decorator and setting the `max_inputs` argument of `@modal.concurrent` to a fairly large number - as we did above. This means that Modal won't spin up more than one container to serve requests to your app which effectively satisfies the sticky session requirement.
Concurrency and Queues
Both Gradio and Modal have concepts of concurrency and queues, and getting the most of out of your compute resources requires understanding how these interact.
Modal queues client requests to each deployed Function and simultaneously executes requests up to the concurrency limit for that Function. If requests come in and the concurrency limit is already satisfied, Modal will spin up a new container - up to the maximum set for the Function. In our case, our Gradio app is represented by one Modal Function, so all requests share one queue and concurrency limit. Therefore Modal constrains the _total_ number of requests running at one time, regardless of what they are doing.
Gradio on the other hand, allows developers to utilize multiple queues each with its own concurrency limit. One or more event listeners can then be assigned to a queue which is useful to manage GPU resources for computationally expensive requests.
Thinking carefully about how these queues and limits interact can help you optimize your app's performance and resource optimization while avoiding unwanted results like
|
Important Considerations
|
https://gradio.app/guides/deploying-gradio-with-modal
|
Other Tutorials - Deploying Gradio With Modal Guide
|
tionally expensive requests.
Thinking carefully about how these queues and limits interact can help you optimize your app's performance and resource optimization while avoiding unwanted results like shared or lost state.
Creating a GPU Function
Another option to manage GPU utilization is to deploy your GPU computations in their own Modal Function and calling this remote Function from inside your Gradio app. This allows you to take full advantage of Modal's serverless autoscaling while routing all of the client HTTP requests to a single Gradio CPU container.
|
Important Considerations
|
https://gradio.app/guides/deploying-gradio-with-modal
|
Other Tutorials - Deploying Gradio With Modal Guide
|
In this guide we will demonstrate some of the ways you can use Gradio with Comet. We will cover the basics of using Comet with Gradio and show you some of the ways that you can leverage Gradio's advanced features such as [Embedding with iFrames](https://www.gradio.app/guides/sharing-your-app/embedding-with-iframes) and [State](https://www.gradio.app/docs/state) to build some amazing model evaluation workflows.
Here is a list of the topics covered in this guide.
1. Logging Gradio UI's to your Comet Experiments
2. Embedding Gradio Applications directly into your Comet Projects
3. Embedding Hugging Face Spaces directly into your Comet Projects
4. Logging Model Inferences from your Gradio Application to Comet
|
Introduction
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
[Comet](https://www.comet.com?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs) is an MLOps Platform that is designed to help Data Scientists and Teams build better models faster! Comet provides tooling to Track, Explain, Manage, and Monitor your models in a single place! It works with Jupyter Notebooks and Scripts and most importantly it's 100% free!
|
What is Comet?
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
First, install the dependencies needed to run these examples
```shell
pip install comet_ml torch torchvision transformers gradio shap requests Pillow
```
Next, you will need to [sign up for a Comet Account](https://www.comet.com/signup?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs). Once you have your account set up, [grab your API Key](https://www.comet.com/docs/v2/guides/getting-started/quickstart/get-an-api-key?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs) and configure your Comet credentials
If you're running these examples as a script, you can either export your credentials as environment variables
```shell
export COMET_API_KEY="<Your API Key>"
export COMET_WORKSPACE="<Your Workspace Name>"
export COMET_PROJECT_NAME="<Your Project Name>"
```
or set them in a `.comet.config` file in your working directory. You file should be formatted in the following way.
```shell
[comet]
api_key=<Your API Key>
workspace=<Your Workspace Name>
project_name=<Your Project Name>
```
If you are using the provided Colab Notebooks to run these examples, please run the cell with the following snippet before starting the Gradio UI. Running this cell allows you to interactively add your API key to the notebook.
```python
import comet_ml
comet_ml.init()
```
|
Setup
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
[](https://colab.research.google.com/github/comet-ml/comet-examples/blob/master/integrations/model-evaluation/gradio/notebooks/Gradio_and_Comet.ipynb)
In this example, we will go over how to log your Gradio Applications to Comet and interact with them using the Gradio Custom Panel.
Let's start by building a simple Image Classification example using `resnet18`.
```python
import comet_ml
import requests
import torch
from PIL import Image
from torchvision import transforms
torch.hub.download_url_to_file("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
model = torch.hub.load("pytorch/vision:v0.6.0", "resnet18", pretrained=True).eval()
model = model.to(device)
Download human-readable labels for ImageNet.
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def predict(inp):
inp = Image.fromarray(inp.astype("uint8"), "RGB")
inp = transforms.ToTensor()(inp).unsqueeze(0)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(inp.to(device))[0], dim=0)
return {labels[i]: float(prediction[i]) for i in range(1000)}
inputs = gr.Image()
outputs = gr.Label(num_top_classes=3)
io = gr.Interface(
fn=predict, inputs=inputs, outputs=outputs, examples=["dog.jpg"]
)
io.launch(inline=False, share=True)
experiment = comet_ml.Experiment()
experiment.add_tag("image-classifier")
io.integrate(comet_ml=experiment)
```
The last line in this snippet will log the URL of the Gradio Application to your Comet Experiment. You can find the URL in the Text Tab of your Experiment.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328034-09369d4d-8b94-4c4a-aa3c-25e3ed8394c4.mp4"></source>
</video>
Add the Gradio Panel to your Experiment to interact with your application.
<video width=
|
1. Logging Gradio UI's to your Comet Experiments
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
r-images.githubusercontent.com/7529846/214328034-09369d4d-8b94-4c4a-aa3c-25e3ed8394c4.mp4"></source>
</video>
Add the Gradio Panel to your Experiment to interact with your application.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328194-95987f83-c180-4929-9bed-c8a0d3563ed7.mp4"></source>
</video>
|
1. Logging Gradio UI's to your Comet Experiments
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=9" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
If you are permanently hosting your Gradio application, you can embed the UI using the Gradio Panel Extended custom Panel.
Go to your Comet Project page, and head over to the Panels tab. Click the `+ Add` button to bring up the Panels search page.
<img width="560" alt="adding-panels" src="https://user-images.githubusercontent.com/7529846/214329314-70a3ff3d-27fb-408c-a4d1-4b58892a3854.jpeg">
Next, search for Gradio Panel Extended in the Public Panels section and click `Add`.
<img width="560" alt="gradio-panel-extended" src="https://user-images.githubusercontent.com/7529846/214325577-43226119-0292-46be-a62a-0c7a80646ebb.png">
Once you have added your Panel, click `Edit` to access to the Panel Options page and paste in the URL of your Gradio application.
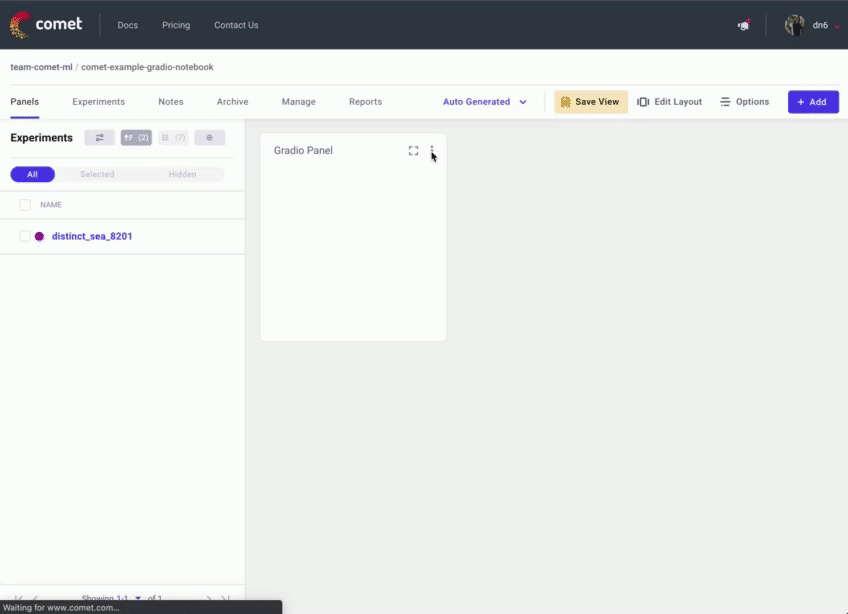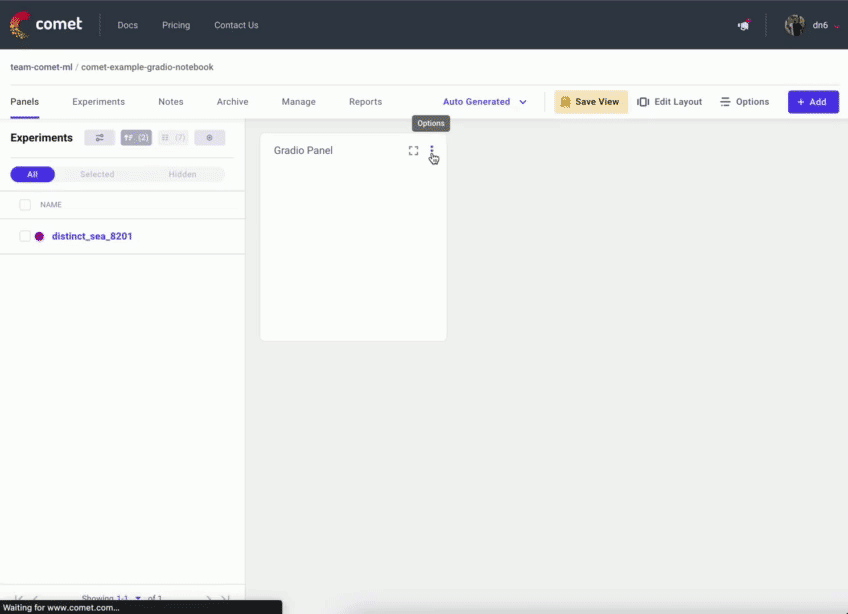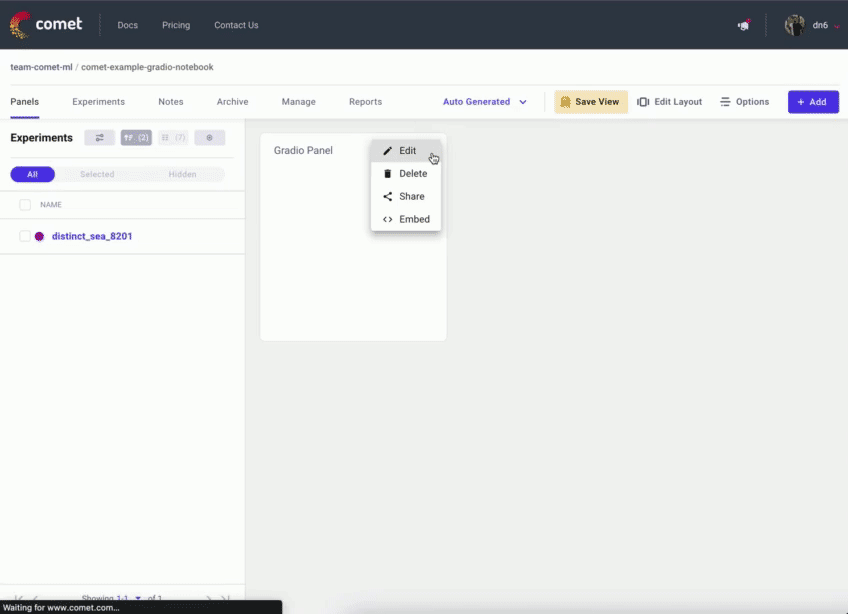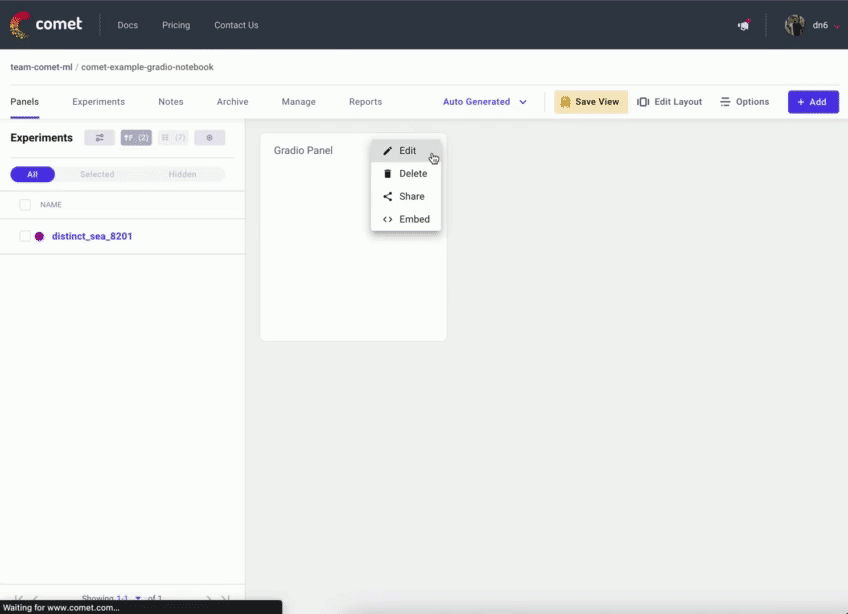
<img width="560" alt="Edit-Gradio-Panel-URL" src="https://user-images.githubusercontent.com/7529846/214334843-870fe726-0aa1-4b21-bbc6-0c48f56c48d8.png">
|
2. Embedding Gradio Applications directly into your Comet Projects
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=107" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
You can also embed Gradio Applications that are hosted on Hugging Faces Spaces into your Comet Projects using the Hugging Face Spaces Panel.
Go to your Comet Project page, and head over to the Panels tab. Click the `+ Add` button to bring up the Panels search page. Next, search for the Hugging Face Spaces Panel in the Public Panels section and click `Add`.
<img width="560" height="315" alt="huggingface-spaces-panel" src="https://user-images.githubusercontent.com/7529846/214325606-99aa3af3-b284-4026-b423-d3d238797e12.png">
Once you have added your Panel, click Edit to access to the Panel Options page and paste in the path of your Hugging Face Space e.g. `pytorch/ResNet`
<img width="560" height="315" alt="Edit-HF-Space" src="https://user-images.githubusercontent.com/7529846/214335868-c6f25dee-13db-4388-bcf5-65194f850b02.png">
|
3. Embedding Hugging Face Spaces directly into your Comet Projects
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=176" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
[](https://colab.research.google.com/github/comet-ml/comet-examples/blob/master/integrations/model-evaluation/gradio/notebooks/Logging_Model_Inferences_with_Comet_and_Gradio.ipynb)
In the previous examples, we demonstrated the various ways in which you can interact with a Gradio application through the Comet UI. Additionally, you can also log model inferences, such as SHAP plots, from your Gradio application to Comet.
In the following snippet, we're going to log inferences from a Text Generation model. We can persist an Experiment across multiple inference calls using Gradio's [State](https://www.gradio.app/docs/state) object. This will allow you to log multiple inferences from a model to a single Experiment.
```python
import comet_ml
import gradio as gr
import shap
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
MODEL_NAME = "gpt2"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
set model decoder to true
model.config.is_decoder = True
set text-generation params under task_specific_params
model.config.task_specific_params["text-generation"] = {
"do_sample": True,
"max_length": 50,
"temperature": 0.7,
"top_k": 50,
"no_repeat_ngram_size": 2,
}
model = model.to(device)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
explainer = shap.Explainer(model, tokenizer)
def start_experiment():
"""Returns an APIExperiment object that is thread safe
and can be used to log inferences to a single Experiment
"""
try:
api = comet_ml.API()
workspace = api.get_default_
|
4. Logging Model Inferences to Comet
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
"""Returns an APIExperiment object that is thread safe
and can be used to log inferences to a single Experiment
"""
try:
api = comet_ml.API()
workspace = api.get_default_workspace()
project_name = comet_ml.config.get_config()["comet.project_name"]
experiment = comet_ml.APIExperiment(
workspace=workspace, project_name=project_name
)
experiment.log_other("Created from", "gradio-inference")
message = f"Started Experiment: [{experiment.name}]({experiment.url})"
return (experiment, message)
except Exception as e:
return None, None
def predict(text, state, message):
experiment = state
shap_values = explainer([text])
plot = shap.plots.text(shap_values, display=False)
if experiment is not None:
experiment.log_other("message", message)
experiment.log_html(plot)
return plot
with gr.Blocks() as demo:
start_experiment_btn = gr.Button("Start New Experiment")
experiment_status = gr.Markdown()
Log a message to the Experiment to provide more context
experiment_message = gr.Textbox(label="Experiment Message")
experiment = gr.State()
input_text = gr.Textbox(label="Input Text", lines=5, interactive=True)
submit_btn = gr.Button("Submit")
output = gr.HTML(interactive=True)
start_experiment_btn.click(
start_experiment, outputs=[experiment, experiment_status]
)
submit_btn.click(
predict, inputs=[input_text, experiment, experiment_message], outputs=[output]
)
```
Inferences from this snippet will be saved in the HTML tab of your experiment.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328610-466e5c81-4814-49b9-887c-065aca14dd30.mp4"></source>
</video>
|
4. Logging Model Inferences to Comet
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
887c-065aca14dd30.mp4"></source>
</video>
|
4. Logging Model Inferences to Comet
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
We hope you found this guide useful and that it provides some inspiration to help you build awesome model evaluation workflows with Comet and Gradio.
|
Conclusion
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
- Create an account on Hugging Face [here](https://huggingface.co/join).
- Add Gradio Demo under your username, see this [course](https://huggingface.co/course/chapter9/4?fw=pt) for setting up Gradio Demo on Hugging Face.
- Request to join the Comet organization [here](https://huggingface.co/Comet).
|
How to contribute Gradio demos on HF spaces on the Comet organization
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
- [Comet Documentation](https://www.comet.com/docs/v2/?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs)
|
Additional Resources
|
https://gradio.app/guides/Gradio-and-Comet
|
Other Tutorials - Gradio And Comet Guide
|
Image classification is a central task in computer vision. Building better classifiers to classify what object is present in a picture is an active area of research, as it has applications stretching from facial recognition to manufacturing quality control.
State-of-the-art image classifiers are based on the _transformers_ architectures, originally popularized for NLP tasks. Such architectures are typically called vision transformers (ViT). Such models are perfect to use with Gradio's _image_ input component, so in this tutorial we will build a web demo to classify images using Gradio. We will be able to build the whole web application in a **single line of Python**, and it will look like the demo on the bottom of the page.
Let's get started!
Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started).
|
Introduction
|
https://gradio.app/guides/image-classification-with-vision-transformers
|
Other Tutorials - Image Classification With Vision Transformers Guide
|
First, we will need an image classification model. For this tutorial, we will use a model from the [Hugging Face Model Hub](https://huggingface.co/models?pipeline_tag=image-classification). The Hub contains thousands of models covering dozens of different machine learning tasks.
Expand the Tasks category on the left sidebar and select "Image Classification" as our task of interest. You will then see all of the models on the Hub that are designed to classify images.
At the time of writing, the most popular one is `google/vit-base-patch16-224`, which has been trained on ImageNet images at a resolution of 224x224 pixels. We will use this model for our demo.
|
Step 1 — Choosing a Vision Image Classification Model
|
https://gradio.app/guides/image-classification-with-vision-transformers
|
Other Tutorials - Image Classification With Vision Transformers Guide
|
When using a model from the Hugging Face Hub, we do not need to define the input or output components for the demo. Similarly, we do not need to be concerned with the details of preprocessing or postprocessing.
All of these are automatically inferred from the model tags.
Besides the import statement, it only takes a single line of Python to load and launch the demo.
We use the `gr.Interface.load()` method and pass in the path to the model including the `huggingface/` to designate that it is from the Hugging Face Hub.
```python
import gradio as gr
gr.Interface.load(
"huggingface/google/vit-base-patch16-224",
examples=["alligator.jpg", "laptop.jpg"]).launch()
```
Notice that we have added one more parameter, the `examples`, which allows us to prepopulate our interfaces with a few predefined examples.
This produces the following interface, which you can try right here in your browser. When you input an image, it is automatically preprocessed and sent to the Hugging Face Hub API, where it is passed through the model and returned as a human-interpretable prediction. Try uploading your own image!
<gradio-app space="gradio/vision-transformer">
---
And you're done! In one line of code, you have built a web demo for an image classifier. If you'd like to share with others, try setting `share=True` when you `launch()` the Interface!
|
Step 2 — Loading the Vision Transformer Model with Gradio
|
https://gradio.app/guides/image-classification-with-vision-transformers
|
Other Tutorials - Image Classification With Vision Transformers Guide
|
In this Guide, we'll walk you through:
- Introduction of Gradio, and Hugging Face Spaces, and Wandb
- How to setup a Gradio demo using the Wandb integration for JoJoGAN
- How to contribute your own Gradio demos after tracking your experiments on wandb to the Wandb organization on Hugging Face
|
Introduction
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
Weights and Biases (W&B) allows data scientists and machine learning scientists to track their machine learning experiments at every stage, from training to production. Any metric can be aggregated over samples and shown in panels in a customizable and searchable dashboard, like below:
<img alt="Screen Shot 2022-08-01 at 5 54 59 PM" src="https://user-images.githubusercontent.com/81195143/182252755-4a0e1ca8-fd25-40ff-8c91-c9da38aaa9ec.png">
|
What is Wandb?
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
Gradio
Gradio lets users demo their machine learning models as a web app, all in a few lines of Python. Gradio wraps any Python function (such as a machine learning model's inference function) into a user interface and the demos can be launched inside jupyter notebooks, colab notebooks, as well as embedded in your own website and hosted on Hugging Face Spaces for free.
Get started [here](https://gradio.app/getting_started)
Hugging Face Spaces
Hugging Face Spaces is a free hosting option for Gradio demos. Spaces comes with 3 SDK options: Gradio, Streamlit and Static HTML demos. Spaces can be public or private and the workflow is similar to github repos. There are over 2000+ spaces currently on Hugging Face. Learn more about spaces [here](https://huggingface.co/spaces/launch).
|
What are Hugging Face Spaces & Gradio?
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
Now, let's walk you through how to do this on your own. We'll make the assumption that you're new to W&B and Gradio for the purposes of this tutorial.
Let's get started!
1. Create a W&B account
Follow [these quick instructions](https://app.wandb.ai/login) to create your free account if you don’t have one already. It shouldn't take more than a couple minutes. Once you're done (or if you've already got an account), next, we'll run a quick colab.
2. Open Colab Install Gradio and W&B
We'll be following along with the colab provided in the JoJoGAN repo with some minor modifications to use Wandb and Gradio more effectively.
[](https://colab.research.google.com/github/mchong6/JoJoGAN/blob/main/stylize.ipynb)
Install Gradio and Wandb at the top:
```sh
pip install gradio wandb
```
3. Finetune StyleGAN and W&B experiment tracking
This next step will open a W&B dashboard to track your experiments and a gradio panel showing pretrained models to choose from a drop down menu from a Gradio Demo hosted on Huggingface Spaces. Here's the code you need for that:
```python
alpha = 1.0
alpha = 1-alpha
preserve_color = True
num_iter = 100
log_interval = 50
samples = []
column_names = ["Reference (y)", "Style Code(w)", "Real Face Image(x)"]
wandb.init(project="JoJoGAN")
config = wandb.config
config.num_iter = num_iter
config.preserve_color = preserve_color
wandb.log(
{"Style reference": [wandb.Image(transforms.ToPILImage()(target_im))]},
step=0)
load discriminator for perceptual loss
discriminator = Discriminator(1024, 2).eval().to(device)
ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage)
discriminator.load_state_dict(ckpt["d"], strict=False)
reset generator
del generator
generator = deepcopy(original_generator)
g_optim = optim.Adam(generator.parameters(),
|
Setting up a Gradio Demo for JoJoGAN
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
: storage)
discriminator.load_state_dict(ckpt["d"], strict=False)
reset generator
del generator
generator = deepcopy(original_generator)
g_optim = optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99))
Which layers to swap for generating a family of plausible real images -> fake image
if preserve_color:
id_swap = [9,11,15,16,17]
else:
id_swap = list(range(7, generator.n_latent))
for idx in tqdm(range(num_iter)):
mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim]).to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1)
in_latent = latents.clone()
in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap]
img = generator(in_latent, input_is_latent=True)
with torch.no_grad():
real_feat = discriminator(targets)
fake_feat = discriminator(img)
loss = sum([F.l1_loss(a, b) for a, b in zip(fake_feat, real_feat)])/len(fake_feat)
wandb.log({"loss": loss}, step=idx)
if idx % log_interval == 0:
generator.eval()
my_sample = generator(my_w, input_is_latent=True)
generator.train()
my_sample = transforms.ToPILImage()(utils.make_grid(my_sample, normalize=True, range=(-1, 1)))
wandb.log(
{"Current stylization": [wandb.Image(my_sample)]},
step=idx)
table_data = [
wandb.Image(transforms.ToPILImage()(target_im)),
wandb.Image(img),
wandb.Image(my_sample),
]
samples.append(table_data)
g_optim.zero_grad()
loss.backward()
g_optim.step()
out_table = wandb.Table(data=samples, columns=column_names)
wandb.log({"Current Samples": out_table})
```
4. Save, Download, and Load Model
Here's how to save and download your model.
```python
from PIL import Image
import torch
torch.backends.cudnn.benchmark = True
from torchvision impor
|
Setting up a Gradio Demo for JoJoGAN
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
ave, Download, and Load Model
Here's how to save and download your model.
```python
from PIL import Image
import torch
torch.backends.cudnn.benchmark = True
from torchvision import transforms, utils
from util import *
import math
import random
import numpy as np
from torch import nn, autograd, optim
from torch.nn import functional as F
from tqdm import tqdm
import lpips
from model import *
from e4e_projection import projection as e4e_projection
from copy import deepcopy
import imageio
import os
import sys
import torchvision.transforms as transforms
from argparse import Namespace
from e4e.models.psp import pSp
from util import *
from huggingface_hub import hf_hub_download
from google.colab import files
torch.save({"g": generator.state_dict()}, "your-model-name.pt")
files.download('your-model-name.pt')
latent_dim = 512
device="cuda"
model_path_s = hf_hub_download(repo_id="akhaliq/jojogan-stylegan2-ffhq-config-f", filename="stylegan2-ffhq-config-f.pt")
original_generator = Generator(1024, latent_dim, 8, 2).to(device)
ckpt = torch.load(model_path_s, map_location=lambda storage, loc: storage)
original_generator.load_state_dict(ckpt["g_ema"], strict=False)
mean_latent = original_generator.mean_latent(10000)
generator = deepcopy(original_generator)
ckpt = torch.load("/content/JoJoGAN/your-model-name.pt", map_location=lambda storage, loc: storage)
generator.load_state_dict(ckpt["g"], strict=False)
generator.eval()
plt.rcParams['figure.dpi'] = 150
transform = transforms.Compose(
[
transforms.Resize((1024, 1024)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
def inference(img):
img.save('out.jpg')
aligned_face = align_face('out.jpg')
my_w = e4e_projection(aligned_face, "out.pt", device).unsqueeze(0)
|
Setting up a Gradio Demo for JoJoGAN
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
.5, 0.5)),
]
)
def inference(img):
img.save('out.jpg')
aligned_face = align_face('out.jpg')
my_w = e4e_projection(aligned_face, "out.pt", device).unsqueeze(0)
with torch.no_grad():
my_sample = generator(my_w, input_is_latent=True)
npimage = my_sample[0].cpu().permute(1, 2, 0).detach().numpy()
imageio.imwrite('filename.jpeg', npimage)
return 'filename.jpeg'
````
5. Build a Gradio Demo
```python
import gradio as gr
title = "JoJoGAN"
description = "Gradio Demo for JoJoGAN: One Shot Face Stylization. To use it, simply upload your image, or click one of the examples to load them. Read more at the links below."
demo = gr.Interface(
inference,
gr.Image(type="pil"),
gr.Image(type="file"),
title=title,
description=description
)
demo.launch(share=True)
```
6. Integrate Gradio into your W&B Dashboard
The last step—integrating your Gradio demo with your W&B dashboard—is just one extra line:
```python
demo.integrate(wandb=wandb)
```
Once you call integrate, a demo will be created and you can integrate it into your dashboard or report.
Outside of W&B with Web components, using the `gradio-app` tags, anyone can embed Gradio demos on HF spaces directly into their blogs, websites, documentation, etc.:
```html
<gradio-app space="akhaliq/JoJoGAN"> </gradio-app>
```
7. (Optional) Embed W&B plots in your Gradio App
It's also possible to embed W&B plots within Gradio apps. To do so, you can create a W&B Report of your plots and
embed them within your Gradio app within a `gr.HTML` block.
The Report will need to be public and you will need to wrap the URL within an iFrame like this:
```python
import gradio as gr
def wandb_report(url):
iframe = f'<iframe src={url} style="border:none;height:1024px;width:100%">'
return gr.HTML(iframe)
with gr.Blocks() a
|
Setting up a Gradio Demo for JoJoGAN
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
``python
import gradio as gr
def wandb_report(url):
iframe = f'<iframe src={url} style="border:none;height:1024px;width:100%">'
return gr.HTML(iframe)
with gr.Blocks() as demo:
report_url = 'https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx'
report = wandb_report(report_url)
demo.launch(share=True)
```
|
Setting up a Gradio Demo for JoJoGAN
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
We hope you enjoyed this brief demo of embedding a Gradio demo to a W&B report! Thanks for making it to the end. To recap:
- Only one single reference image is needed for fine-tuning JoJoGAN which usually takes about 1 minute on a GPU in colab. After training, style can be applied to any input image. Read more in the paper.
- W&B tracks experiments with just a few lines of code added to a colab and you can visualize, sort, and understand your experiments in a single, centralized dashboard.
- Gradio, meanwhile, demos the model in a user friendly interface to share anywhere on the web.
|
Conclusion
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
- Create an account on Hugging Face [here](https://huggingface.co/join).
- Add Gradio Demo under your username, see this [course](https://huggingface.co/course/chapter9/4?fw=pt) for setting up Gradio Demo on Hugging Face.
- Request to join wandb organization [here](https://huggingface.co/wandb).
- Once approved transfer model from your username to Wandb organization
|
How to contribute Gradio demos on HF spaces on the Wandb organization
|
https://gradio.app/guides/Gradio-and-Wandb-Integration
|
Other Tutorials - Gradio And Wandb Integration Guide
|
The Hugging Face Hub is a central platform that has hundreds of thousands of [models](https://huggingface.co/models), [datasets](https://huggingface.co/datasets) and [demos](https://huggingface.co/spaces) (also known as Spaces).
Gradio has multiple features that make it extremely easy to leverage existing models and Spaces on the Hub. This guide walks through these features.
|
Introduction
|
https://gradio.app/guides/using-hugging-face-integrations
|
Other Tutorials - Using Hugging Face Integrations Guide
|
Hugging Face has a service called [Serverless Inference Endpoints](https://huggingface.co/docs/api-inference/index), which allows you to send HTTP requests to models on the Hub. The API includes a generous free tier, and you can switch to [dedicated Inference Endpoints](https://huggingface.co/inference-endpoints/dedicated) when you want to use it in production. Gradio integrates directly with Serverless Inference Endpoints so that you can create a demo simply by specifying a model's name (e.g. `Helsinki-NLP/opus-mt-en-es`), like this:
```python
import gradio as gr
demo = gr.load("Helsinki-NLP/opus-mt-en-es", src="models")
demo.launch()
```
For any Hugging Face model supported in Inference Endpoints, Gradio automatically infers the expected input and output and make the underlying server calls, so you don't have to worry about defining the prediction function.
Notice that we just put specify the model name and state that the `src` should be `models` (Hugging Face's Model Hub). There is no need to install any dependencies (except `gradio`) since you are not loading the model on your computer.
You might notice that the first inference takes a little bit longer. This happens since the Inference Endpoints is loading the model in the server. You get some benefits afterward:
- The inference will be much faster.
- The server caches your requests.
- You get built-in automatic scaling.
|
Demos with the Hugging Face Inference Endpoints
|
https://gradio.app/guides/using-hugging-face-integrations
|
Other Tutorials - Using Hugging Face Integrations Guide
|
[Hugging Face Spaces](https://hf.co/spaces) allows anyone to host their Gradio demos freely, and uploading your Gradio demos take a couple of minutes. You can head to [hf.co/new-space](https://huggingface.co/new-space), select the Gradio SDK, create an `app.py` file, and voila! You have a demo you can share with anyone else. To learn more, read [this guide how to host on Hugging Face Spaces using the website](https://huggingface.co/blog/gradio-spaces).
Alternatively, you can create a Space programmatically, making use of the [huggingface_hub client library](https://huggingface.co/docs/huggingface_hub/index) library. Here's an example:
```python
from huggingface_hub import (
create_repo,
get_full_repo_name,
upload_file,
)
create_repo(name=target_space_name, token=hf_token, repo_type="space", space_sdk="gradio")
repo_name = get_full_repo_name(model_id=target_space_name, token=hf_token)
file_url = upload_file(
path_or_fileobj="file.txt",
path_in_repo="app.py",
repo_id=repo_name,
repo_type="space",
token=hf_token,
)
```
Here, `create_repo` creates a gradio repo with the target name under a specific account using that account's Write Token. `repo_name` gets the full repo name of the related repo. Finally `upload_file` uploads a file inside the repo with the name `app.py`.
|
Hosting your Gradio demos on Spaces
|
https://gradio.app/guides/using-hugging-face-integrations
|
Other Tutorials - Using Hugging Face Integrations Guide
|
You can also use and remix existing Gradio demos on Hugging Face Spaces. For example, you could take two existing Gradio demos on Spaces and put them as separate tabs and create a new demo. You can run this new demo locally, or upload it to Spaces, allowing endless possibilities to remix and create new demos!
Here's an example that does exactly that:
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Tab("Translate to Spanish"):
gr.load("gradio/en2es", src="spaces")
with gr.Tab("Translate to French"):
gr.load("abidlabs/en2fr", src="spaces")
demo.launch()
```
Notice that we use `gr.load()`, the same method we used to load models using Inference Endpoints. However, here we specify that the `src` is `spaces` (Hugging Face Spaces).
Note: loading a Space in this way may result in slight differences from the original Space. In particular, any attributes that apply to the entire Blocks, such as the theme or custom CSS/JS, will not be loaded. You can copy these properties from the Space you are loading into your own `Blocks` object.
|
Loading demos from Spaces
|
https://gradio.app/guides/using-hugging-face-integrations
|
Other Tutorials - Using Hugging Face Integrations Guide
|
Hugging Face's popular `transformers` library has a very easy-to-use abstraction, [`pipeline()`](https://huggingface.co/docs/transformers/v4.16.2/en/main_classes/pipelinestransformers.pipeline) that handles most of the complex code to offer a simple API for common tasks. By specifying the task and an (optional) model, you can build a demo around an existing model with few lines of Python:
```python
import gradio as gr
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
def predict(text):
return pipe(text)[0]["translation_text"]
demo = gr.Interface(
fn=predict,
inputs='text',
outputs='text',
)
demo.launch()
```
But `gradio` actually makes it even easier to convert a `pipeline` to a demo, simply by using the `gradio.Interface.from_pipeline` methods, which skips the need to specify the input and output components:
```python
from transformers import pipeline
import gradio as gr
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
demo = gr.Interface.from_pipeline(pipe)
demo.launch()
```
The previous code produces the following interface, which you can try right here in your browser:
<gradio-app space="gradio/en2es"></gradio-app>
|
Demos with the `Pipeline` in `transformers`
|
https://gradio.app/guides/using-hugging-face-integrations
|
Other Tutorials - Using Hugging Face Integrations Guide
|
That's it! Let's recap the various ways Gradio and Hugging Face work together:
1. You can build a demo around Inference Endpoints without having to load the model, by using `gr.load()`.
2. You host your Gradio demo on Hugging Face Spaces, either using the GUI or entirely in Python.
3. You can load demos from Hugging Face Spaces to remix and create new Gradio demos using `gr.load()`.
4. You can convert a `transformers` pipeline into a Gradio demo using `from_pipeline()`.
🤗
|
Recap
|
https://gradio.app/guides/using-hugging-face-integrations
|
Other Tutorials - Using Hugging Face Integrations Guide
|
It seems that cryptocurrencies, [NFTs](https://www.nytimes.com/interactive/2022/03/18/technology/nft-guide.html), and the web3 movement are all the rage these days! Digital assets are being listed on marketplaces for astounding amounts of money, and just about every celebrity is debuting their own NFT collection. While your crypto assets [may be taxable, such as in Canada](https://www.canada.ca/en/revenue-agency/programs/about-canada-revenue-agency-cra/compliance/digital-currency/cryptocurrency-guide.html), today we'll explore some fun and tax-free ways to generate your own assortment of procedurally generated [CryptoPunks](https://www.larvalabs.com/cryptopunks).
Generative Adversarial Networks, often known just as _GANs_, are a specific class of deep-learning models that are designed to learn from an input dataset to create (_generate!_) new material that is convincingly similar to elements of the original training set. Famously, the website [thispersondoesnotexist.com](https://thispersondoesnotexist.com/) went viral with lifelike, yet synthetic, images of people generated with a model called StyleGAN2. GANs have gained traction in the machine learning world, and are now being used to generate all sorts of images, text, and even [music](https://salu133445.github.io/musegan/)!
Today we'll briefly look at the high-level intuition behind GANs, and then we'll build a small demo around a pre-trained GAN to see what all the fuss is about. Here's a [peek](https://nimaboscarino-cryptopunks.hf.space) at what we're going to be putting together.
Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). To use the pretrained model, also install `torch` and `torchvision`.
|
Introduction
|
https://gradio.app/guides/create-your-own-friends-with-a-gan
|
Other Tutorials - Create Your Own Friends With A Gan Guide
|
Originally proposed in [Goodfellow et al. 2014](https://arxiv.org/abs/1406.2661), GANs are made up of neural networks which compete with the intention of outsmarting each other. One network, known as the _generator_, is responsible for generating images. The other network, the _discriminator_, receives an image at a time from the generator along with a **real** image from the training data set. The discriminator then has to guess: which image is the fake?
The generator is constantly training to create images which are trickier for the discriminator to identify, while the discriminator raises the bar for the generator every time it correctly detects a fake. As the networks engage in this competitive (_adversarial!_) relationship, the images that get generated improve to the point where they become indistinguishable to human eyes!
For a more in-depth look at GANs, you can take a look at [this excellent post on Analytics Vidhya](https://www.analyticsvidhya.com/blog/2021/06/a-detailed-explanation-of-gan-with-implementation-using-tensorflow-and-keras/) or this [PyTorch tutorial](https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html). For now, though, we'll dive into a demo!
|
GANs: a very brief introduction
|
https://gradio.app/guides/create-your-own-friends-with-a-gan
|
Other Tutorials - Create Your Own Friends With A Gan Guide
|
To generate new images with a GAN, you only need the generator model. There are many different architectures that the generator could use, but for this demo we'll use a pretrained GAN generator model with the following architecture:
```python
from torch import nn
class Generator(nn.Module):
Refer to the link below for explanations about nc, nz, and ngf
https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.htmlinputs
def __init__(self, nc=4, nz=100, ngf=64):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
output = self.network(input)
return output
```
We're taking the generator from [this repo by @teddykoker](https://github.com/teddykoker/cryptopunks-gan/blob/main/train.pyL90), where you can also see the original discriminator model structure.
After instantiating the model, we'll load in the weights from the Hugging Face Hub, stored at [nateraw/cryptopunks-gan](https://huggingface.co/nateraw/cryptopunks-gan):
```python
from huggingface_hub import hf_hub_download
import torch
model = Generator()
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) Use 'cuda' if you have a GPU available
```
|
Step 1 — Create the Generator model
|
https://gradio.app/guides/create-your-own-friends-with-a-gan
|
Other Tutorials - Create Your Own Friends With A Gan Guide
|
The `predict` function is the key to making Gradio work! Whatever inputs we choose through the Gradio interface will get passed through our `predict` function, which should operate on the inputs and generate outputs that we can display with Gradio output components. For GANs it's common to pass random noise into our model as the input, so we'll generate a tensor of random numbers and pass that through the model. We can then use `torchvision`'s `save_image` function to save the output of the model as a `png` file, and return the file name:
```python
from torchvision.utils import save_image
def predict(seed):
num_punks = 4
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
```
We're giving our `predict` function a `seed` parameter, so that we can fix the random tensor generation with a seed. We'll then be able to reproduce punks if we want to see them again by passing in the same seed.
_Note!_ Our model needs an input tensor of dimensions 100x1x1 to do a single inference, or (BatchSize)x100x1x1 for generating a batch of images. In this demo we'll start by generating 4 punks at a time.
|
Step 2 — Defining a `predict` function
|
https://gradio.app/guides/create-your-own-friends-with-a-gan
|
Other Tutorials - Create Your Own Friends With A Gan Guide
|
At this point you can even run the code you have with `predict(<SOME_NUMBER>)`, and you'll find your freshly generated punks in your file system at `./punks.png`. To make a truly interactive demo, though, we'll build out a simple interface with Gradio. Our goals here are to:
- Set a slider input so users can choose the "seed" value
- Use an image component for our output to showcase the generated punks
- Use our `predict()` to take the seed and generate the images
With `gr.Interface()`, we can define all of that with a single function call:
```python
import gradio as gr
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
],
outputs="image",
).launch()
```
|
Step 3 — Creating a Gradio interface
|
https://gradio.app/guides/create-your-own-friends-with-a-gan
|
Other Tutorials - Create Your Own Friends With A Gan Guide
|
Generating 4 punks at a time is a good start, but maybe we'd like to control how many we want to make each time. Adding more inputs to our Gradio interface is as simple as adding another item to the `inputs` list that we pass to `gr.Interface`:
```python
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
gr.Slider(4, 64, label='Number of Punks', step=1, default=10), Adding another slider!
],
outputs="image",
).launch()
```
The new input will be passed to our `predict()` function, so we have to make some changes to that function to accept a new parameter:
```python
def predict(seed, num_punks):
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
```
When you relaunch your interface, you should see a second slider that'll let you control the number of punks!
|
Step 4 — Even more punks!
|
https://gradio.app/guides/create-your-own-friends-with-a-gan
|
Other Tutorials - Create Your Own Friends With A Gan Guide
|
Your Gradio app is pretty much good to go, but you can add a few extra things to really make it ready for the spotlight ✨
We can add some examples that users can easily try out by adding this to the `gr.Interface`:
```python
gr.Interface(
...
keep everything as it is, and then add
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
).launch(cache_examples=True) cache_examples is optional
```
The `examples` parameter takes a list of lists, where each item in the sublists is ordered in the same order that we've listed the `inputs`. So in our case, `[seed, num_punks]`. Give it a try!
You can also try adding a `title`, `description`, and `article` to the `gr.Interface`. Each of those parameters accepts a string, so try it out and see what happens 👀 `article` will also accept HTML, as [explored in a previous guide](/guides/key-features/descriptive-content)!
When you're all done, you may end up with something like [this](https://nimaboscarino-cryptopunks.hf.space).
For reference, here is our full code:
```python
import torch
from torch import nn
from huggingface_hub import hf_hub_download
from torchvision.utils import save_image
import gradio as gr
class Generator(nn.Module):
Refer to the link below for explanations about nc, nz, and ngf
https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.htmlinputs
def __init__(self, nc=4, nz=100, ngf=64):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self,
|
Step 5 - Polishing it up
|
https://gradio.app/guides/create-your-own-friends-with-a-gan
|
Other Tutorials - Create Your Own Friends With A Gan Guide
|
4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
output = self.network(input)
return output
model = Generator()
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) Use 'cuda' if you have a GPU available
def predict(seed, num_punks):
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
gr.Slider(4, 64, label='Number of Punks', step=1, default=10),
],
outputs="image",
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
).launch(cache_examples=True)
```
---
Congratulations! You've built out your very own GAN-powered CryptoPunks generator, with a fancy Gradio interface that makes it easy for anyone to use. Now you can [scour the Hub for more GANs](https://huggingface.co/models?other=gan) (or train your own) and continue making even more awesome demos 🤗
|
Step 5 - Polishing it up
|
https://gradio.app/guides/create-your-own-friends-with-a-gan
|
Other Tutorials - Create Your Own Friends With A Gan Guide
|
First of all, we need some data to visualize. Following this [excellent guide](https://supabase.com/blog/loading-data-supabase-python), we'll create fake commerce data and put it in Supabase.
1\. Start by creating a new project in Supabase. Once you're logged in, click the "New Project" button
2\. Give your project a name and database password. You can also choose a pricing plan (for our purposes, the Free Tier is sufficient!)
3\. You'll be presented with your API keys while the database spins up (can take up to 2 minutes).
4\. Click on "Table Editor" (the table icon) in the left pane to create a new table. We'll create a single table called `Product`, with the following schema:
<center>
<table>
<tr><td>product_id</td><td>int8</td></tr>
<tr><td>inventory_count</td><td>int8</td></tr>
<tr><td>price</td><td>float8</td></tr>
<tr><td>product_name</td><td>varchar</td></tr>
</table>
</center>
5\. Click Save to save the table schema.
Our table is now ready!
|
Create a table in Supabase
|
https://gradio.app/guides/creating-a-dashboard-from-supabase-data
|
Other Tutorials - Creating A Dashboard From Supabase Data Guide
|
The next step is to write data to a Supabase dataset. We will use the Supabase Python library to do this.
6\. Install `supabase` by running the following command in your terminal:
```bash
pip install supabase
```
7\. Get your project URL and API key. Click the Settings (gear icon) on the left pane and click 'API'. The URL is listed in the Project URL box, while the API key is listed in Project API keys (with the tags `service_role`, `secret`)
8\. Now, run the following Python script to write some fake data to the table (note you have to put the values of `SUPABASE_URL` and `SUPABASE_SECRET_KEY` from step 7):
```python
import supabase
Initialize the Supabase client
client = supabase.create_client('SUPABASE_URL', 'SUPABASE_SECRET_KEY')
Define the data to write
import random
main_list = []
for i in range(10):
value = {'product_id': i,
'product_name': f"Item {i}",
'inventory_count': random.randint(1, 100),
'price': random.random()*100
}
main_list.append(value)
Write the data to the table
data = client.table('Product').insert(main_list).execute()
```
Return to your Supabase dashboard and refresh the page, you should now see 10 rows populated in the `Product` table!
|
Write data to Supabase
|
https://gradio.app/guides/creating-a-dashboard-from-supabase-data
|
Other Tutorials - Creating A Dashboard From Supabase Data Guide
|
Finally, we will read the data from the Supabase dataset using the same `supabase` Python library and create a realtime dashboard using `gradio`.
Note: We repeat certain steps in this section (like creating the Supabase client) in case you did not go through the previous sections. As described in Step 7, you will need the project URL and API Key for your database.
9\. Write a function that loads the data from the `Product` table and returns it as a pandas Dataframe:
```python
import supabase
import pandas as pd
client = supabase.create_client('SUPABASE_URL', 'SUPABASE_SECRET_KEY')
def read_data():
response = client.table('Product').select("*").execute()
df = pd.DataFrame(response.data)
return df
```
10\. Create a small Gradio Dashboard with 2 Barplots that plots the prices and inventories of all of the items every minute and updates in real-time:
```python
import gradio as gr
with gr.Blocks() as dashboard:
with gr.Row():
gr.BarPlot(read_data, x="product_id", y="price", title="Prices", every=gr.Timer(60))
gr.BarPlot(read_data, x="product_id", y="inventory_count", title="Inventory", every=gr.Timer(60))
dashboard.queue().launch()
```
Notice that by passing in a function to `gr.BarPlot()`, we have the BarPlot query the database as soon as the web app loads (and then again every 60 seconds because of the `every` parameter). Your final dashboard should look something like this:
<gradio-app space="gradio/supabase"></gradio-app>
|
Visualize the Data in a Real-Time Gradio Dashboard
|
https://gradio.app/guides/creating-a-dashboard-from-supabase-data
|
Other Tutorials - Creating A Dashboard From Supabase Data Guide
|
That's it! In this tutorial, you learned how to write data to a Supabase dataset, and then read that data and plot the results as bar plots. If you update the data in the Supabase database, you'll notice that the Gradio dashboard will update within a minute.
Try adding more plots and visualizations to this example (or with a different dataset) to build a more complex dashboard!
|
Conclusion
|
https://gradio.app/guides/creating-a-dashboard-from-supabase-data
|
Other Tutorials - Creating A Dashboard From Supabase Data Guide
|
By default, every Gradio demo includes a built-in queuing system that scales to thousands of requests. When a user of your app submits a request (i.e. submits an input to your function), Gradio adds the request to the queue, and requests are processed in order, generally speaking (this is not exactly true, as discussed below). When the user's request has finished processing, the Gradio server returns the result back to the user using server-side events (SSE). The SSE protocol has several advantages over simply using HTTP POST requests:
(1) They do not time out -- most browsers raise a timeout error if they do not get a response to a POST request after a short period of time (e.g. 1 min). This can be a problem if your inference function takes longer than 1 minute to run or if many people are trying out your demo at the same time, resulting in increased latency.
(2) They allow the server to send multiple updates to the frontend. This means, for example, that the server can send a real-time ETA of how long your prediction will take to complete.
To configure the queue, simply call the `.queue()` method before launching an `Interface`, `TabbedInterface`, `ChatInterface` or any `Blocks`. Here's an example:
```py
import gradio as gr
app = gr.Interface(lambda x:x, "image", "image")
app.queue() <-- Sets up a queue with default parameters
app.launch()
```
**How Requests are Processed from the Queue**
When a Gradio server is launched, a pool of threads is used to execute requests from the queue. By default, the maximum size of this thread pool is `40` (which is the default inherited from FastAPI, on which the Gradio server is based). However, this does *not* mean that 40 requests are always processed in parallel from the queue.
Instead, Gradio uses a **single-function-single-worker** model by default. This means that each worker thread is only assigned a single function from among all of the functions that could be part of your Gradio app. This ensures that you do
|
Overview of Gradio's Queueing System
|
https://gradio.app/guides/setting-up-a-demo-for-maximum-performance
|
Other Tutorials - Setting Up A Demo For Maximum Performance Guide
|
-single-worker** model by default. This means that each worker thread is only assigned a single function from among all of the functions that could be part of your Gradio app. This ensures that you do not see, for example, out-of-memory errors, due to multiple workers calling a machine learning model at the same time. Suppose you have 3 functions in your Gradio app: A, B, and C. And you see the following sequence of 7 requests come in from users using your app:
```
1 2 3 4 5 6 7
-------------
A B A A C B A
```
Initially, 3 workers will get dispatched to handle requests 1, 2, and 5 (corresponding to functions: A, B, C). As soon as any of these workers finish, they will start processing the next function in the queue of the same function type, e.g. the worker that finished processing request 1 will start processing request 3, and so on.
If you want to change this behavior, there are several parameters that can be used to configure the queue and help reduce latency. Let's go through them one-by-one.
The `default_concurrency_limit` parameter in `queue()`
The first parameter we will explore is the `default_concurrency_limit` parameter in `queue()`. This controls how many workers can execute the same event. By default, this is set to `1`, but you can set it to a higher integer: `2`, `10`, or even `None` (in the last case, there is no limit besides the total number of available workers).
This is useful, for example, if your Gradio app does not call any resource-intensive functions. If your app only queries external APIs, then you can set the `default_concurrency_limit` much higher. Increasing this parameter can **linearly multiply the capacity of your server to handle requests**.
So why not set this parameter much higher all the time? Keep in mind that since requests are processed in parallel, each request will consume memory to store the data and weights for processing. This means that you might get out-of-memory errors if you increase the `default_concurrenc
|
Overview of Gradio's Queueing System
|
https://gradio.app/guides/setting-up-a-demo-for-maximum-performance
|
Other Tutorials - Setting Up A Demo For Maximum Performance Guide
|
sts are processed in parallel, each request will consume memory to store the data and weights for processing. This means that you might get out-of-memory errors if you increase the `default_concurrency_limit` too high. You may also start to get diminishing returns if the `default_concurrency_limit` is too high because of costs of switching between different worker threads.
**Recommendation**: Increase the `default_concurrency_limit` parameter as high as you can while you continue to see performance gains or until you hit memory limits on your machine. You can [read about Hugging Face Spaces machine specs here](https://huggingface.co/docs/hub/spaces-overview).
The `concurrency_limit` parameter in events
You can also set the number of requests that can be processed in parallel for each event individually. These take priority over the `default_concurrency_limit` parameter described previously.
To do this, set the `concurrency_limit` parameter of any event listener, e.g. `btn.click(..., concurrency_limit=20)` or in the `Interface` or `ChatInterface` classes: e.g. `gr.Interface(..., concurrency_limit=20)`. By default, this parameter is set to the global `default_concurrency_limit`.
The `max_threads` parameter in `launch()`
If your demo uses non-async functions, e.g. `def` instead of `async def`, they will be run in a threadpool. This threadpool has a size of 40 meaning that only 40 threads can be created to run your non-async functions. If you are running into this limit, you can increase the threadpool size with `max_threads`. The default value is 40.
Tip: You should use async functions whenever possible to increase the number of concurrent requests your app can handle. Quick functions that are not CPU-bound are good candidates to be written as `async`. This [guide](https://fastapi.tiangolo.com/async/) is a good primer on the concept.
The `max_size` parameter in `queue()`
A more blunt way to reduce the wait times is simply to prevent too many pe
|
Overview of Gradio's Queueing System
|
https://gradio.app/guides/setting-up-a-demo-for-maximum-performance
|
Other Tutorials - Setting Up A Demo For Maximum Performance Guide
|
is [guide](https://fastapi.tiangolo.com/async/) is a good primer on the concept.
The `max_size` parameter in `queue()`
A more blunt way to reduce the wait times is simply to prevent too many people from joining the queue in the first place. You can set the maximum number of requests that the queue processes using the `max_size` parameter of `queue()`. If a request arrives when the queue is already of the maximum size, it will not be allowed to join the queue and instead, the user will receive an error saying that the queue is full and to try again. By default, `max_size=None`, meaning that there is no limit to the number of users that can join the queue.
Paradoxically, setting a `max_size` can often improve user experience because it prevents users from being dissuaded by very long queue wait times. Users who are more interested and invested in your demo will keep trying to join the queue, and will be able to get their results faster.
**Recommendation**: For a better user experience, set a `max_size` that is reasonable given your expectations of how long users might be willing to wait for a prediction.
The `max_batch_size` parameter in events
Another way to increase the parallelism of your Gradio demo is to write your function so that it can accept **batches** of inputs. Most deep learning models can process batches of samples more efficiently than processing individual samples.
If you write your function to process a batch of samples, Gradio will automatically batch incoming requests together and pass them into your function as a batch of samples. You need to set `batch` to `True` (by default it is `False`) and set a `max_batch_size` (by default it is `4`) based on the maximum number of samples your function is able to handle. These two parameters can be passed into `gr.Interface()` or to an event in Blocks such as `.click()`.
While setting a batch is conceptually similar to having workers process requests in parallel, it is often _faster_ than set
|
Overview of Gradio's Queueing System
|
https://gradio.app/guides/setting-up-a-demo-for-maximum-performance
|
Other Tutorials - Setting Up A Demo For Maximum Performance Guide
|
e passed into `gr.Interface()` or to an event in Blocks such as `.click()`.
While setting a batch is conceptually similar to having workers process requests in parallel, it is often _faster_ than setting the `concurrency_count` for deep learning models. The downside is that you might need to adapt your function a little bit to accept batches of samples instead of individual samples.
Here's an example of a function that does _not_ accept a batch of inputs -- it processes a single input at a time:
```py
import time
def trim_words(word, length):
return word[:int(length)]
```
Here's the same function rewritten to take in a batch of samples:
```py
import time
def trim_words(words, lengths):
trimmed_words = []
for w, l in zip(words, lengths):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
```
The second function can be used with `batch=True` and an appropriate `max_batch_size` parameter.
**Recommendation**: If possible, write your function to accept batches of samples, and then set `batch` to `True` and the `max_batch_size` as high as possible based on your machine's memory limits.
|
Overview of Gradio's Queueing System
|
https://gradio.app/guides/setting-up-a-demo-for-maximum-performance
|
Other Tutorials - Setting Up A Demo For Maximum Performance Guide
|
If you have done everything above, and your demo is still not fast enough, you can upgrade the hardware that your model is running on. Changing the model from running on CPUs to running on GPUs will usually provide a 10x-50x increase in inference time for deep learning models.
It is particularly straightforward to upgrade your Hardware on Hugging Face Spaces. Simply click on the "Settings" tab in your Space and choose the Space Hardware you'd like.
While you might need to adapt portions of your machine learning inference code to run on a GPU (here's a [handy guide](https://cnvrg.io/pytorch-cuda/) if you are using PyTorch), Gradio is completely agnostic to the choice of hardware and will work completely fine if you use it with CPUs, GPUs, TPUs, or any other hardware!
Note: your GPU memory is different than your CPU memory, so if you upgrade your hardware,
you might need to adjust the value of the `default_concurrency_limit` parameter described above.
|
Upgrading your Hardware (GPUs, TPUs, etc.)
|
https://gradio.app/guides/setting-up-a-demo-for-maximum-performance
|
Other Tutorials - Setting Up A Demo For Maximum Performance Guide
|
Congratulations! You know how to set up a Gradio demo for maximum performance. Good luck on your next viral demo!
|
Conclusion
|
https://gradio.app/guides/setting-up-a-demo-for-maximum-performance
|
Other Tutorials - Setting Up A Demo For Maximum Performance Guide
|
Gradio is a Python library that allows you to quickly create customizable web apps for your machine learning models and data processing pipelines. Gradio apps can be deployed on [Hugging Face Spaces](https://hf.space) for free.
In some cases though, you might want to deploy a Gradio app on your own web server. You might already be using [Nginx](https://www.nginx.com/), a highly performant web server, to serve your website (say `https://www.example.com`), and you want to attach Gradio to a specific subpath on your website (e.g. `https://www.example.com/gradio-demo`).
In this Guide, we will guide you through the process of running a Gradio app behind Nginx on your own web server to achieve this.
**Prerequisites**
1. A Linux web server with [Nginx installed](https://www.nginx.com/blog/setting-up-nginx/) and [Gradio installed](/quickstart)
2. A working Gradio app saved as a python file on your web server
|
Introduction
|
https://gradio.app/guides/running-gradio-on-your-web-server-with-nginx
|
Other Tutorials - Running Gradio On Your Web Server With Nginx Guide
|
1. Start by editing the Nginx configuration file on your web server. By default, this is located at: `/etc/nginx/nginx.conf`
In the `http` block, add the following line to include server block configurations from a separate file:
```bash
include /etc/nginx/sites-enabled/*;
```
2. Create a new file in the `/etc/nginx/sites-available` directory (create the directory if it does not already exist), using a filename that represents your app, for example: `sudo nano /etc/nginx/sites-available/my_gradio_app`
3. Paste the following into your file editor:
```bash
server {
listen 80;
server_name example.com www.example.com; Change this to your domain name
location /gradio-demo/ { Change this if you'd like to server your Gradio app on a different path
proxy_pass http://127.0.0.1:7860/; Change this if your Gradio app will be running on a different port
proxy_buffering off;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
```
Tip: Setting the `X-Forwarded-Host` and `X-Forwarded-Proto` headers is important as Gradio uses these, in conjunction with the `root_path` parameter discussed below, to construct the public URL that your app is being served on. Gradio uses the public URL to fetch various static assets. If these headers are not set, your Gradio app may load in a broken state.
*Note:* The `$host` variable does not include the host port. If you are serving your Gradio application on a raw IP address and port, you should use the `$http_host` variable instead, in these lines:
```bash
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Host $host;
```
|
Editing your Nginx configuration file
|
https://gradio.app/guides/running-gradio-on-your-web-server-with-nginx
|
Other Tutorials - Running Gradio On Your Web Server With Nginx Guide
|
1. Before you launch your Gradio app, you'll need to set the `root_path` to be the same as the subpath that you specified in your nginx configuration. This is necessary for Gradio to run on any subpath besides the root of the domain.
*Note:* Instead of a subpath, you can also provide a complete URL for `root_path` (beginning with `http` or `https`) in which case the `root_path` is treated as an absolute URL instead of a URL suffix (but in this case, you'll need to update the `root_path` if the domain changes).
Here's a simple example of a Gradio app with a custom `root_path` corresponding to the Nginx configuration above.
```python
import gradio as gr
import time
def test(x):
time.sleep(4)
return x
gr.Interface(test, "textbox", "textbox").queue().launch(root_path="/gradio-demo")
```
2. Start a `tmux` session by typing `tmux` and pressing enter (optional)
It's recommended that you run your Gradio app in a `tmux` session so that you can keep it running in the background easily
3. Then, start your Gradio app. Simply type in `python` followed by the name of your Gradio python file. By default, your app will run on `localhost:7860`, but if it starts on a different port, you will need to update the nginx configuration file above.
|
Run your Gradio app on your web server
|
https://gradio.app/guides/running-gradio-on-your-web-server-with-nginx
|
Other Tutorials - Running Gradio On Your Web Server With Nginx Guide
|
1. If you are in a tmux session, exit by typing CTRL+B (or CMD+B), followed by the "D" key.
2. Finally, restart nginx by running `sudo systemctl restart nginx`.
And that's it! If you visit `https://example.com/gradio-demo` on your browser, you should see your Gradio app running there
|
Restart Nginx
|
https://gradio.app/guides/running-gradio-on-your-web-server-with-nginx
|
Other Tutorials - Running Gradio On Your Web Server With Nginx Guide
|
Encoder functions to send audio as base64-encoded data and images as base64-encoded JPEG.
```python
import base64
import numpy as np
from io import BytesIO
from PIL import Image
def encode_audio(data: np.ndarray) -> dict:
"""Encode audio data (int16 mono) for Gemini."""
return {
"mime_type": "audio/pcm",
"data": base64.b64encode(data.tobytes()).decode("UTF-8"),
}
def encode_image(data: np.ndarray) -> dict:
with BytesIO() as output_bytes:
pil_image = Image.fromarray(data)
pil_image.save(output_bytes, "JPEG")
bytes_data = output_bytes.getvalue()
base64_str = str(base64.b64encode(bytes_data), "utf-8")
return {"mime_type": "image/jpeg", "data": base64_str}
```
|
1) Encoders for audio and images
|
https://gradio.app/guides/create-immersive-demo
|
Other Tutorials - Create Immersive Demo Guide
|
This handler:
- Opens a Gemini Live session on startup
- Receives streaming audio from Gemini and yields it back to the client
- Sends microphone audio as it arrives
- Sends a video frame at most once per second (to avoid flooding the API)
- Optionally sends an uploaded image (`gr.Image`) alongside the webcam frame
```python
import asyncio
import os
import time
import numpy as np
import websockets
from dotenv import load_dotenv
from google import genai
from fastrtc import AsyncAudioVideoStreamHandler, wait_for_item, WebRTCError
load_dotenv()
class GeminiHandler(AsyncAudioVideoStreamHandler):
def __init__(self) -> None:
super().__init__(
"mono",
output_sample_rate=24000,
input_sample_rate=16000,
)
self.audio_queue = asyncio.Queue()
self.video_queue = asyncio.Queue()
self.session = None
self.last_frame_time = 0.0
self.quit = asyncio.Event()
def copy(self) -> "GeminiHandler":
return GeminiHandler()
async def start_up(self):
await self.wait_for_args()
api_key = self.latest_args[3]
hf_token = self.latest_args[4]
if hf_token is None or hf_token == "":
raise WebRTCError("HF Token is required")
os.environ["HF_TOKEN"] = hf_token
client = genai.Client(
api_key=api_key, http_options={"api_version": "v1alpha"}
)
config = {"response_modalities": ["AUDIO"], "system_instruction": "You are an art critic that will critique the artwork passed in as an image to the user. Critique the artwork in a funny and lighthearted way. Be concise and to the point. Be friendly and engaging. Be helpful and informative. Be funny and lighthearted."}
async with client.aio.live.connect(
model="gemini-2.0-flash-exp",
config=config,
) as session:
self.session = session
while not self.quit.is_set():
turn = self.session.receiv
|
2) Implement the Gemini audio-video handler
|
https://gradio.app/guides/create-immersive-demo
|
Other Tutorials - Create Immersive Demo Guide
|
model="gemini-2.0-flash-exp",
config=config,
) as session:
self.session = session
while not self.quit.is_set():
turn = self.session.receive()
try:
async for response in turn:
if data := response.data:
audio = np.frombuffer(data, dtype=np.int16).reshape(1, -1)
self.audio_queue.put_nowait(audio)
except websockets.exceptions.ConnectionClosedOK:
print("connection closed")
break
Video: receive and (optionally) send frames to Gemini
async def video_receive(self, frame: np.ndarray):
self.video_queue.put_nowait(frame)
if self.session and (time.time() - self.last_frame_time > 1.0):
self.last_frame_time = time.time()
await self.session.send(input=encode_image(frame))
If there is an uploaded image passed alongside the WebRTC component,
it will be available in latest_args[2]
if self.latest_args[2] is not None:
await self.session.send(input=encode_image(self.latest_args[2]))
async def video_emit(self) -> np.ndarray:
frame = await wait_for_item(self.video_queue, 0.01)
if frame is not None:
return frame
Fallback while waiting for first frame
return np.zeros((100, 100, 3), dtype=np.uint8)
Audio: forward microphone audio to Gemini
async def receive(self, frame: tuple[int, np.ndarray]) -> None:
_, array = frame
array = array.squeeze() (num_samples,)
audio_message = encode_audio(array)
if self.session:
await self.session.send(input=audio_message)
Audio: emit Gemini’s audio back to the client
async def emit(self):
array = await wait_for_item(self.audio_queue, 0.01)
if array is not None:
return (self.output_sam
|
2) Implement the Gemini audio-video handler
|
https://gradio.app/guides/create-immersive-demo
|
Other Tutorials - Create Immersive Demo Guide
|
Audio: emit Gemini’s audio back to the client
async def emit(self):
array = await wait_for_item(self.audio_queue, 0.01)
if array is not None:
return (self.output_sample_rate, array)
return array
async def shutdown(self) -> None:
if self.session:
self.quit.set()
await self.session.close()
self.quit.clear()
```
|
2) Implement the Gemini audio-video handler
|
https://gradio.app/guides/create-immersive-demo
|
Other Tutorials - Create Immersive Demo Guide
|
We’ll add an optional `gr.Image` input alongside the `WebRTC` component. The handler will access this in `self.latest_args[1]` when sending frames to Gemini.
```python
import gradio as gr
from fastrtc import Stream, WebRTC, get_hf_turn_credentials
stream = Stream(
handler=GeminiHandler(),
modality="audio-video",
mode="send-receive",
server_rtc_configuration=get_hf_turn_credentials(ttl=600*10000),
rtc_configuration=get_hf_turn_credentials(),
additional_inputs=[
gr.Markdown(
"🎨 Art Critic\n\n"
"Provide an image of your artwork or hold it up to the webcam, and Gemini will critique it for you."
"To get a Gemini API key, please visit the [Gemini API Key](https://aistudio.google.com/apikey) page."
"To get an HF Token, please visit the [HF Token](https://huggingface.co/settings/tokens) page."
),
gr.Image(label="Artwork", value="mona_lisa.jpg", type="numpy", sources=["upload", "clipboard"]),
gr.Textbox(label="Gemini API Key", type="password"),
gr.Textbox(label="HF Token", type="password"),
],
ui_args={
"icon": "https://www.gstatic.com/lamda/images/gemini_favicon_f069958c85030456e93de685481c559f160ea06b.png",
"pulse_color": "rgb(255, 255, 255)",
"icon_button_color": "rgb(255, 255, 255)",
"title": "Gemini Audio Video Chat",
},
time_limit=90,
concurrency_limit=5,
)
if __name__ == "__main__":
stream.ui.launch()
```
References
- Gemini Audio Video Chat reference code: [Hugging Face Space](https://huggingface.co/spaces/gradio/gemini-audio-video/blob/main/app.py)
- FastRTC docs: `https://fastrtc.org`
- Audio + video user guide: `https://fastrtc.org/userguide/audio-video/`
- Gradio component integration: `https://fastrtc.org/userguide/gradio/`
- Cookbook (live demos + code): `https://fastrtc.org/cookbook/`
|
3) Setup Stream and Gradio UI
|
https://gradio.app/guides/create-immersive-demo
|
Other Tutorials - Create Immersive Demo Guide
|
Building a dashboard from a public Google Sheet is very easy, thanks to the [`pandas` library](https://pandas.pydata.org/):
1\. Get the URL of the Google Sheets that you want to use. To do this, simply go to the Google Sheets, click on the "Share" button in the top-right corner, and then click on the "Get shareable link" button. This will give you a URL that looks something like this:
```html
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/editgid=0
```
2\. Now, let's modify this URL and then use it to read the data from the Google Sheets into a Pandas DataFrame. (In the code below, replace the `URL` variable with the URL of your public Google Sheet):
```python
import pandas as pd
URL = "https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/editgid=0"
csv_url = URL.replace('/editgid=', '/export?format=csv&gid=')
def get_data():
return pd.read_csv(csv_url)
```
3\. The data query is a function, which means that it's easy to display it real-time using the `gr.DataFrame` component, or plot it real-time using the `gr.LinePlot` component (of course, depending on the data, a different plot may be appropriate). To do this, just pass the function into the respective components, and set the `every` parameter based on how frequently (in seconds) you would like the component to refresh. Here's the Gradio code:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("📈 Real-Time Line Plot")
with gr.Row():
with gr.Column():
gr.DataFrame(get_data, every=gr.Timer(5))
with gr.Column():
gr.LinePlot(get_data, every=gr.Timer(5), x="Date", y="Sales", y_title="Sales ($ millions)", overlay_point=True, width=500, height=500)
demo.queue().launch() Run the demo with queuing enabled
```
And that's it! You have a dashboard that refreshes every 5 seconds, pulling the data from your Google Sheet.
|
Public Google Sheets
|
https://gradio.app/guides/creating-a-realtime-dashboard-from-google-sheets
|
Other Tutorials - Creating A Realtime Dashboard From Google Sheets Guide
|
For private Google Sheets, the process requires a little more work, but not that much! The key difference is that now, you must authenticate yourself to authorize access to the private Google Sheets.
Authentication
To authenticate yourself, obtain credentials from Google Cloud. Here's [how to set up google cloud credentials](https://developers.google.com/workspace/guides/create-credentials):
1\. First, log in to your Google Cloud account and go to the Google Cloud Console (https://console.cloud.google.com/)
2\. In the Cloud Console, click on the hamburger menu in the top-left corner and select "APIs & Services" from the menu. If you do not have an existing project, you will need to create one.
3\. Then, click the "+ Enabled APIs & services" button, which allows you to enable specific services for your project. Search for "Google Sheets API", click on it, and click the "Enable" button. If you see the "Manage" button, then Google Sheets is already enabled, and you're all set.
4\. In the APIs & Services menu, click on the "Credentials" tab and then click on the "Create credentials" button.
5\. In the "Create credentials" dialog, select "Service account key" as the type of credentials to create, and give it a name. **Note down the email of the service account**
6\. After selecting the service account, select the "JSON" key type and then click on the "Create" button. This will download the JSON key file containing your credentials to your computer. It will look something like this:
```json
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}
```
|
Private Google Sheets
|
https://gradio.app/guides/creating-a-realtime-dashboard-from-google-sheets
|
Other Tutorials - Creating A Realtime Dashboard From Google Sheets Guide
|
google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}
```
Querying
Once you have the credentials `.json` file, you can use the following steps to query your Google Sheet:
1\. Click on the "Share" button in the top-right corner of the Google Sheet. Share the Google Sheets with the email address of the service from Step 5 of authentication subsection (this step is important!). Then click on the "Get shareable link" button. This will give you a URL that looks something like this:
```html
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/editgid=0
```
2\. Install the [`gspread` library](https://docs.gspread.org/en/v5.7.0/), which makes it easy to work with the [Google Sheets API](https://developers.google.com/sheets/api/guides/concepts) in Python by running in the terminal: `pip install gspread`
3\. Write a function to load the data from the Google Sheet, like this (replace the `URL` variable with the URL of your private Google Sheet):
```python
import gspread
import pandas as pd
Authenticate with Google and get the sheet
URL = 'https://docs.google.com/spreadsheets/d/1_91Vps76SKOdDQ8cFxZQdgjTJiz23375sAT7vPvaj4k/editgid=0'
gc = gspread.service_account("path/to/key.json")
sh = gc.open_by_url(URL)
worksheet = sh.sheet1
def get_data():
values = worksheet.get_all_values()
df = pd.DataFrame(values[1:], columns=values[0])
return df
```
4\. The data query is a function, which means that it's easy to display it real-time using the `gr.DataFrame` component, or plot it real-time using the `gr.LinePlot` component (of course, depending on the data, a different plot may be appropriate). To do this, we just pass the function into the respective components, and set the `every` parameter based on how frequently (in seconds) we would like the component to refresh. Here's the Gradio cod
|
Private Google Sheets
|
https://gradio.app/guides/creating-a-realtime-dashboard-from-google-sheets
|
Other Tutorials - Creating A Realtime Dashboard From Google Sheets Guide
|
. To do this, we just pass the function into the respective components, and set the `every` parameter based on how frequently (in seconds) we would like the component to refresh. Here's the Gradio code:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("📈 Real-Time Line Plot")
with gr.Row():
with gr.Column():
gr.DataFrame(get_data, every=gr.Timer(5))
with gr.Column():
gr.LinePlot(get_data, every=gr.Timer(5), x="Date", y="Sales", y_title="Sales ($ millions)", overlay_point=True, width=500, height=500)
demo.queue().launch() Run the demo with queuing enabled
```
You now have a Dashboard that refreshes every 5 seconds, pulling the data from your Google Sheet.
|
Private Google Sheets
|
https://gradio.app/guides/creating-a-realtime-dashboard-from-google-sheets
|
Other Tutorials - Creating A Realtime Dashboard From Google Sheets Guide
|
And that's all there is to it! With just a few lines of code, you can use `gradio` and other libraries to read data from a public or private Google Sheet and then display and plot the data in a real-time dashboard.
|
Conclusion
|
https://gradio.app/guides/creating-a-realtime-dashboard-from-google-sheets
|
Other Tutorials - Creating A Realtime Dashboard From Google Sheets Guide
|
Gradio features a built-in theming engine that lets you customize the look and feel of your app. You can choose from a variety of themes, or create your own. To do so, pass the `theme=` kwarg to the `Blocks` or `Interface` constructor. For example:
```python
with gr.Blocks(theme=gr.themes.Soft()) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-soft.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Gradio comes with a set of prebuilt themes which you can load from `gr.themes.*`. These are:
* `gr.themes.Base()` - the `"base"` theme sets the primary color to blue but otherwise has minimal styling, making it particularly useful as a base for creating new, custom themes.
* `gr.themes.Default()` - the `"default"` Gradio 5 theme, with a vibrant orange primary color and gray secondary color.
* `gr.themes.Origin()` - the `"origin"` theme is most similar to Gradio 4 styling. Colors, especially in light mode, are more subdued than the Gradio 5 default theme.
* `gr.themes.Citrus()` - the `"citrus"` theme uses a yellow primary color, highlights form elements that are in focus, and includes fun 3D effects when buttons are clicked.
* `gr.themes.Monochrome()` - the `"monochrome"` theme uses a black primary and white secondary color, and uses serif-style fonts, giving the appearance of a black-and-white newspaper.
* `gr.themes.Soft()` - the `"soft"` theme uses a purple primary color and white secondary color. It also increases the border radius around buttons and form elements and highlights labels.
* `gr.themes.Glass()` - the `"glass"` theme has a blue primary color and a transclucent gray secondary color. The theme also uses vertical gradients to create a glassy effect.
* `gr.themes.Ocean()` - the `"ocean"` theme has a blue-green primary color and gray secondary color. The theme also uses horizontal gradients, especially for buttons and some form elements.
Each of these themes set values for hundreds of CSS variables. You can use preb
|
Introduction
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
lor and gray secondary color. The theme also uses horizontal gradients, especially for buttons and some form elements.
Each of these themes set values for hundreds of CSS variables. You can use prebuilt themes as a starting point for your own custom themes, or you can create your own themes from scratch. Let's take a look at each approach.
|
Introduction
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
The easiest way to build a theme is using the Theme Builder. To launch the Theme Builder locally, run the following code:
```python
import gradio as gr
gr.themes.builder()
```
$demo_theme_builder
You can use the Theme Builder running on Spaces above, though it runs much faster when you launch it locally via `gr.themes.builder()`.
As you edit the values in the Theme Builder, the app will preview updates in real time. You can download the code to generate the theme you've created so you can use it in any Gradio app.
In the rest of the guide, we will cover building themes programmatically.
|
Using the Theme Builder
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
Although each theme has hundreds of CSS variables, the values for most these variables are drawn from 8 core variables which can be set through the constructor of each prebuilt theme. Modifying these 8 arguments allows you to quickly change the look and feel of your app.
Core Colors
The first 3 constructor arguments set the colors of the theme and are `gradio.themes.Color` objects. Internally, these Color objects hold brightness values for the palette of a single hue, ranging from 50, 100, 200..., 800, 900, 950. Other CSS variables are derived from these 3 colors.
The 3 color constructor arguments are:
- `primary_hue`: This is the color draws attention in your theme. In the default theme, this is set to `gradio.themes.colors.orange`.
- `secondary_hue`: This is the color that is used for secondary elements in your theme. In the default theme, this is set to `gradio.themes.colors.blue`.
- `neutral_hue`: This is the color that is used for text and other neutral elements in your theme. In the default theme, this is set to `gradio.themes.colors.gray`.
You could modify these values using their string shortcuts, such as
```python
with gr.Blocks(theme=gr.themes.Default(primary_hue="red", secondary_hue="pink")) as demo:
...
```
or you could use the `Color` objects directly, like this:
```python
with gr.Blocks(theme=gr.themes.Default(primary_hue=gr.themes.colors.red, secondary_hue=gr.themes.colors.pink)) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-1.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Predefined colors are:
- `slate`
- `gray`
- `zinc`
- `neutral`
- `stone`
- `red`
- `orange`
- `amber`
- `yellow`
- `lime`
- `green`
- `emerald`
- `teal`
- `cyan`
- `sky`
- `blue`
- `indigo`
- `violet`
- `purple`
- `fuchsia`
- `pink`
- `rose`
You could also create your own custom `Color` objects and pass them in.
Core Sizing
The next 3 constructor arguments set the sizing of the theme and are `gradio.
|
Extending Themes via the Constructor
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
`
- `fuchsia`
- `pink`
- `rose`
You could also create your own custom `Color` objects and pass them in.
Core Sizing
The next 3 constructor arguments set the sizing of the theme and are `gradio.themes.Size` objects. Internally, these Size objects hold pixel size values that range from `xxs` to `xxl`. Other CSS variables are derived from these 3 sizes.
- `spacing_size`: This sets the padding within and spacing between elements. In the default theme, this is set to `gradio.themes.sizes.spacing_md`.
- `radius_size`: This sets the roundedness of corners of elements. In the default theme, this is set to `gradio.themes.sizes.radius_md`.
- `text_size`: This sets the font size of text. In the default theme, this is set to `gradio.themes.sizes.text_md`.
You could modify these values using their string shortcuts, such as
```python
with gr.Blocks(theme=gr.themes.Default(spacing_size="sm", radius_size="none")) as demo:
...
```
or you could use the `Size` objects directly, like this:
```python
with gr.Blocks(theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size=gr.themes.sizes.radius_none)) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-2.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
The predefined size objects are:
- `radius_none`
- `radius_sm`
- `radius_md`
- `radius_lg`
- `spacing_sm`
- `spacing_md`
- `spacing_lg`
- `text_sm`
- `text_md`
- `text_lg`
You could also create your own custom `Size` objects and pass them in.
Core Fonts
The final 2 constructor arguments set the fonts of the theme. You can pass a list of fonts to each of these arguments to specify fallbacks. If you provide a string, it will be loaded as a system font. If you provide a `gradio.themes.GoogleFont`, the font will be loaded from Google Fonts.
- `font`: This sets the primary font of the theme. In the default theme, this is set to `gradio.themes.GoogleFont("IBM Plex Sans")`.
- `font_mono`: This sets th
|
Extending Themes via the Constructor
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
font will be loaded from Google Fonts.
- `font`: This sets the primary font of the theme. In the default theme, this is set to `gradio.themes.GoogleFont("IBM Plex Sans")`.
- `font_mono`: This sets the monospace font of the theme. In the default theme, this is set to `gradio.themes.GoogleFont("IBM Plex Mono")`.
You could modify these values such as the following:
```python
with gr.Blocks(theme=gr.themes.Default(font=[gr.themes.GoogleFont("Inconsolata"), "Arial", "sans-serif"])) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-3.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
|
Extending Themes via the Constructor
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
You can also modify the values of CSS variables after the theme has been loaded. To do so, use the `.set()` method of the theme object to get access to the CSS variables. For example:
```python
theme = gr.themes.Default(primary_hue="blue").set(
loader_color="FF0000",
slider_color="FF0000",
)
with gr.Blocks(theme=theme) as demo:
...
```
In the example above, we've set the `loader_color` and `slider_color` variables to `FF0000`, despite the overall `primary_color` using the blue color palette. You can set any CSS variable that is defined in the theme in this manner.
Your IDE type hinting should help you navigate these variables. Since there are so many CSS variables, let's take a look at how these variables are named and organized.
CSS Variable Naming Conventions
CSS variable names can get quite long, like `button_primary_background_fill_hover_dark`! However they follow a common naming convention that makes it easy to understand what they do and to find the variable you're looking for. Separated by underscores, the variable name is made up of:
1. The target element, such as `button`, `slider`, or `block`.
2. The target element type or sub-element, such as `button_primary`, or `block_label`.
3. The property, such as `button_primary_background_fill`, or `block_label_border_width`.
4. Any relevant state, such as `button_primary_background_fill_hover`.
5. If the value is different in dark mode, the suffix `_dark`. For example, `input_border_color_focus_dark`.
Of course, many CSS variable names are shorter than this, such as `table_border_color`, or `input_shadow`.
CSS Variable Organization
Though there are hundreds of CSS variables, they do not all have to have individual values. They draw their values by referencing a set of core variables and referencing each other. This allows us to only have to modify a few variables to change the look and feel of the entire theme, while also getting finer control of individual elements that we may wan
|
Extending Themes via `.set()`
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
d referencing each other. This allows us to only have to modify a few variables to change the look and feel of the entire theme, while also getting finer control of individual elements that we may want to modify.
Referencing Core Variables
To reference one of the core constructor variables, precede the variable name with an asterisk. To reference a core color, use the `*primary_`, `*secondary_`, or `*neutral_` prefix, followed by the brightness value. For example:
```python
theme = gr.themes.Default(primary_hue="blue").set(
button_primary_background_fill="*primary_200",
button_primary_background_fill_hover="*primary_300",
)
```
In the example above, we've set the `button_primary_background_fill` and `button_primary_background_fill_hover` variables to `*primary_200` and `*primary_300`. These variables will be set to the 200 and 300 brightness values of the blue primary color palette, respectively.
Similarly, to reference a core size, use the `*spacing_`, `*radius_`, or `*text_` prefix, followed by the size value. For example:
```python
theme = gr.themes.Default(radius_size="md").set(
button_primary_border_radius="*radius_xl",
)
```
In the example above, we've set the `button_primary_border_radius` variable to `*radius_xl`. This variable will be set to the `xl` setting of the medium radius size range.
Referencing Other Variables
Variables can also reference each other. For example, look at the example below:
```python
theme = gr.themes.Default().set(
button_primary_background_fill="FF0000",
button_primary_background_fill_hover="FF0000",
button_primary_border="FF0000",
)
```
Having to set these values to a common color is a bit tedious. Instead, we can reference the `button_primary_background_fill` variable in the `button_primary_background_fill_hover` and `button_primary_border` variables, using a `*` prefix.
```python
theme = gr.themes.Default().set(
button_primary_background_fill="FF0000",
button_primary_back
|
Extending Themes via `.set()`
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
mary_background_fill_hover` and `button_primary_border` variables, using a `*` prefix.
```python
theme = gr.themes.Default().set(
button_primary_background_fill="FF0000",
button_primary_background_fill_hover="*button_primary_background_fill",
button_primary_border="*button_primary_background_fill",
)
```
Now, if we change the `button_primary_background_fill` variable, the `button_primary_background_fill_hover` and `button_primary_border` variables will automatically update as well.
This is particularly useful if you intend to share your theme - it makes it easy to modify the theme without having to change every variable.
Note that dark mode variables automatically reference each other. For example:
```python
theme = gr.themes.Default().set(
button_primary_background_fill="FF0000",
button_primary_background_fill_dark="AAAAAA",
button_primary_border="*button_primary_background_fill",
button_primary_border_dark="*button_primary_background_fill_dark",
)
```
`button_primary_border_dark` will draw its value from `button_primary_background_fill_dark`, because dark mode always draw from the dark version of the variable.
|
Extending Themes via `.set()`
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
Let's say you want to create a theme from scratch! We'll go through it step by step - you can also see the source of prebuilt themes in the gradio source repo for reference - [here's the source](https://github.com/gradio-app/gradio/blob/main/gradio/themes/monochrome.py) for the Monochrome theme.
Our new theme class will inherit from `gradio.themes.Base`, a theme that sets a lot of convenient defaults. Let's make a simple demo that creates a dummy theme called Seafoam, and make a simple app that uses it.
$code_theme_new_step_1
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-1.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
The Base theme is very barebones, and uses `gr.themes.Blue` as it primary color - you'll note the primary button and the loading animation are both blue as a result. Let's change the defaults core arguments of our app. We'll overwrite the constructor and pass new defaults for the core constructor arguments.
We'll use `gr.themes.Emerald` as our primary color, and set secondary and neutral hues to `gr.themes.Blue`. We'll make our text larger using `text_lg`. We'll use `Quicksand` as our default font, loaded from Google Fonts.
$code_theme_new_step_2
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-2.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
See how the primary button and the loading animation are now green? These CSS variables are tied to the `primary_hue` variable.
Let's modify the theme a bit more directly. We'll call the `set()` method to overwrite CSS variable values explicitly. We can use any CSS logic, and reference our core constructor arguments using the `*` prefix.
$code_theme_new_step_3
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-3.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Look how fun our theme looks now! With just a few variable changes, our theme looks completely different.
You may find it helpful to explore the [source code
|
Creating a Full Theme
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
ght"
frameborder="0"
></iframe>
</div>
Look how fun our theme looks now! With just a few variable changes, our theme looks completely different.
You may find it helpful to explore the [source code of the other prebuilt themes](https://github.com/gradio-app/gradio/blob/main/gradio/themes) to see how they modified the base theme. You can also find your browser's Inspector useful to select elements from the UI and see what CSS variables are being used in the styles panel.
|
Creating a Full Theme
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
Once you have created a theme, you can upload it to the HuggingFace Hub to let others view it, use it, and build off of it!
Uploading a Theme
There are two ways to upload a theme, via the theme class instance or the command line. We will cover both of them with the previously created `seafoam` theme.
- Via the class instance
Each theme instance has a method called `push_to_hub` we can use to upload a theme to the HuggingFace hub.
```python
seafoam.push_to_hub(repo_name="seafoam",
version="0.0.1",
hf_token="<token>")
```
- Via the command line
First save the theme to disk
```python
seafoam.dump(filename="seafoam.json")
```
Then use the `upload_theme` command:
```bash
upload_theme\
"seafoam.json"\
"seafoam"\
--version "0.0.1"\
--hf_token "<token>"
```
In order to upload a theme, you must have a HuggingFace account and pass your [Access Token](https://huggingface.co/docs/huggingface_hub/quick-startlogin)
as the `hf_token` argument. However, if you log in via the [HuggingFace command line](https://huggingface.co/docs/huggingface_hub/quick-startlogin) (which comes installed with `gradio`),
you can omit the `hf_token` argument.
The `version` argument lets you specify a valid [semantic version](https://www.geeksforgeeks.org/introduction-semantic-versioning/) string for your theme.
That way your users are able to specify which version of your theme they want to use in their apps. This also lets you publish updates to your theme without worrying
about changing how previously created apps look. The `version` argument is optional. If omitted, the next patch version is automatically applied.
Theme Previews
By calling `push_to_hub` or `upload_theme`, the theme assets will be stored in a [HuggingFace space](https://huggingface.co/docs/hub/spaces-overview).
For example, the theme preview for the calm seafoam theme is here: [calm seafoam preview](https://huggingface.co/spaces/shivalikasingh/calm_seafoam).
<div class="wrapper">
<ifr
|
Sharing Themes
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
hub/spaces-overview).
For example, the theme preview for the calm seafoam theme is here: [calm seafoam preview](https://huggingface.co/spaces/shivalikasingh/calm_seafoam).
<div class="wrapper">
<iframe
src="https://shivalikasingh-calm-seafoam.hf.space/?__theme=light"
frameborder="0"
></iframe>
</div>
Discovering Themes
The [Theme Gallery](https://huggingface.co/spaces/gradio/theme-gallery) shows all the public gradio themes. After publishing your theme,
it will automatically show up in the theme gallery after a couple of minutes.
You can sort the themes by the number of likes on the space and from most to least recently created as well as toggling themes between light and dark mode.
<div class="wrapper">
<iframe
src="https://gradio-theme-gallery.static.hf.space"
frameborder="0"
></iframe>
</div>
Downloading
To use a theme from the hub, use the `from_hub` method on the `ThemeClass` and pass it to your app:
```python
my_theme = gr.Theme.from_hub("gradio/seafoam")
with gr.Blocks(theme=my_theme) as demo:
....
```
You can also pass the theme string directly to `Blocks` or `Interface` (`gr.Blocks(theme="gradio/seafoam")`)
You can pin your app to an upstream theme version by using semantic versioning expressions.
For example, the following would ensure the theme we load from the `seafoam` repo was between versions `0.0.1` and `0.1.0`:
```python
with gr.Blocks(theme="gradio/seafoam@>=0.0.1,<0.1.0") as demo:
....
```
Enjoy creating your own themes! If you make one you're proud of, please share it with the world by uploading it to the hub!
If you tag us on [Twitter](https://twitter.com/gradio) we can give your theme a shout out!
<style>
.wrapper {
position: relative;
padding-bottom: 56.25%;
padding-top: 25px;
height: 0;
}
.wrapper iframe {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
}
</style>
|
Sharing Themes
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
er iframe {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
}
</style>
|
Sharing Themes
|
https://gradio.app/guides/theming-guide
|
Other Tutorials - Theming Guide Guide
|
Tabular data science is the most widely used domain of machine learning, with problems ranging from customer segmentation to churn prediction. Throughout various stages of the tabular data science workflow, communicating your work to stakeholders or clients can be cumbersome; which prevents data scientists from focusing on what matters, such as data analysis and model building. Data scientists can end up spending hours building a dashboard that takes in dataframe and returning plots, or returning a prediction or plot of clusters in a dataset. In this guide, we'll go through how to use `gradio` to improve your data science workflows. We will also talk about how to use `gradio` and [skops](https://skops.readthedocs.io/en/stable/) to build interfaces with only one line of code!
Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started).
|
Introduction
|
https://gradio.app/guides/using-gradio-for-tabular-workflows
|
Other Tutorials - Using Gradio For Tabular Workflows Guide
|
We will take a look at how we can create a simple UI that predicts failures based on product information.
```python
import gradio as gr
import pandas as pd
import joblib
import datasets
inputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(4,"dynamic"), label="Input Data", interactive=1)]
outputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(1, "fixed"), label="Predictions", headers=["Failures"])]
model = joblib.load("model.pkl")
we will give our dataframe as example
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()
def infer(input_dataframe):
return pd.DataFrame(model.predict(input_dataframe))
gr.Interface(fn = infer, inputs = inputs, outputs = outputs, examples = [[df.head(2)]]).launch()
```
Let's break down above code.
- `fn`: the inference function that takes input dataframe and returns predictions.
- `inputs`: the component we take our input with. We define our input as dataframe with 2 rows and 4 columns, which initially will look like an empty dataframe with the aforementioned shape. When the `row_count` is set to `dynamic`, you don't have to rely on the dataset you're inputting to pre-defined component.
- `outputs`: The dataframe component that stores outputs. This UI can take single or multiple samples to infer, and returns 0 or 1 for each sample in one column, so we give `row_count` as 2 and `col_count` as 1 above. `headers` is a list made of header names for dataframe.
- `examples`: You can either pass the input by dragging and dropping a CSV file, or a pandas DataFrame through examples, which headers will be automatically taken by the interface.
We will now create an example for a minimal data visualization dashboard. You can find a more comprehensive version in the related Spaces.
<gradio-app space="gradio/tabular-playground"></gradio-app>
```python
import gradio as gr
import pandas as pd
import datasets
import seaborn as sns
import matplotlib.pyplot as plt
df = datasets.load_dataset
|
Let's Create a Simple Interface!
|
https://gradio.app/guides/using-gradio-for-tabular-workflows
|
Other Tutorials - Using Gradio For Tabular Workflows Guide
|
app space="gradio/tabular-playground"></gradio-app>
```python
import gradio as gr
import pandas as pd
import datasets
import seaborn as sns
import matplotlib.pyplot as plt
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()
df.dropna(axis=0, inplace=True)
def plot(df):
plt.scatter(df.measurement_13, df.measurement_15, c = df.loading,alpha=0.5)
plt.savefig("scatter.png")
df['failure'].value_counts().plot(kind='bar')
plt.savefig("bar.png")
sns.heatmap(df.select_dtypes(include="number").corr())
plt.savefig("corr.png")
plots = ["corr.png","scatter.png", "bar.png"]
return plots
inputs = [gr.Dataframe(label="Supersoaker Production Data")]
outputs = [gr.Gallery(label="Profiling Dashboard", columns=(1,3))]
gr.Interface(plot, inputs=inputs, outputs=outputs, examples=[df.head(100)], title="Supersoaker Failures Analysis Dashboard").launch()
```
<gradio-app space="gradio/gradio-analysis-dashboard-minimal"></gradio-app>
We will use the same dataset we used to train our model, but we will make a dashboard to visualize it this time.
- `fn`: The function that will create plots based on data.
- `inputs`: We use the same `Dataframe` component we used above.
- `outputs`: The `Gallery` component is used to keep our visualizations.
- `examples`: We will have the dataset itself as the example.
|
Let's Create a Simple Interface!
|
https://gradio.app/guides/using-gradio-for-tabular-workflows
|
Other Tutorials - Using Gradio For Tabular Workflows Guide
|
`skops` is a library built on top of `huggingface_hub` and `sklearn`. With the recent `gradio` integration of `skops`, you can build tabular data interfaces with one line of code!
```python
import gradio as gr
title and description are optional
title = "Supersoaker Defective Product Prediction"
description = "This model predicts Supersoaker production line failures. Drag and drop any slice from dataset or edit values as you wish in below dataframe component."
gr.load("huggingface/scikit-learn/tabular-playground", title=title, description=description).launch()
```
<gradio-app space="gradio/gradio-skops-integration"></gradio-app>
`sklearn` models pushed to Hugging Face Hub using `skops` include a `config.json` file that contains an example input with column names, the task being solved (that can either be `tabular-classification` or `tabular-regression`). From the task type, `gradio` constructs the `Interface` and consumes column names and the example input to build it. You can [refer to skops documentation on hosting models on Hub](https://skops.readthedocs.io/en/latest/auto_examples/plot_hf_hub.htmlsphx-glr-auto-examples-plot-hf-hub-py) to learn how to push your models to Hub using `skops`.
|
Easily load tabular data interfaces with one line of code using skops
|
https://gradio.app/guides/using-gradio-for-tabular-workflows
|
Other Tutorials - Using Gradio For Tabular Workflows Guide
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.